Need advice on using Powershell Write-SQLTABLEDATA
I just discovered the SQLSERVER Module for Powershell and would like to use the.
From my initial testing of small directory structures it works well. My fear is that the system will not be able to hold all the data before writing to the SQL server. Is there a way to chunk this up or make it more efficient?
Here is what I am doing to help or not:
get-ChildItem2 -Path w:\ -File -Recurse | Select DirectoryName,Name,CreationTime,LastWriteTime,LastAccessTime,Extension,Length,Mode | Write-SqlTableData -ServerInstance 'sandboxhost' -DatabaseName 'NETAPP_INVENTORY' -SchemaName dbo -TableName 'files' -forceFrom my initial testing of small directory structures it works well. My fear is that the system will not be able to hold all the data before writing to the SQL server. Is there a way to chunk this up or make it more efficient?
Here is what I am doing to help or not:
$Dir = 'W:\'
$DirLists = (Get-ChildItem2 -path $dir -Directory).FullName
Foreach ($dirlist in $DirLists)
{
Write-Host (Get-Date)
Write-Host $dirlist
get-ChildItem2 -Path $dirlist -File -Recurse | Select DirectoryName,Name,CreationTime,LastWriteTime,LastAccessTime,Extension,Length,Mode | Write-SqlTableData -ServerInstance 'sandboxhost' -DatabaseName 'NETAPP_INVENTORY' -SchemaName dbo -TableName 'DUMP' -force
Write-Host
}ASKER
Is my method a bad practice?
Well, what you want is just a way to stop it to get the info about it ... what you can do is to transform the 2 calls into a function.
Why would you think that would be a bad practice?
$chunkMax = 1000
$sleepseconds =5
$i = 1;
$Dir = 'W:\'
$DirLists = (Get-ChildItem2 -path $dir -Directory).FullName
function Writeto-SQL{
[CmdletBinding()]
param(
[Param(mandatory=$true,position=0)]$TheDirList,
[Param(mandatory=$false,position=1)]$ServerInstance='sandboxhost',
[Param(mandatory=$false,position=2)]$Database = 'NETAPP_INVENTORY',
[Param(mandatory=$false,position=3)]$Table = 'DUMP',
[Param(mandatory=$false,position=4)]$Schema = 'dbo'
)
begin{
Write-Host -ForegroundColor Green $(Get-Date) -NoNewline
Write-Host -ForegroundColor White "$($TheDirList) \n"
}
process{
try{
get-ChildItem2 -Path $TheDirList -File -Recurse | Select DirectoryName,Name,CreationTime,LastWriteTime,LastAccessTime,Extension,Length,Mode | Write-SqlTableData -ServerInstance $ServerInstance -DatabaseName $Database -SchemaName $Schema -TableName $Table -force
Write-Host
}
catch{
Write-Warning $($_.Exception.Message)
}
}
}
Foreach ($dirlist in $DirLists){
$i++
if($i -lt $chunkMax){
Writeto-SQL -TheDirList $dirlist
}
else{
$i=1 #reset i
Start-Sleep -Seconds $sleepseconds
Writeto-SQL -TheDirList $dirlist
}
}Why would you think that would be a bad practice?
ASKER
The reason I asked if my method was bad because I am not sure if I was overloading the process and had it slow down.
I am seeing a rate of 50 entries per/sec being written to the table. With my method.
I am fine with the simpler of the methods as long as I am not slowing the process down.
I am seeing a rate of 50 entries per/sec being written to the table. With my method.
I am fine with the simpler of the methods as long as I am not slowing the process down.
Your very first script should do the job just fine, assuming you see data arrive in the table pretty much immediately after you start the command.
You might want to use Task Manager to check if the memory usage of the PowerShell process running the command, but that should flatten out pretty much immediately.
That's the big advantage of the pipeline if properly implemented and used: you only have one object per stage in memory at the same time.
1. Get-ChildItem reads an item, and passes it down the pipeline to Select-Object.
2. Select-Object changes the properties of the first item, and passes it down the pipeline to Write-SqlTableData; at the same time, Get-ChildItem reads the second item.
3. Write-SqlTableData puts the first item into the table, while Get-ChildItem reads the third item, and Select-Object changes the properties of the second item.
Lather, rinse, repeat - only three objects in memory at any one time (plus the management stuff, obviously).
So the way you did it is exactly how you should do it in PowerShell.
It's not necessarily the fastest method, but saves on resources and script complexity ...
Just don't put a Sort-Object into the pipeline - for sorting, the cmdlet will obviously need to collect everything first, which will probably make your RAM explode or so.
You might want to use Task Manager to check if the memory usage of the PowerShell process running the command, but that should flatten out pretty much immediately.
That's the big advantage of the pipeline if properly implemented and used: you only have one object per stage in memory at the same time.
1. Get-ChildItem reads an item, and passes it down the pipeline to Select-Object.
2. Select-Object changes the properties of the first item, and passes it down the pipeline to Write-SqlTableData; at the same time, Get-ChildItem reads the second item.
3. Write-SqlTableData puts the first item into the table, while Get-ChildItem reads the third item, and Select-Object changes the properties of the second item.
Lather, rinse, repeat - only three objects in memory at any one time (plus the management stuff, obviously).
So the way you did it is exactly how you should do it in PowerShell.
It's not necessarily the fastest method, but saves on resources and script complexity ...
Just don't put a Sort-Object into the pipeline - for sorting, the cmdlet will obviously need to collect everything first, which will probably make your RAM explode or so.
ASKER
@oBdA
Thanks for that feedback. As you stated I did see the memory jump a few and flat line after that. The data is showing up in real time which is good as well. The DB has about 10 million rows in this table so far add that is about 10% completed. This DB is around 2.8 GB is size at the moment and still growing. Some of the directory paths are greater than 260 characters and that is why I am using Get-Childitem2 (NTFS module) to gather this information.
The one thing that I not able to figure out is being that there are 10 million records and there is millions of duplicated data. I would like to capture that initial directory path, store it and compare it to the next Childitem directory and so on. When it finds a new path I would like to write it to another table with a GUID (NEWID()) and make that a PK between the two tables to maybe reduce the size of the DB and maybe write faster to the DB.
Thanks for that feedback. As you stated I did see the memory jump a few and flat line after that. The data is showing up in real time which is good as well. The DB has about 10 million rows in this table so far add that is about 10% completed. This DB is around 2.8 GB is size at the moment and still growing. Some of the directory paths are greater than 260 characters and that is why I am using Get-Childitem2 (NTFS module) to gather this information.
The one thing that I not able to figure out is being that there are 10 million records and there is millions of duplicated data. I would like to capture that initial directory path, store it and compare it to the next Childitem directory and so on. When it finds a new path I would like to write it to another table with a GUID (NEWID()) and make that a PK between the two tables to maybe reduce the size of the DB and maybe write faster to the DB.
ASKER
Another question.
by me adding the
It seems to be take an extremely long time.
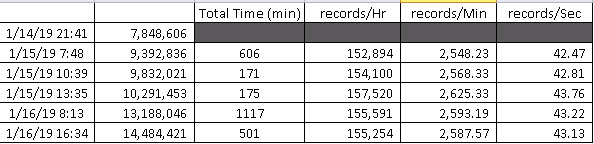
by me adding the
| Select DirectoryName,Name,CreationTime,LastWriteTime,LastAccessTimeIt seems to be take an extremely long time.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
So the dB is local to the server I am running the ps script on. The disk are 10k raid 5 setup.
Should be enough horsepower.
Most likely it's the default dB setup with auto grow.
Should be enough horsepower.
Most likely it's the default dB setup with auto grow.
ASKER
In addition to the above information the Avg Disk Queue Length .50. From what I know anything under 1 is good.
Also I am running the Get-Childitem2 against network share.
I read that using .NET [System.IO.Directory]::Get
Also I am running the Get-Childitem2 against network share.
I read that using .NET [System.IO.Directory]::Get
ASKER
I am running this now from a Windows 10 machine rather than a Server 2008 R2.
I figure that the Windows 10 will lift the 260 MAX_PATH limitation.
The measure test against 20 Million files was 1 hr 47 Min. Now I am testing with export to CSV vs WRITE-SQLDATATABLE
Results are as followed:
19007 total records
EXPORT-CSV: 12.21 Seconds
Days : 0
Hours : 0
Minutes : 0
Seconds : 12
Milliseconds : 210
Ticks : 122101416
TotalDays : 0.000141321083333333
TotalHours : 0.003391706
TotalMinutes : 0.20350236
TotalSeconds : 12.2101416
TotalMilliseconds : 12210.1416
Write-SQLTABLEDATA: 177.7sec
Days : 0
Hours : 0
Minutes : 2
Seconds : 57
Milliseconds : 709
Ticks : 1777099048
TotalDays : 0.00205682760185185
TotalHours : 0.0493638624444444
TotalMinutes : 2.96183174666667
TotalSeconds : 177.7099048
TotalMilliseconds : 177709.9048
I figure that the Windows 10 will lift the 260 MAX_PATH limitation.
The measure test against 20 Million files was 1 hr 47 Min. Now I am testing with export to CSV vs WRITE-SQLDATATABLE
Results are as followed:
19007 total records
EXPORT-CSV: 12.21 Seconds
Measure-Command{Get-ChildItem -Path $dir -Depth 2 -Recurse | select Name,Extension,Length,CreationTime,LastAccessTime,LastWriteTime | Export-Csv -Path C:\temp\dump3.csv -NoTypeInformation -Force}Days : 0
Hours : 0
Minutes : 0
Seconds : 12
Milliseconds : 210
Ticks : 122101416
TotalDays : 0.000141321083333333
TotalHours : 0.003391706
TotalMinutes : 0.20350236
TotalSeconds : 12.2101416
TotalMilliseconds : 12210.1416
Write-SQLTABLEDATA: 177.7sec
Measure-Command{Get-ChildItem -Path $dir -Depth 2 -Recurse | select Name,Extension,Length,CreationTime,LastAccessTime,LastWriteTime | Write-SqlTableData -ServerInstance 'localhost' -DatabaseName 'FileAudit' -SchemaName dbo -TableName 'DUMP' -force}Days : 0
Hours : 0
Minutes : 2
Seconds : 57
Milliseconds : 709
Ticks : 1777099048
TotalDays : 0.00205682760185185
TotalHours : 0.0493638624444444
TotalMinutes : 2.96183174666667
TotalSeconds : 177.7099048
TotalMilliseconds : 177709.9048
ASKER
I tried another test:
export-csv 4 Min 47 Sec for 284962 rows
Days : 0
Hours : 0
Minutes : 4
Seconds : 47
Milliseconds : 765
Ticks : 2877653353
TotalDays : 0.00333061730671296
TotalHours : 0.0799348153611111
TotalMinutes : 4.79608892166667
TotalSeconds : 287.7653353
TotalMilliseconds : 287765.3353
Write-SQLDATATABLE
Avg 72 rows per sec, 4275 per min with an estimated time of 63 mins to computer 15X longer. It has not completed yet
export-csv 4 Min 47 Sec for 284962 rows
Measure-Command{
$dump = Get-ChildItem -Path $dir -Recurse -file| select directory,Name,Extension,Length,CreationTime,LastAccessTime,LastWriteTime
$dump | Export-Csv -Path C:\temp\dump3.csv -NoTypeInformation -Force}Days : 0
Hours : 0
Minutes : 4
Seconds : 47
Milliseconds : 765
Ticks : 2877653353
TotalDays : 0.00333061730671296
TotalHours : 0.0799348153611111
TotalMinutes : 4.79608892166667
TotalSeconds : 287.7653353
TotalMilliseconds : 287765.3353
Write-SQLDATATABLE
Avg 72 rows per sec, 4275 per min with an estimated time of 63 mins to computer 15X longer. It has not completed yet
Measure-Object{$dump = Get-ChildItem -Path $dir -Recurse -file| select directoryname,Name,Extension,Length,CreationTime,LastAccessTime,LastWriteTime
$dump | Write-SqlTableData -ServerInstance 'localhost' -DatabaseName 'FileAudit' -SchemaName dbo -TableName 'DUMP' -Force}ASKER
I found another SQL module called DBATOOLS and It is so much faster. It seems to do bulk inserting rather than row by row. I am getting times near EXPORT-CSV (7 Mins rather than 1 hr.
Does SQLSERVER module have bulk insert?
Does SQLSERVER module have bulk insert?
Can't tell, sorry; I'm using my own function for SQL queries that uses the SQL functions included in .NET, so that they work on any Windows client.
ASKER
I ended up replacing SQLSERVER Module with DBATOOLS module on a Windows 10 machine using the Get-Chliditem. I did learn something with Measure-command in combo with other measure cmdlets.
I am seeing 986 records a second being processed.
I am seeing 986 records a second being processed.
Import-Module DBATOOLS
$SQLSERVER = 'localhost'
$sqlInstance = ''
$database = 'FileAudit'
$Table = 'files'
$Dir = '\\Fileserver\Share1'
$List = (Get-ChildItem -Path $Dir -Directory).FullName
Foreach ($dir in $List)
{
Get-Date
$dir
$timespan = Measure-Command{Get-ChildItem -Path $dir -Recurse -file |select directoryname,Name,Extension,Length,CreationTime,LastAccessTime,LastWriteTime | Write-DbaDataTable -SqlInstance 'localhost' -Database 'fileaudit' -Schema 'dbo' -Table 'dump' }
$timespan.TotalSeconds
Write-Host
}ASKER
Thank you both for guidance and input.
ASKER
Follow up:
I accidentally stumbled upon this. When running my script If I go one level deeper (i.e. '\\Fileserver\Share1\Sub1'
I accidentally stumbled upon this. When running my script If I go one level deeper (i.e. '\\Fileserver\Share1\Sub1'
ASKER
Follow up to this question:
So the data importing turned out to be 114337661 records.
So the data importing turned out to be 114337661 records.
Open in new window