CAMPzxzxDeathzxzx
asked on
I need to add a SQL unique constraint across multiple tables
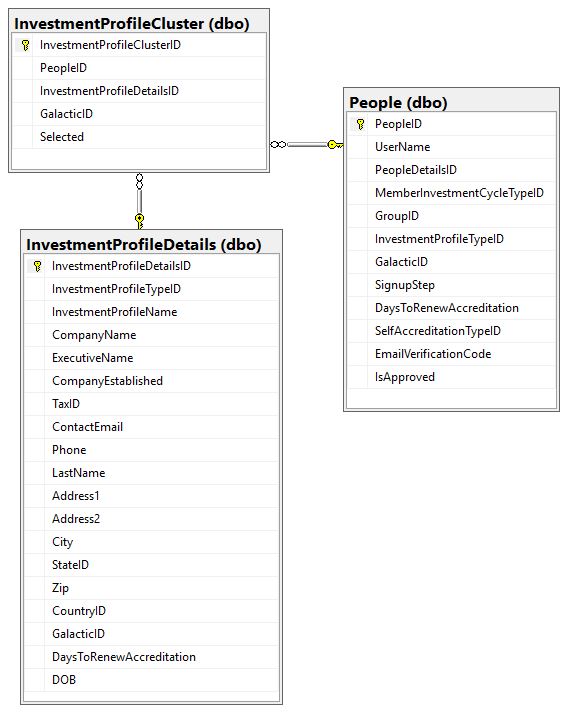
I need to add a unique constraint across multiple tables. I need [InvestmentProfileName] to be unique when paired with the [PeopleID]
ste5an
hmm, first thing I see: There is a profile cluster entity and a profile detail entity. But where is the profile entity?
ASKER
The profile detail table is the profile table
It seems you don't need relation between People and InvestmentProfileCluster.
Each PeopleID has one InvestmentProfileDetails and then you may create clusters where each PeopleID/InvestmentProfile
If you add PeopleID into InvestmentProfileDetails and set the relation as 1:1 then it will ensure the InvestmentProfileName is unique to PeopleID.
Each PeopleID has one InvestmentProfileDetails and then you may create clusters where each PeopleID/InvestmentProfile
If you add PeopleID into InvestmentProfileDetails and set the relation as 1:1 then it will ensure the InvestmentProfileName is unique to PeopleID.
First, you've been misled in the design by the persistent myth that you "must always cluster by identity". That's the single most damaging myth in the db world.
InvestmentProfileCluster
--get rid of the InvestmentProfileClusterID
--uniquely cluster the table on ( PeopleID, InvestmentProfileDetailsID
I think that will resolve your issue. If not, and you truly need to go by PeopleID and InvestmentProfileName (??), then you will need to use a constraint with a function that does the lookup to check for dups.
InvestmentProfileCluster
--get rid of the InvestmentProfileClusterID
--uniquely cluster the table on ( PeopleID, InvestmentProfileDetailsID
I think that will resolve your issue. If not, and you truly need to go by PeopleID and InvestmentProfileName (??), then you will need to use a constraint with a function that does the lookup to check for dups.
ASKER
There is a one to many relationship between PeopleID and InvestmentProfilesDetails
Then InvestmentProfileName cannot be unique. If you need this column unique and 1:1 to PeopleID then move the column into People table.
One more thing - if there is the one to many relationship between PeopleID and InvestmentProfilesDetails why then isn't such relation in your diagram? The Diagram shows M:N relation via the cluster.
The profile detail table is the profile tablehmm, in this case: then the InvestmentProfileName column must be already unique in InvestmentProfilesDetails.
Otherwise, the entire problem seems to aries from unprecise naming.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
"In fact, trying to use identity as the key for (almost) every table hurts db design more than any other single factor"
I'm in early development. The model is being built on the fly so a lot of things will be improved for performance later.
I'm going to add the [InvestmentProfileName] to the cluster table and then add the constraint there!
I'm in early development. The model is being built on the fly so a lot of things will be improved for performance later.
I'm going to add the [InvestmentProfileName] to the cluster table and then add the constraint there!
ASKER
Thanks again Scott - You rock as always!
@Scott,
How about the shop that enforces EVERY table has to have an IDENTITY column as the PK. State table that has an IDENTITY, StateAbbrev, StateName and the address is stored in an address table as:
Been there. :-)
(of course with 55 genders and counting, it might make sense)
How about the shop that enforces EVERY table has to have an IDENTITY column as the PK. State table that has an IDENTITY, StateAbbrev, StateName and the address is stored in an address table as:
AddressID: 12831
Address: 123 Any St
City: Los Angeles
State: 6
ZIP: 93643Been there. :-)
(of course with 55 genders and counting, it might make sense)
It is much easier to handle the data when each table has unique ID as a primary key. No matter whether this is IDENTITY or not. The basic application logic can then be common for all the tables. Also replication requires PK column in each table.
Why should I create different data handling approach because the table has just a few rows? Even log tables can have unique ID.
Why should I create different data handling approach because the table has just a few rows? Even log tables can have unique ID.
@pcelba, my point is an agreement with Scott. Too many times the mindset is, we need an IDENTITY column to have a unique key when 'AL', 'AZ', 'AK', 'CA', etc. are unique as state codes/abbreviations, as are 'M' and 'F' for Gender.
I know you agree with Scott and it will work. And nobody cares it does not use common patterns because we are not talking about large application...
You'll either understand the data model design is significant and you still can fix it at this phase or later you will find that it is no longer possible...
BTW, why do you need PeopleDetailsID column? Why the GalacticID is in all three tables? Etc. etc.
You'll either understand the data model design is significant and you still can fix it at this phase or later you will find that it is no longer possible...
BTW, why do you need PeopleDetailsID column? Why the GalacticID is in all three tables? Etc. etc.
You'll either understand the data model design is significant
Identity does not even exist in a (logical) data model.
Besides, it's hugely overblown to call slapping an identity column on every table a "design". Contrary to what most developers believe, just slapping an identity column on all tables is not a sign of a "good design", instead it's a crutch to make things easier to developers to use a cookie-cutter approach to their code.
But the code is transient -- most of the data lives forever. The data is fundamentally more important. Just ask SAP, for example.
So, don't let developers take lazy short-cuts. Instead, let experienced data modelers and DBAs actually do a design. I've never met a developer that ever did a true logical data model before slapping identities on tables, rather than carefully assigning attributes to entities.
Again, the rule should be:
There is NO such thing as a "default" clustering key for a table ever. The clus index is so critical to performance that it should always on only be based on that specific table's needs.
The corollary is then obviously:
NOT EVERY TABLE NEEDS AN IDENTITY COLUMN
In fact, trying to force identity as the key for every table hurts db design more than any other single factor.
And right here we see a specific example that proves this is true. Did the developer notice it? No, the table has an identity, so its design "must" be "good", right?
We should not exchange the IDENTITY and Primary Key (PK) column.
The IDENTITY from T-SQL point of view means an integer column with autoincremented values. I am not saying each table must have IDENTITY column.
The PK column which has no "meaningful" data equivalent is used internally by the application for data identification and/or relations, it is hidden to users obviously and users have no rights to update it. And I am saying each table should have PK. (Did you try replication w/o PK?)
Of course, IDENTITY column can be used as PK and PKs must be known when designing the data model.
The application logic can enforce additional columns where data must be unique, e.g. LoginName (visible to user), CustomerCode (visible to customer) etc. This is preferably ensured by UNIQUE indexes.
If you create an application where is a mix of tables without PK, tables with PKs of various data types, then you must have special handling for each such variant. Administrators are not able to identify the data correctly and the application tends to be a big mess.
OTOH, the LoginName which is unique but not used as a PK is easy to change when the underlying person changes name etc.
CLUSTERED indexes are out of the scope of this question.
The IDENTITY from T-SQL point of view means an integer column with autoincremented values. I am not saying each table must have IDENTITY column.
The PK column which has no "meaningful" data equivalent is used internally by the application for data identification and/or relations, it is hidden to users obviously and users have no rights to update it. And I am saying each table should have PK. (Did you try replication w/o PK?)
Of course, IDENTITY column can be used as PK and PKs must be known when designing the data model.
The application logic can enforce additional columns where data must be unique, e.g. LoginName (visible to user), CustomerCode (visible to customer) etc. This is preferably ensured by UNIQUE indexes.
If you create an application where is a mix of tables without PK, tables with PKs of various data types, then you must have special handling for each such variant. Administrators are not able to identify the data correctly and the application tends to be a big mess.
OTOH, the LoginName which is unique but not used as a PK is easy to change when the underlying person changes name etc.
CLUSTERED indexes are out of the scope of this question.
ASKER
I mentioned this to Scott before.. I use templates to create tables and CRUD. Identity columns are a part of that process.
Speaking from a bad actor DBA / Top shelf developer point of view, I'm turning ideas into working solutions so I need to bring the DB model out quickly to start development. At that point I can start to show the customer the end result which is the only thing they care about or understand. I use a single script to drop and create everything including concrete inserts and additional inserts so I have something to work with. This process is greatly eased when the ID is basically the row number - 1st insert = @ID which always = 1.
At the correct point in the development cycle - I sit down and redesign the DB using all of the best practices I know. Changes at the top of the script (Tables, FKs) break the bottom of the script (Inserts, SPs) so eventually I'm able to find all the associated changes. This sometimes leads to bugs but a lot of testing before go live limits those to edge cases.
Speaking from a bad actor DBA / Top shelf developer point of view, I'm turning ideas into working solutions so I need to bring the DB model out quickly to start development. At that point I can start to show the customer the end result which is the only thing they care about or understand. I use a single script to drop and create everything including concrete inserts and additional inserts so I have something to work with. This process is greatly eased when the ID is basically the row number - 1st insert = @ID which always = 1.
At the correct point in the development cycle - I sit down and redesign the DB using all of the best practices I know. Changes at the top of the script (Tables, FKs) break the bottom of the script (Inserts, SPs) so eventually I'm able to find all the associated changes. This sometimes leads to bugs but a lot of testing before go live limits those to edge cases.
Forcing an identity column on every table hurts db design more than any other single factor in the db world.
The rush to get to coding, and to skip any type of logical design, is extremely damaging. And you can't, and wouldn't, and simply won't, go back and normalize after you're written code. Pretending to do so is just a rationalization for skipping a true design process. A proper data design doesn't take that long with some expertise and experience in doing it.
And the first meeting(s) with the clients should be about getting the data properly understood and documented, then you can worry about which boxes will do what on the screen.
The rush to get to coding, and to skip any type of logical design, is extremely damaging. And you can't, and wouldn't, and simply won't, go back and normalize after you're written code. Pretending to do so is just a rationalization for skipping a true design process. A proper data design doesn't take that long with some expertise and experience in doing it.
And the first meeting(s) with the clients should be about getting the data properly understood and documented, then you can worry about which boxes will do what on the screen.