SQL Pivot--returning the same values in each pivot entry
WITH DATA
AS (
select CAST(enc_timestamp AS DATE) as [Date of Drug Administration], p.person_nbr AS [Medical Record], enc_nbr AS [Encounter Number],
'OP' as [Patient Type], pp.service_item_id as [Charge Code], pp.service_item_desc AS [Charge Description], pp.units AS [Dispensed Quantity],
pm.payer_name, cob from patient_encounter pe
JOIN person p ON p.person_id = pe.person_id
JOIN encounter_payer ep ON pe.person_id = ep.person_id AND pe.enc_id = ep.enc_id
JOIN payer_mstr pm ON pm.payer_id = pe.cob1_payer_id
JOIN patient_procedure pp ON pp.enc_id = pe.enc_id
where CAST(enc_timestamp AS DATE) >= dateadd(day,datediff(day,365,GETDATE()),0)
and pe.billable_ind = 'Y' and pe.clinical_ind = 'Y' and pe.practice_id = '0001'
and pp.service_item_id IN ( 'J0585','J0696','J0702','J1030','J1040','J1050','J1071','J1100','J1200','J1650','J1885','J2060','J2175','J2270','J2300',
'J2405','J2550','J2791','J2930','J3030','J3301','J3420','J3430','J3490G','J3490TH','J7298','J7613','J7620'
)
and pp.amount <> 0.00 and pp.delete_ind = 'N')
select *
from DATA d
Pivot (MAX(payer_name)
FOR cob IN ([1], [2], [3] )) as P;This is working---however the payer name is the same in 1, 2 or 3 (depending on the patient's number of insurances). For example, if a patient has Medicare and a supplement--it will at least recognize there are two entries (cob 1 and cob 2)--but instead of the supplemental name, it is supplying the same insurance name (Medicare) for both entries. If the patient has 3 insurnaces, then it would have 3 Medicare names across 1, 2 and 3.
ASKER
Sorry Paul, been tied up with other reports--I will get an example of data to you tomorrow
ASKER
Ok tried min--same behavior. It's picking up the first insurance--and then just listing it for every available insurance (if they have multiple). See attached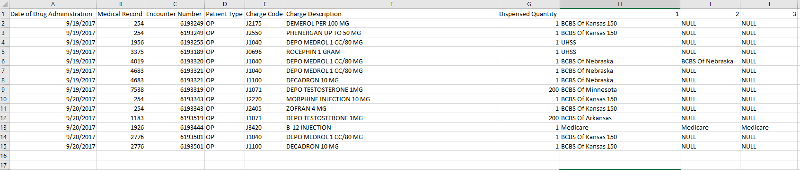
ASKER
Forgot to address your cob question.
COB comes from the encounter_payer table. For example the following query;
Will produce the following;

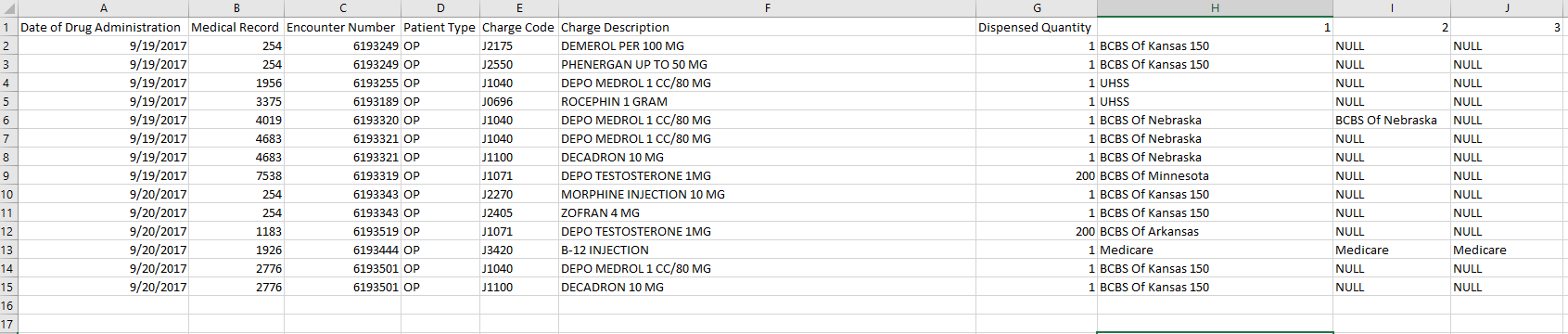
So my original query is recognizing the fact that a particular patient encounter has more than one insurance (multiple rows same encounter, different cob). However, instead of pulling the cob 2 or cob 3 insurance name--it's just populating all cobs it recognizes as existing with the first insurance name. Hope this helps you help me :).
COB comes from the encounter_payer table. For example the following query;
select cob, pm.payer_name, enc_id from encounter_payer ep
JOIN payer_mstr pm ON pm.payer_id = ep.payer_id
order by enc_id, cob ascWill produce the following;
So my original query is recognizing the fact that a particular patient encounter has more than one insurance (multiple rows same encounter, different cob). However, instead of pulling the cob 2 or cob 3 insurance name--it's just populating all cobs it recognizes as existing with the first insurance name. Hope this helps you help me :).
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
That worked, you're an ace Paul!!
If you change to using MIN() do you get a different result?
SELECT
*
FROM data d
PIVOT (
MIN(payer_name) FOR cob IN ([1], [2], [3])
) AS p;
Which table does [cob] come from? (In the "data" query there is no table prefix used for [cob])
Can you provide any sample data? (private info can be altered or omitted)