Cluster failover not working (2 Exch with Dag and witness folder) after move of witness folder to new server. It did work before.
Hello Everyone and thanks in advance for your expert Exchange 2013 tips, insights and advice.
We have two Exchange 2013 servers (running on 2012R2) with a DAG setup in the past by a vendor.
It had a database availability group witness server and witness directory for cluster failover and it worked.
However, I had to put in a new file server and needed to move the witness directory which I thought I did right, but apparently that is not the case.
Note that the Exchange Trusted Subsystem is a member of the local admin group on the new file server.
Some FYI information to help you help me :-)
The errors indicate (from what I can tell) that the witness folder is not available (permissions or something else), but it is created.
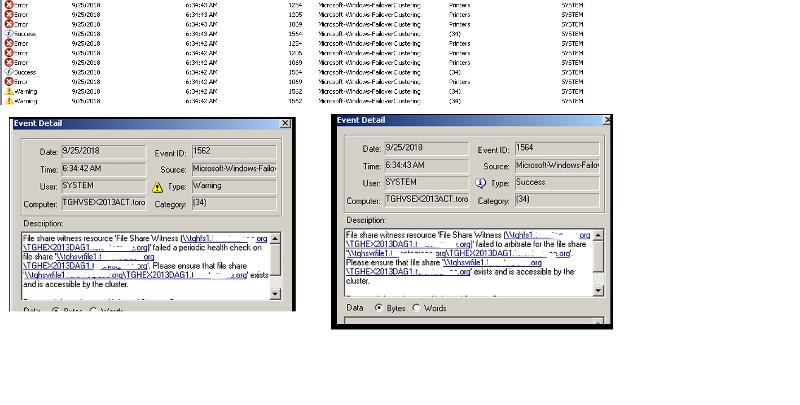 The share is there for sure and the share permission is everyone full control and the ntfs security permission includes all the right groups, servers, dag etc. as far as I can tell as I replicated the previous setup.
The share is there for sure and the share permission is everyone full control and the ntfs security permission includes all the right groups, servers, dag etc. as far as I can tell as I replicated the previous setup.
 The failover cluster has not changed on the server itself and shows both exchange servers as online nodes
The failover cluster has not changed on the server itself and shows both exchange servers as online nodes Command output on the Exchange shows cluster group online, with both Exch member servers part of DAG, shows the witness pointing to right server and share, but the quorumresource file share witness is listing tghfs1 which was the old file server... is that the issue and how do I change that...
Command output on the Exchange shows cluster group online, with both Exch member servers part of DAG, shows the witness pointing to right server and share, but the quorumresource file share witness is listing tghfs1 which was the old file server... is that the issue and how do I change that... 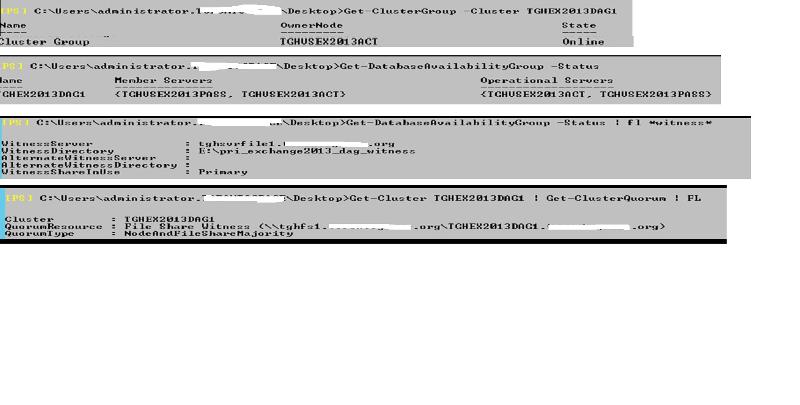 Not good with power shell commands... and if I recall then I did run a command to point it to the new file server tghsvrfile1 and its share... Example: Set-DatabaseAvailabilityGr
Not good with power shell commands... and if I recall then I did run a command to point it to the new file server tghsvrfile1 and its share... Example: Set-DatabaseAvailabilityGr
I also ran some extra commands and the output seems to suggest that the file share witness does indeed point to tghfs1 (even though it is set to point to tghsvrfile1 in the GUI on the exchan admin) and
and  Not sure what is wrong.
Not sure what is wrong.
We have two Exchange 2013 servers (running on 2012R2) with a DAG setup in the past by a vendor.
It had a database availability group witness server and witness directory for cluster failover and it worked.
However, I had to put in a new file server and needed to move the witness directory which I thought I did right, but apparently that is not the case.
Note that the Exchange Trusted Subsystem is a member of the local admin group on the new file server.
Some FYI information to help you help me :-)
The errors indicate (from what I can tell) that the witness folder is not available (permissions or something else), but it is created.
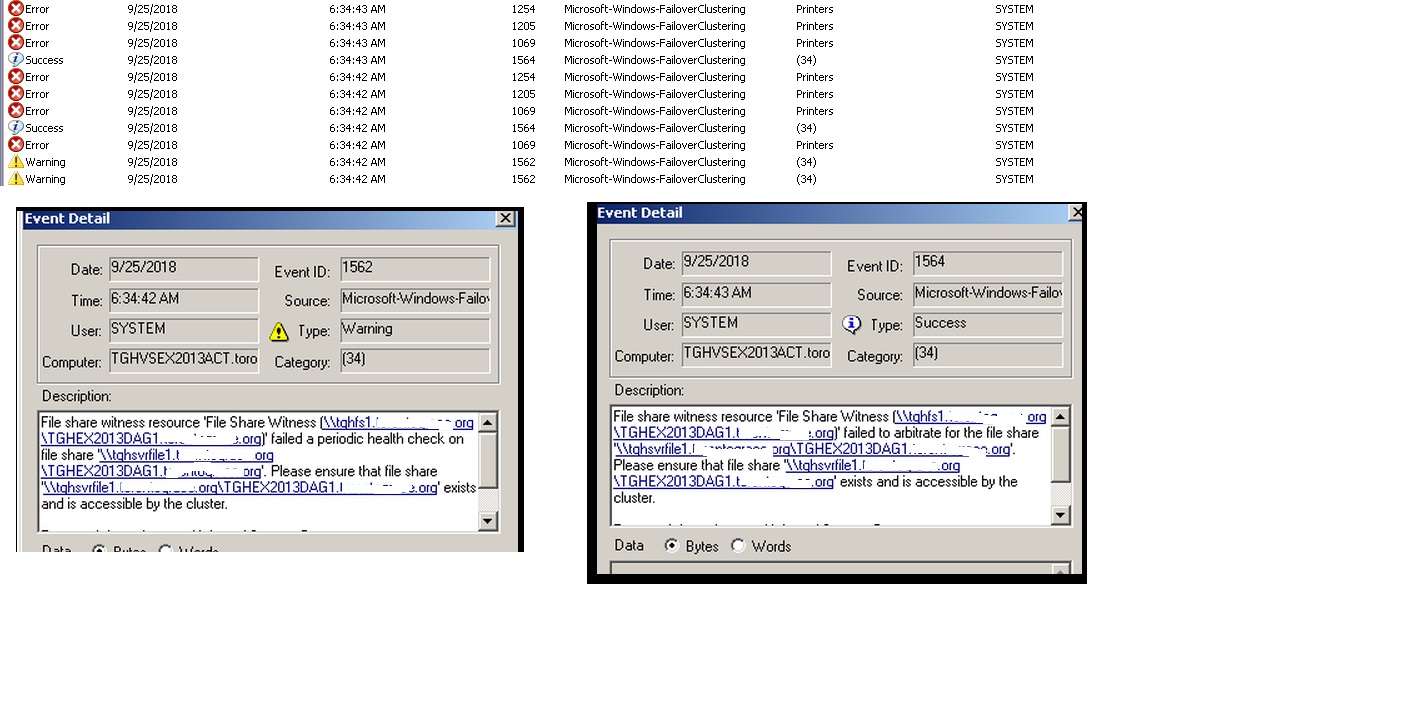 The share is there for sure and the share permission is everyone full control and the ntfs security permission includes all the right groups, servers, dag etc. as far as I can tell as I replicated the previous setup.
The share is there for sure and the share permission is everyone full control and the ntfs security permission includes all the right groups, servers, dag etc. as far as I can tell as I replicated the previous setup. The failover cluster has not changed on the server itself and shows both exchange servers as online nodes
The failover cluster has not changed on the server itself and shows both exchange servers as online nodes Command output on the Exchange shows cluster group online, with both Exch member servers part of DAG, shows the witness pointing to right server and share, but the quorumresource file share witness is listing tghfs1 which was the old file server... is that the issue and how do I change that...
Command output on the Exchange shows cluster group online, with both Exch member servers part of DAG, shows the witness pointing to right server and share, but the quorumresource file share witness is listing tghfs1 which was the old file server... is that the issue and how do I change that... 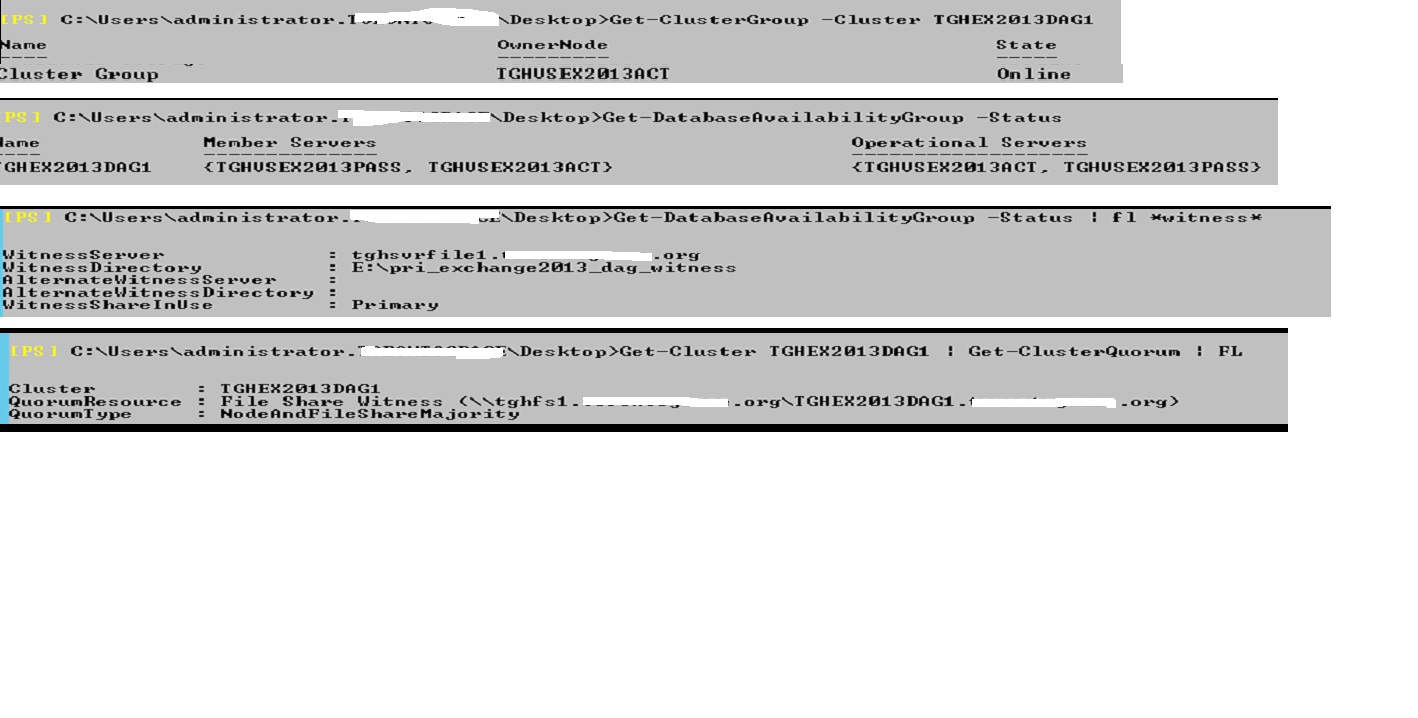 Not good with power shell commands... and if I recall then I did run a command to point it to the new file server tghsvrfile1 and its share... Example: Set-DatabaseAvailabilityGr
Not good with power shell commands... and if I recall then I did run a command to point it to the new file server tghsvrfile1 and its share... Example: Set-DatabaseAvailabilityGrI also ran some extra commands and the output seems to suggest that the file share witness does indeed point to tghfs1 (even though it is set to point to tghsvrfile1 in the GUI on the exchan admin)
 and
and  Not sure what is wrong.
Not sure what is wrong.
ASKER
I did shut down the primary (ACT) server and it did not fail (switch the file server) over hence the errors I saw. I can and will try it again since I have to reboot the server for an unrelated reason. Please look at the errors!
Make sure that the node $ account for both nodes are added has full permission on the file share folder.
Run the command from EMS: get-databaseavailabilitygr
And see if you get any errors.
Run the command from EMS: get-databaseavailabilitygr
And see if you get any errors.
ASKER
both have full permissions on the witness folder (see screenshots below) as well as FC for Exchange trusted subsystem and the DAG
 no errors
no errors
and the cluster passes all tests
I also repointed the cluster to the witness server again and it can see it for sure
when I failed over the exchange (shut one down) this morning it did show as failing over in the ems, but not the exch admin centre... what I mean is that before (when it worked) the active server copies of the databases on the active exchange server would be moved to the passive exchange server and become active there and when the active server became available again I would have to activate the two databases on it to move them back and that part never happened. The Activation Preference Nr are correct (1 = active and 2 = passive).
But the databases (x2) did not move from active to passive as they normally did
no errorsand the cluster passes all tests
I also repointed the cluster to the witness server again and it can see it for sure
when I failed over the exchange (shut one down) this morning it did show as failing over in the ems, but not the exch admin centre... what I mean is that before (when it worked) the active server copies of the databases on the active exchange server would be moved to the passive exchange server and become active there and when the active server became available again I would have to activate the two databases on it to move them back and that part never happened. The Activation Preference Nr are correct (1 = active and 2 = passive).
But the databases (x2) did not move from active to passive as they normally did
ASKER
okay restarted the active exchange again after checking everything again. Below some extra information that I am hoping someone can interpret.
Restart was at 7:00 AM this morning and normal behaviour (when this worked in the past) was for the cluster to failover as seen in EMS from ACT to PASS (which it did) and I expected the two databases to failover from ACT to PASS within Exch Admin Console which they did not. When it worked they used to failover, i.e. the database showed as healthy and mounted on the PASS server (post failover) and I had to activate the ACT copy to move it back once ACT was back up and that was not the case this time. It seemed to remain mounted on ACT throughout.
 Avail Storage showing offline was normal
Avail Storage showing offline was normal
But did not failover in Exch ADmin Con and still mounted on ACT and it should have gone to PASS. Both exchange servers are members of the DAG and have the correct witness folder showing



When rebooting the active exchange server with two databases (clinic and admin) in a cluster with 2 exchange servers (active and passive – tghvsex2013act and tghvsex2013pass). It should failover both databases to passive, but I don’t think it does, because although it shows the passive as the owner of the databases, primaryactivemnagaer, cluster group through EMS it does not failover when looking at it in the Exchange Admin Console and I used to have to move it back on the EMS and then activate the tghvsex2013ACTserver db copies of the clinic and admin db as they were mounted as ‘active’ on the tghvsex2013PASS server and marked as healthy (but not mounted) on the tghvsex2013ACT server and now they seem to remain mounted on the tghvsex2013ACT even after it goes down and comes back up which is not the way it was when it worked . Errors on active TGHVSEX2013ACT below right after reboot initiated at 7:00AM.
Event Viewer Microsoft Exchange High Availability AppLogMirror
Event 1106
AppLogEventID: 4401
AppLogEventMessage:
Microsoft Exchange Server Locator Service failed to find active server for database 'e1ef6f7f-7753-46d3-9768-d
Event 1106
AppLogEventID: 4401
AppLogEventMessage:
Microsoft Exchange Server Locator Service failed to find active server for database '27321f6c-210d-4fe8-89e3-7
Event 1106
AppLogEventID: 4082
AppLogEventMessage:
The replication network manager encountered an error while monitoring events. Error: Microsoft.Exchange.Cluster
--- End of inner exception stack trace ---
at Microsoft.Exchange.Cluster
at Microsoft.Exchange.Cluster
at Microsoft.Exchange.Cluster
Event 1106
AppLogEventID: 4402
AppLogEventMessage:
Microsoft Exchange Server Locator Service failed to find active servers for the database availability group. Error: An Active Manager operation failed. Error: Invalid Active Manager configuration. Error: The Cluster service is not running.
Event Viewer Microsoft Exchange High Availability Monitoring
Event 1011
Health validation check 'DatabaseCheckActiveMountS
Event 1004
Database redundancy health check passed.
Database: ADMINDB01
Redundancy count: 2
Error:
================
Full Copy Status
================
----------------
Database Copy : ADMINDB01\tghvsex2013pass
----------------
WorkerProcessId : 18628
ActivationPreference : 2
CopyStatus : Healthy
Viable : True
ActivationSuspended : False
ErrorEventId : 0
LastStatusTransitionTime : 11/16/2018 12:03:09 PM
StatusRetrievedTime : 11/16/2018 12:03:33 PM
InstanceStartTime : 11/16/2018 1:03:08 AM
LowestLogPresent : 861035
LastLogInspected : 861623
LastLogReplayed : 861623
LastLogCopied : 861623
LastLogCopyNotified : 861623
LastLogGenerated : 861623
LastLogGeneratedTime : 11/16/2018 12:03:33 PM
LastCopyNotifiedLogTime : 11/16/2018 12:03:24 PM
LastInspectedLogTime : 11/16/2018 12:00:57 PM
LastReplayedLogTime : 11/16/2018 12:00:57 PM
LastCopiedLogTime : 11/16/2018 12:00:57 PM
LastLogInfoFromClusterGen : 861623
LastLogInfoFromClusterTime
LastLogInfoFromCopierTime : 11/16/2018 12:03:24 PM
LastLogInfoIsStale : False
ReplayLagEnabled : Disabled
ReplayLagPlayDownReason : None
ReplayLagPercentage : 0
----------------
Database Copy : ADMINDB01\tghvsex2013act
----------------
WorkerProcessId : 6388
ActivationPreference : 1
CopyStatus : Mounting
Viable : False
ActivationSuspended : False
ErrorEventId : 0
LastStatusTransitionTime : 1/1/0001 12:00:00 AM
StatusRetrievedTime : 11/16/2018 12:03:33 PM
InstanceStartTime : 11/16/2018 12:02:50 PM
LowestLogPresent : 861035
LastLogInspected : 0
LastLogReplayed : 0
LastLogCopied : 0
LastLogCopyNotified : 861623
LastLogGenerated : 861623
LastLogGeneratedTime : 1/1/0001 12:00:00 AM
LastCopyNotifiedLogTime : 11/16/2018 12:00:57 PM
LastInspectedLogTime : 1/1/0001 12:00:00 AM
LastReplayedLogTime : 1/1/0001 12:00:00 AM
LastCopiedLogTime : 1/1/0001 12:00:00 AM
LastLogInfoFromClusterGen : 861623
LastLogInfoFromClusterTime
LastLogInfoFromCopierTime : 11/16/2018 12:03:33 PM
LastLogInfoIsStale : False
ReplayLagEnabled : Disabled
ReplayLagPlayDownReason : None
ReplayLagPercentage : 0
Event 806
Database 'ADMINDB01' best copy could not be found.
Event 1018
Database redundancy two-copy health check failed.
Database: ADMINDB01
Redundancy count: 2
Error:
================
Full Copy Status
================
----------------
Database Copy : ADMINDB01\tghvsex2013pass
----------------
WorkerProcessId : 15892
ActivationPreference : 2
CopyStatus : Healthy
Viable : True
ActivationSuspended : False
ErrorEventId : 0
LastStatusTransitionTime : 11/16/2018 12:07:13 PM
StatusRetrievedTime : 11/16/2018 12:08:33 PM
InstanceStartTime : 11/16/2018 12:07:12 PM
LowestLogPresent : 861044
LastLogInspected : 861631
LastLogReplayed : 861631
LastLogCopied : 861631
LastLogCopyNotified : 861631
LastLogGenerated : 861631
LastLogGeneratedTime : 11/16/2018 12:08:33 PM
LastCopyNotifiedLogTime : 11/16/2018 12:06:46 PM
LastInspectedLogTime : 11/16/2018 12:06:46 PM
LastReplayedLogTime : 11/16/2018 12:06:46 PM
LastCopiedLogTime : 11/16/2018 12:06:46 PM
LastLogInfoFromClusterGen : 861631
LastLogInfoFromClusterTime
LastLogInfoFromCopierTime : 11/16/2018 12:07:13 PM
LastLogInfoIsStale : False
ReplayLagEnabled : Disabled
ReplayLagPlayDownReason : None
ReplayLagPercentage : 0
----------------
Database Copy : ADMINDB01\tghvsex2013act
----------------
WorkerProcessId : 9408
ActivationPreference : 1
CopyStatus : Mounted
Viable : False
ActivationSuspended : False
ErrorEventId : 0
LastStatusTransitionTime : 1/1/0001 12:00:00 AM
StatusRetrievedTime : 11/16/2018 12:08:33 PM
InstanceStartTime : 11/16/2018 12:04:48 PM
LowestLogPresent : 861426
LastLogInspected : 0
LastLogReplayed : 0
LastLogCopied : 0
LastLogCopyNotified : 861631
LastLogGenerated : 861631
LastLogGeneratedTime : 1/1/0001 12:00:00 AM
LastCopyNotifiedLogTime : 11/16/2018 12:06:46 PM
LastInspectedLogTime : 1/1/0001 12:00:00 AM
LastReplayedLogTime : 1/1/0001 12:00:00 AM
LastCopiedLogTime : 1/1/0001 12:00:00 AM
LastLogInfoFromClusterGen : 861631
LastLogInfoFromClusterTime
LastLogInfoFromCopierTime : 11/16/2018 12:08:33 PM
LastLogInfoIsStale : False
ReplayLagEnabled : Disabled
ReplayLagPlayDownReason : None
ReplayLagPercentage : 0
Event 1008
Database availability health check passed.
Database: ADMINDB01
Redundancy count: 2
Error:
================
Full Copy Status
================
----------------
Database Copy : ADMINDB01\tghvsex2013pass
----------------
WorkerProcessId : 15892
ActivationPreference : 2
CopyStatus : Healthy
Viable : True
ActivationSuspended : False
ErrorEventId : 0
LastStatusTransitionTime : 11/16/2018 12:07:13 PM
StatusRetrievedTime : 11/16/2018 12:13:33 PM
InstanceStartTime : 11/16/2018 12:07:12 PM
LowestLogPresent : 861472
LastLogInspected : 861690
LastLogReplayed : 861690
LastLogCopied : 861690
LastLogCopyNotified : 861690
LastLogGenerated : 861690
LastLogGeneratedTime : 11/16/2018 12:13:33 PM
LastCopyNotifiedLogTime : 11/16/2018 12:13:11 PM
LastInspectedLogTime : 11/16/2018 12:13:11 PM
LastReplayedLogTime : 11/16/2018 12:13:11 PM
LastCopiedLogTime : 11/16/2018 12:13:11 PM
LastLogInfoFromClusterGen : 861690
LastLogInfoFromClusterTime
LastLogInfoFromCopierTime : 11/16/2018 12:13:11 PM
LastLogInfoIsStale : False
ReplayLagEnabled : Disabled
ReplayLagPlayDownReason : None
ReplayLagPercentage : 0
----------------
Database Copy : ADMINDB01\tghvsex2013act
----------------
WorkerProcessId : 9408
ActivationPreference : 1
CopyStatus : Mounted
Viable : False
ActivationSuspended : False
ErrorEventId : 0
LastStatusTransitionTime : 1/1/0001 12:00:00 AM
StatusRetrievedTime : 11/16/2018 12:13:33 PM
InstanceStartTime : 11/16/2018 12:04:48 PM
LowestLogPresent : 861427
LastLogInspected : 0
LastLogReplayed : 0
LastLogCopied : 0
LastLogCopyNotified : 861690
LastLogGenerated : 861690
LastLogGeneratedTime : 1/1/0001 12:00:00 AM
LastCopyNotifiedLogTime : 11/16/2018 12:13:11 PM
LastInspectedLogTime : 1/1/0001 12:00:00 AM
LastReplayedLogTime : 1/1/0001 12:00:00 AM
LastCopiedLogTime : 1/1/0001 12:00:00 AM
LastLogInfoFromClusterGen : 861690
LastLogInfoFromClusterTime
LastLogInfoFromCopierTime : 11/16/2018 12:13:33 PM
LastLogInfoIsStale : False
ReplayLagEnabled : Disabled
ReplayLagPlayDownReason : None
ReplayLagPercentage : 0
Event Viewer Microsoft Exchange High Availability Operational
Event 127
Forcefully dismounting all the locally mounted databases on server 'TGHVSEX2013ACT.torontogra
Event 260
Initiating Store Rpc to dismount database '27321f6c-210d-4fe8-89e3-7
Event 261
Finshed dismount Store Rpc for database 'e1ef6f7f-7753-46d3-9768-d
Event 262
Finished force dismounting all locally mounted databases. (IsSuccess=True)
Event 252
Failure item processing detected an inconsistent event record (Database=ADMINDB01, IsEventPresent=False, Exception=System.Operation
at System.Diagnostics.Eventin
at System.Diagnostics.Eventin
at System.Diagnostics.Eventin
Event 1232
Initiating cluster database updates from local nodes in stead of Primary Active Manager (LastServerUpdateTimeAsPer
Event 337
Mount for database 'ADMINDB01' finished. (Duration StoreMount=00:02:21.227556
Restart was at 7:00 AM this morning and normal behaviour (when this worked in the past) was for the cluster to failover as seen in EMS from ACT to PASS (which it did) and I expected the two databases to failover from ACT to PASS within Exch Admin Console which they did not. When it worked they used to failover, i.e. the database showed as healthy and mounted on the PASS server (post failover) and I had to activate the ACT copy to move it back once ACT was back up and that was not the case this time. It seemed to remain mounted on ACT throughout.
 Avail Storage showing offline was normal
Avail Storage showing offline was normalBut did not failover in Exch ADmin Con and still mounted on ACT and it should have gone to PASS. Both exchange servers are members of the DAG and have the correct witness folder showing



When rebooting the active exchange server with two databases (clinic and admin) in a cluster with 2 exchange servers (active and passive – tghvsex2013act and tghvsex2013pass). It should failover both databases to passive, but I don’t think it does, because although it shows the passive as the owner of the databases, primaryactivemnagaer, cluster group through EMS it does not failover when looking at it in the Exchange Admin Console and I used to have to move it back on the EMS and then activate the tghvsex2013ACTserver db copies of the clinic and admin db as they were mounted as ‘active’ on the tghvsex2013PASS server and marked as healthy (but not mounted) on the tghvsex2013ACT server and now they seem to remain mounted on the tghvsex2013ACT even after it goes down and comes back up which is not the way it was when it worked . Errors on active TGHVSEX2013ACT below right after reboot initiated at 7:00AM.
Event Viewer Microsoft Exchange High Availability AppLogMirror
Event 1106
AppLogEventID: 4401
AppLogEventMessage:
Microsoft Exchange Server Locator Service failed to find active server for database 'e1ef6f7f-7753-46d3-9768-d
Event 1106
AppLogEventID: 4401
AppLogEventMessage:
Microsoft Exchange Server Locator Service failed to find active server for database '27321f6c-210d-4fe8-89e3-7
Event 1106
AppLogEventID: 4082
AppLogEventMessage:
The replication network manager encountered an error while monitoring events. Error: Microsoft.Exchange.Cluster
--- End of inner exception stack trace ---
at Microsoft.Exchange.Cluster
at Microsoft.Exchange.Cluster
at Microsoft.Exchange.Cluster
Event 1106
AppLogEventID: 4402
AppLogEventMessage:
Microsoft Exchange Server Locator Service failed to find active servers for the database availability group. Error: An Active Manager operation failed. Error: Invalid Active Manager configuration. Error: The Cluster service is not running.
Event Viewer Microsoft Exchange High Availability Monitoring
Event 1011
Health validation check 'DatabaseCheckActiveMountS
Event 1004
Database redundancy health check passed.
Database: ADMINDB01
Redundancy count: 2
Error:
================
Full Copy Status
================
----------------
Database Copy : ADMINDB01\tghvsex2013pass
----------------
WorkerProcessId : 18628
ActivationPreference : 2
CopyStatus : Healthy
Viable : True
ActivationSuspended : False
ErrorEventId : 0
LastStatusTransitionTime : 11/16/2018 12:03:09 PM
StatusRetrievedTime : 11/16/2018 12:03:33 PM
InstanceStartTime : 11/16/2018 1:03:08 AM
LowestLogPresent : 861035
LastLogInspected : 861623
LastLogReplayed : 861623
LastLogCopied : 861623
LastLogCopyNotified : 861623
LastLogGenerated : 861623
LastLogGeneratedTime : 11/16/2018 12:03:33 PM
LastCopyNotifiedLogTime : 11/16/2018 12:03:24 PM
LastInspectedLogTime : 11/16/2018 12:00:57 PM
LastReplayedLogTime : 11/16/2018 12:00:57 PM
LastCopiedLogTime : 11/16/2018 12:00:57 PM
LastLogInfoFromClusterGen : 861623
LastLogInfoFromClusterTime
LastLogInfoFromCopierTime : 11/16/2018 12:03:24 PM
LastLogInfoIsStale : False
ReplayLagEnabled : Disabled
ReplayLagPlayDownReason : None
ReplayLagPercentage : 0
----------------
Database Copy : ADMINDB01\tghvsex2013act
----------------
WorkerProcessId : 6388
ActivationPreference : 1
CopyStatus : Mounting
Viable : False
ActivationSuspended : False
ErrorEventId : 0
LastStatusTransitionTime : 1/1/0001 12:00:00 AM
StatusRetrievedTime : 11/16/2018 12:03:33 PM
InstanceStartTime : 11/16/2018 12:02:50 PM
LowestLogPresent : 861035
LastLogInspected : 0
LastLogReplayed : 0
LastLogCopied : 0
LastLogCopyNotified : 861623
LastLogGenerated : 861623
LastLogGeneratedTime : 1/1/0001 12:00:00 AM
LastCopyNotifiedLogTime : 11/16/2018 12:00:57 PM
LastInspectedLogTime : 1/1/0001 12:00:00 AM
LastReplayedLogTime : 1/1/0001 12:00:00 AM
LastCopiedLogTime : 1/1/0001 12:00:00 AM
LastLogInfoFromClusterGen : 861623
LastLogInfoFromClusterTime
LastLogInfoFromCopierTime : 11/16/2018 12:03:33 PM
LastLogInfoIsStale : False
ReplayLagEnabled : Disabled
ReplayLagPlayDownReason : None
ReplayLagPercentage : 0
Event 806
Database 'ADMINDB01' best copy could not be found.
Event 1018
Database redundancy two-copy health check failed.
Database: ADMINDB01
Redundancy count: 2
Error:
================
Full Copy Status
================
----------------
Database Copy : ADMINDB01\tghvsex2013pass
----------------
WorkerProcessId : 15892
ActivationPreference : 2
CopyStatus : Healthy
Viable : True
ActivationSuspended : False
ErrorEventId : 0
LastStatusTransitionTime : 11/16/2018 12:07:13 PM
StatusRetrievedTime : 11/16/2018 12:08:33 PM
InstanceStartTime : 11/16/2018 12:07:12 PM
LowestLogPresent : 861044
LastLogInspected : 861631
LastLogReplayed : 861631
LastLogCopied : 861631
LastLogCopyNotified : 861631
LastLogGenerated : 861631
LastLogGeneratedTime : 11/16/2018 12:08:33 PM
LastCopyNotifiedLogTime : 11/16/2018 12:06:46 PM
LastInspectedLogTime : 11/16/2018 12:06:46 PM
LastReplayedLogTime : 11/16/2018 12:06:46 PM
LastCopiedLogTime : 11/16/2018 12:06:46 PM
LastLogInfoFromClusterGen : 861631
LastLogInfoFromClusterTime
LastLogInfoFromCopierTime : 11/16/2018 12:07:13 PM
LastLogInfoIsStale : False
ReplayLagEnabled : Disabled
ReplayLagPlayDownReason : None
ReplayLagPercentage : 0
----------------
Database Copy : ADMINDB01\tghvsex2013act
----------------
WorkerProcessId : 9408
ActivationPreference : 1
CopyStatus : Mounted
Viable : False
ActivationSuspended : False
ErrorEventId : 0
LastStatusTransitionTime : 1/1/0001 12:00:00 AM
StatusRetrievedTime : 11/16/2018 12:08:33 PM
InstanceStartTime : 11/16/2018 12:04:48 PM
LowestLogPresent : 861426
LastLogInspected : 0
LastLogReplayed : 0
LastLogCopied : 0
LastLogCopyNotified : 861631
LastLogGenerated : 861631
LastLogGeneratedTime : 1/1/0001 12:00:00 AM
LastCopyNotifiedLogTime : 11/16/2018 12:06:46 PM
LastInspectedLogTime : 1/1/0001 12:00:00 AM
LastReplayedLogTime : 1/1/0001 12:00:00 AM
LastCopiedLogTime : 1/1/0001 12:00:00 AM
LastLogInfoFromClusterGen : 861631
LastLogInfoFromClusterTime
LastLogInfoFromCopierTime : 11/16/2018 12:08:33 PM
LastLogInfoIsStale : False
ReplayLagEnabled : Disabled
ReplayLagPlayDownReason : None
ReplayLagPercentage : 0
Event 1008
Database availability health check passed.
Database: ADMINDB01
Redundancy count: 2
Error:
================
Full Copy Status
================
----------------
Database Copy : ADMINDB01\tghvsex2013pass
----------------
WorkerProcessId : 15892
ActivationPreference : 2
CopyStatus : Healthy
Viable : True
ActivationSuspended : False
ErrorEventId : 0
LastStatusTransitionTime : 11/16/2018 12:07:13 PM
StatusRetrievedTime : 11/16/2018 12:13:33 PM
InstanceStartTime : 11/16/2018 12:07:12 PM
LowestLogPresent : 861472
LastLogInspected : 861690
LastLogReplayed : 861690
LastLogCopied : 861690
LastLogCopyNotified : 861690
LastLogGenerated : 861690
LastLogGeneratedTime : 11/16/2018 12:13:33 PM
LastCopyNotifiedLogTime : 11/16/2018 12:13:11 PM
LastInspectedLogTime : 11/16/2018 12:13:11 PM
LastReplayedLogTime : 11/16/2018 12:13:11 PM
LastCopiedLogTime : 11/16/2018 12:13:11 PM
LastLogInfoFromClusterGen : 861690
LastLogInfoFromClusterTime
LastLogInfoFromCopierTime : 11/16/2018 12:13:11 PM
LastLogInfoIsStale : False
ReplayLagEnabled : Disabled
ReplayLagPlayDownReason : None
ReplayLagPercentage : 0
----------------
Database Copy : ADMINDB01\tghvsex2013act
----------------
WorkerProcessId : 9408
ActivationPreference : 1
CopyStatus : Mounted
Viable : False
ActivationSuspended : False
ErrorEventId : 0
LastStatusTransitionTime : 1/1/0001 12:00:00 AM
StatusRetrievedTime : 11/16/2018 12:13:33 PM
InstanceStartTime : 11/16/2018 12:04:48 PM
LowestLogPresent : 861427
LastLogInspected : 0
LastLogReplayed : 0
LastLogCopied : 0
LastLogCopyNotified : 861690
LastLogGenerated : 861690
LastLogGeneratedTime : 1/1/0001 12:00:00 AM
LastCopyNotifiedLogTime : 11/16/2018 12:13:11 PM
LastInspectedLogTime : 1/1/0001 12:00:00 AM
LastReplayedLogTime : 1/1/0001 12:00:00 AM
LastCopiedLogTime : 1/1/0001 12:00:00 AM
LastLogInfoFromClusterGen : 861690
LastLogInfoFromClusterTime
LastLogInfoFromCopierTime : 11/16/2018 12:13:33 PM
LastLogInfoIsStale : False
ReplayLagEnabled : Disabled
ReplayLagPlayDownReason : None
ReplayLagPercentage : 0
Event Viewer Microsoft Exchange High Availability Operational
Event 127
Forcefully dismounting all the locally mounted databases on server 'TGHVSEX2013ACT.torontogra
Event 260
Initiating Store Rpc to dismount database '27321f6c-210d-4fe8-89e3-7
Event 261
Finshed dismount Store Rpc for database 'e1ef6f7f-7753-46d3-9768-d
Event 262
Finished force dismounting all locally mounted databases. (IsSuccess=True)
Event 252
Failure item processing detected an inconsistent event record (Database=ADMINDB01, IsEventPresent=False, Exception=System.Operation
at System.Diagnostics.Eventin
at System.Diagnostics.Eventin
at System.Diagnostics.Eventin
Event 1232
Initiating cluster database updates from local nodes in stead of Primary Active Manager (LastServerUpdateTimeAsPer
Event 337
Mount for database 'ADMINDB01' finished. (Duration StoreMount=00:02:21.227556
ASKER
I manager to test manual failover and it works fine so something that automatic needs is the issue. Thinking perhaps witness folder, though it seems okay. Can I just delete the share and make a new one with new witness folder??
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
The witness server will not switch to new one until and unless there is a failover or 1 node goes down and only one node remains. Since both the nodes are up and running they form a cluster.
You do not need to do anything with regards to witness server, since if you have already changed to a new witness server this change has taken place but will not reflect and will reflect on its own when there is a failover or one nodes goes down.
Try to shutdown one server during non-business hrs. and see what cluster does with regards to having only one node up and new witness server.