marrowyung
asked on
how to vaildate data after database migration from oracle to MariaDB?
hi,
we are planning what to do AFTER migrating from oracle to MariaDB and this involve data compare.
what we understand is, schema can't be compare as data column type will be changed , so we can only compare data content.
other than these, we will consider data compare tools and I am considering Aqua Data Studio Features: https://www.aquafold.com/aquadatastudio_features
what else you all can suggest us to vaild data after conversion ? ( we will use ispirer to migrate data)
we are planning what to do AFTER migrating from oracle to MariaDB and this involve data compare.
what we understand is, schema can't be compare as data column type will be changed , so we can only compare data content.
other than these, we will consider data compare tools and I am considering Aqua Data Studio Features: https://www.aquafold.com/aquadatastudio_features
what else you all can suggest us to vaild data after conversion ? ( we will use ispirer to migrate data)
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
arnold,
"how in depth do you want?"
data cell/triple by cell/triple.
we want to make sure that ALL data are CORRECT migrate to new DB.
"Presumably your application exists to query/interact with the old db, and an instance that interacts with the new."
then eyeball BOTH application?
"Presumably the referential integrity is of import."
what do you mean ?
skullnobrains,
"you can use CSV or TSV exports of all tables. sorted data can be easily compared using the shell."
any example? seems complex.
"you can identify a list of the most complex queries used by your app. pick some that produce many results. remove where clauses if needed. compare the results when you run these on each db."
why need to remove where clause.
ste5an
"This means, do a schema comparison first, then a data (RBRA) comparison. "
this is the problem, schema of diff DB will not be the same, so the compare will fail !
data might have DISPLAY FORMAT problem too, so the result will say it is a different .. but this is not meant to us that the migration fail.
This is our concern.
"how in depth do you want?"
data cell/triple by cell/triple.
we want to make sure that ALL data are CORRECT migrate to new DB.
"Presumably your application exists to query/interact with the old db, and an instance that interacts with the new."
then eyeball BOTH application?
"Presumably the referential integrity is of import."
what do you mean ?
skullnobrains,
"you can use CSV or TSV exports of all tables. sorted data can be easily compared using the shell."
any example? seems complex.
"you can identify a list of the most complex queries used by your app. pick some that produce many results. remove where clauses if needed. compare the results when you run these on each db."
why need to remove where clause.
ste5an
"This means, do a schema comparison first, then a data (RBRA) comparison. "
this is the problem, schema of diff DB will not be the same, so the compare will fail !
data might have DISPLAY FORMAT problem too, so the result will say it is a different .. but this is not meant to us that the migration fail.
This is our concern.
[..] this is the problem, schema of diff DB will not be the same, so the compare will fail [..]Nope, wrong assumption. You need to this diff manually. There is imho no tool who can do this on audit level.
[..] data might have DISPLAY FORMAT problem too, so the result will say it is a different [..]Wrong assumptions again. Display format does not matter. A DATE will be a DATE in both systems. That's why the the data types in the old and new schema must be implicit convertible, cause this also implies that the conversion is always deterministic.
any example? seems complex.
- export both tables to compare to CSV/TSV.
- sort the files
- compare the files
use the sort command and the diff command. repeat for each table. nothing complex there.
which step seems complicated ?
why need to remove where clause.
the point is to produce bigger resultsets to make the comparison more pertinent.
if you already have a query that produces a few thousand rows, there is no point in changing it.
but if your complex query produces only a handful of results, remove or hack your where clause to get more.
@skullnobrains:
But:
- export both tables to compare to CSV/TSV.
- sort the files
- compare the filesBut:
the point is to produce bigger resultsets to make the comparison more pertinent.I strongly disagree. Cause this means comparing the data model and business logic. Which is not the same as comparing the data for being complete.
why is a "SELECT * FROM TABLE " a diffcult Query?
The headings could be different (manually verify those are correct..., or foce them to be correct')
like: "SELECT col1 AS 'A', col2 AS 'B', col3 AS 'C' FROM table_X;" in database 1
"SELECT kol1 AS 'A', kol2 AS 'B', kol3 AS 'C' FROM table_X;" in database 2
and they should be comparable.
Export as CSV might also take fillers in to account.
It doesn't look as rocket science to me....
The headings could be different (manually verify those are correct..., or foce them to be correct')
like: "SELECT col1 AS 'A', col2 AS 'B', col3 AS 'C' FROM table_X;" in database 1
"SELECT kol1 AS 'A', kol2 AS 'B', kol3 AS 'C' FROM table_X;" in database 2
and they should be comparable.
Export as CSV might also take fillers in to account.
It doesn't look as rocket science to me....
@ste5an
the point is to compare the way db engines behave in various use cases : obviously completion need to be checked in a different way. but completion is not the main issue after such migration. transtyping, records truncation, different behaviors with complex queries containing limits, order by, groups... and the likes are much more likelier. additionally many such queries are written differently in oracle and mysql.
feel free to build a program that can compare a billion row against another billion rows in a different db. i already have and i know for a fact that's feasible but both quite a PITA and a resource hog unless you use both rather complex algorythms and intermediate resultsets. which IMHO is overkill.
"A DATE will be a DATE in both systems" ... is a perfect example of a wrong assumption. try and stick 300BC in various DBs...
@noci : thanks for pointing out the simplicity of the approach !
the point is to compare the way db engines behave in various use cases : obviously completion need to be checked in a different way. but completion is not the main issue after such migration. transtyping, records truncation, different behaviors with complex queries containing limits, order by, groups... and the likes are much more likelier. additionally many such queries are written differently in oracle and mysql.
feel free to build a program that can compare a billion row against another billion rows in a different db. i already have and i know for a fact that's feasible but both quite a PITA and a resource hog unless you use both rather complex algorythms and intermediate resultsets. which IMHO is overkill.
"A DATE will be a DATE in both systems" ... is a perfect example of a wrong assumption. try and stick 300BC in various DBs...
@noci : thanks for pointing out the simplicity of the approach !
I didn't mean to be cynical.....,
Either this can be done by hand (few hundred of records) or it needs to be machine driven.
If the same front end should be used later then queries SHOULD not be different ==> column names & tables names need to be the same.
OR.....
There is a known list of differences.....
If the same data is found in the OLD DB as in the NEW DB the Frontend sees no difference right?
if data is Converted then there are conversion rules, then the Old Database using queries on the OLD DB that ALSO do the conversion rule on data should yield a listing that also is in the NEW DB.
For Mysql: NEW DB:
SELECT id,product,qty,date,pound_
INTO OUTFILE '/tmp/NEWDB/data.csv'
FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n';
During Conversion price was trippled... (USD -> GBP conversion) . so the query for the OLD DB would then be....
SELECT id,product,qty,date,(dolla
INTO OUTFILE '/tmp/OLDDB/data.csv'
FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n';
That should produce a pair of listings per table that can be compared with diff -y...
Either this can be done by hand (few hundred of records) or it needs to be machine driven.
If the same front end should be used later then queries SHOULD not be different ==> column names & tables names need to be the same.
OR.....
There is a known list of differences.....
If the same data is found in the OLD DB as in the NEW DB the Frontend sees no difference right?
if data is Converted then there are conversion rules, then the Old Database using queries on the OLD DB that ALSO do the conversion rule on data should yield a listing that also is in the NEW DB.
For Mysql: NEW DB:
SELECT id,product,qty,date,pound_
INTO OUTFILE '/tmp/NEWDB/data.csv'
FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n';
During Conversion price was trippled... (USD -> GBP conversion) . so the query for the OLD DB would then be....
SELECT id,product,qty,date,(dolla
INTO OUTFILE '/tmp/OLDDB/data.csv'
FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n';
That should produce a pair of listings per table that can be compared with diff -y...
The OP wants asked "how to vaildate data".
Sorry, but these are two different things..
the point is to compare the way db engines behave in various use cases :This is comparing the data model and business logic.
Sorry, but these are two different things..
@noci
that was an actual thanks. no cynicism taken.
i believe we are in a similar spot : after many years, finding solutions to whatever problems we encounter is seldom challenging any more. finding a simple good-enough one with mastered trade-offs, evolutivity, maintainability ... is the real challenge.
we may want to sort the data in SQL during the export.
@ste5an : i have no time for a splitting hair discussion on that subject so you're obviously right. my bad for providing both an actual answer and a complementary check.
that was an actual thanks. no cynicism taken.
i believe we are in a similar spot : after many years, finding solutions to whatever problems we encounter is seldom challenging any more. finding a simple good-enough one with mastered trade-offs, evolutivity, maintainability ... is the real challenge.
we may want to sort the data in SQL during the export.
@ste5an : i have no time for a splitting hair discussion on that subject so you're obviously right. my bad for providing both an actual answer and a complementary check.
Yep, sorting does help, probably use sort from the command line on the csv file.
that eliminates unintended index uses.... (you will also need to validate the datamodel by hand as Ste5an said including the indexes (and semantics on indices if differente DBMS's are used).
that eliminates unintended index uses.... (you will also need to validate the datamodel by hand as Ste5an said including the indexes (and semantics on indices if differente DBMS's are used).
ASKER
hi,
this EE post seems not much answer or reply, please help:
https://www.experts-exchange.com/questions/29135683/Impact-analysis-on-column-type-changing-AFTER-migrate-from-Oracle-to-MariaDB.html
ste5an,
"Nope, wrong assumption. You need to this diff manually. There is imho no tool who can do this on audit level."
eyeball will be implement but i don't think it is the key, I expect a tools can do all checking for me but it is the matter of what should we check to make the result making sense.
also this is not an audit, right?
"A DATE will be a DATE in both systems. That's why the the data types in the old and new schema must be implicit convertible, cause this also implies that the conversion is always deterministic."
you are saying the value stored will be the same on both side EVEN column type is different now ?
skullnobrains,
"which step seems complicated ?"
you said "sorted data can be easily compared using the shell."
what shell are you talking about ?
"- export both tables to compare to CSV/TSV.
- sort the files
- compare the files"
you mean can compare in EXCEL and then use the utility called Windiff to test the diff?
then why need to sort the file? make sure that all data MUST be in the same order, assuming it is NOT IN ORDER once exported?
so from oracle export as CSV, once migrated to MariaDB, export the data to CSV again, then compare both CSV, this is what you meant ?
ste5an,
"Running two queries and comparing them in a program is much simpler.
"
run the SAME query for Oracle from SQL developer and Workbench for MariaDB and check the result using eyeball ?
"So the probability of errors by using the wrong data type in such a comparison program "
so, you still prefer using comparison tools like Aqua data studio for it..
noci,
"why is a "SELECT * FROM TABLE " a diffcult Query?"
I know what you mean, then we will have to eyeball it! I also prefer too but there are more than one option.
I also propose your method as it is easier but if there are too much table, then I have to it for EACH table, it is a very time consuming check.
and I also suggest select count(*) and distinct count(*) as a test, then eyeball it.
"If the same data is found in the OLD DB as in the NEW DB the Frontend sees no difference right?"
The display rendering can be diff.. in oracle I use SQL developer to check the result, in MariaDB I use Toad for mySQL, display can be diff but value the same !
I am worrying about compare application will show this as DIFFERENT, then no use !
"That should produce a pair of listings per table that can be compared with diff -y...
what application is about diff -y..?
this EE post seems not much answer or reply, please help:
https://www.experts-exchange.com/questions/29135683/Impact-analysis-on-column-type-changing-AFTER-migrate-from-Oracle-to-MariaDB.html
ste5an,
"Nope, wrong assumption. You need to this diff manually. There is imho no tool who can do this on audit level."
eyeball will be implement but i don't think it is the key, I expect a tools can do all checking for me but it is the matter of what should we check to make the result making sense.
also this is not an audit, right?
"A DATE will be a DATE in both systems. That's why the the data types in the old and new schema must be implicit convertible, cause this also implies that the conversion is always deterministic."
you are saying the value stored will be the same on both side EVEN column type is different now ?
skullnobrains,
"which step seems complicated ?"
you said "sorted data can be easily compared using the shell."
what shell are you talking about ?
"- export both tables to compare to CSV/TSV.
- sort the files
- compare the files"
you mean can compare in EXCEL and then use the utility called Windiff to test the diff?
then why need to sort the file? make sure that all data MUST be in the same order, assuming it is NOT IN ORDER once exported?
so from oracle export as CSV, once migrated to MariaDB, export the data to CSV again, then compare both CSV, this is what you meant ?
ste5an,
"Running two queries and comparing them in a program is much simpler.
"
run the SAME query for Oracle from SQL developer and Workbench for MariaDB and check the result using eyeball ?
"So the probability of errors by using the wrong data type in such a comparison program "
so, you still prefer using comparison tools like Aqua data studio for it..
noci,
"why is a "SELECT * FROM TABLE " a diffcult Query?"
I know what you mean, then we will have to eyeball it! I also prefer too but there are more than one option.
I also propose your method as it is easier but if there are too much table, then I have to it for EACH table, it is a very time consuming check.
and I also suggest select count(*) and distinct count(*) as a test, then eyeball it.
"If the same data is found in the OLD DB as in the NEW DB the Frontend sees no difference right?"
The display rendering can be diff.. in oracle I use SQL developer to check the result, in MariaDB I use Toad for mySQL, display can be diff but value the same !
I am worrying about compare application will show this as DIFFERENT, then no use !
"That should produce a pair of listings per table that can be compared with diff -y...
what application is about diff -y..?
ASKER
noci:
"Yep, sorting does help, probably use sort from the command line on the csv file."
so also need to export to CSV instead of simple query ?
"that eliminates unintended index uses.... (you will also need to validate the datamodel by hand as Ste5an said including the indexes (and semantics on indices if differente DBMS's are used)."
"
I don't understand, any example? why sorting can eliminates unintended index use?
"Yep, sorting does help, probably use sort from the command line on the csv file."
so also need to export to CSV instead of simple query ?
"that eliminates unintended index uses.... (you will also need to validate the datamodel by hand as Ste5an said including the indexes (and semantics on indices if differente DBMS's are used)."
"
I don't understand, any example? why sorting can eliminates unintended index use?
If you looked at the MySQL example i provided, the output IS csv. (OLD DB & NEW DB).
A similar query should be possible for Oracle.....
On bulk production of data... Here the Mysql version...
To get a list of tables: & format it as CSV: you can use this Shell script (bash):
If you need a special fix for the FIELDS in a Query that can be made specific for some occasion say you have a special query for data (like in previous example):
if you do the same in Oracle for the OTHER database
than a diff -y /tmp/CSCV /tmp/OTHERCSV
should yield a list of differences per file.
diff is a standard Unix tool.
A similar query should be possible for Oracle.....
On bulk production of data... Here the Mysql version...
To get a list of tables: & format it as CSV: you can use this Shell script (bash):
USER=theuser
PWX=thepassword
DB=thedatabase
mkdir /tmp/CSV
TABLES=$( mysql -u$USER -p$PWX -ss -Be 'show tables' $DB ) # create a list of tables for this database
for table in $TABLES
do
FIELDS="*"
mysql -u$USER -p$PWX $DB -ss -Be "SELECT ${fields} FROM ${table} INTO OUTFILE '/tmp/CSV/${table}.csv' FIELDS TERMINATED BY ',' ENCLOSED BY '\"' LINES TERMINATED BY '\n';"
done
for f in $( ls -1 /tmp/CSV/*.csv )
do
sort <$f >${f}.sorted
done
echo the results are in /tmp/CSV raw .csv files and sorted: .csv.sorted files.
ls -l /tmp/CSVIf you need a special fix for the FIELDS in a Query that can be made specific for some occasion say you have a special query for data (like in previous example):
USER=theuser
PWX=thepassword
DB=thedatabase
mkdir /tmp/CSV
TABLES=$( mysql -u$USER -p$PWX -ss -Be 'show tables' $DB ) # create a list of tables for this database
for table in $TABLES
do
FIELDS="*"
if [ "$table" eq "data" ]
then
FIELDS=" id,product,qty,date,(dollar_price *3) as pound_price "
fi
mysql -u$USER -p$PWX $DB -ss -Be "SELECT ${fields} FROM ${table} INTO OUTFILE '/tmp/CSV/${table}.csv' FIELDS TERMINATED BY ',' ENCLOSED BY '\"' LINES TERMINATED BY '\n';"
done
for f in $( ls -1 /tmp/CSV/*.csv )
do
sort <$f >${f}.sorted
done
echo the results are in /tmp/CSV raw .csv files and sorted: .csv.sorted files.
ls -l /tmp/CSVif you do the same in Oracle for the OTHER database
than a diff -y /tmp/CSCV /tmp/OTHERCSV
should yield a list of differences per file.
diff is a standard Unix tool.
[..] you are saying the value stored will be the same on both side EVEN column type is different now ? [..]To migrate a database from one system to another you need as first step a data type mapping. Cause data type names and definition may differ, sometimes the precision is not equal.
This leads to the following questions:
1. Are all data types implicit convertible?
This means that the data type on the destination system is equal or wider by precision (or domain).
2. When not, how is the conversion defined?
[..] you are saying the value stored will be the same on both side EVEN column type is different now ? [..]Now the first step, basic schema comparision, in the DATE case:
Consider the case that you have a DATE in the source system and only a DATETIME in the destination system. Then the schema comparison must check the destination system for the column being DATETIME and having a constraint allowing only a time portion of 00:00:00.
For other data types where no implicit conversion exists, you need of course to implement the transform in your check. But this is hard without concrete example. Do you have such a case?
[..] run the SAME query for Oracle from SQL developer and Workbench for MariaDB and check the result using eyeball ? [..]It's quickly written in .NET or PowerShell.
ASKER
noci,
"If you looked at the MySQL example i provided, the output IS csv. (OLD DB & NEW DB).
A similar query should be possible for Oracle....."
you talking about this ?
"To get a list of tables: & format it as CSV: you can use this Shell script (bash):"
ok. the output will be a CSV files.
any same version for MySQL/MariaDB which let me run from UI tools ?
"than a diff -y /tmp/CSCV /tmp/OTHERCSV "
any sample output? our oracle are on Windows, then how can we diff that across both platform?
so you are saying there are 2 x method:
1) generate the CSV for both platform and diff that and see the output.
2) select count(*) for each table and eyeball both side
is that all what you mean ?
any data integrity check between both side? and how to do it ?
ste5an,
"This leads to the following questions:
1. Are all data types implicit convertible?"
Ispirer tools do it for us, and what we know now is:
1) NUMBER(10,0) (10 digits / no decimal places) and NUMBER (9,0) (9 digits / no decimal places) will be convert to BIGINT
2) NUMBER(3,0) (3 digits / no decimal places) will be convert to SMALLINT
3) NUMBER(1,0) (1 digits / no decimal places) will be convert to TINYINT.
4) NUMBER without () (e.g. NUMBER) will be convert to Double type.
Actually should be a yes ! I try some table migration and it works with data reserved.
" Then the schema comparison must check the destination system for the column being DATETIME and having a constraint allowing only a time portion of 00:00:00."
how to do it in MariaDB ?
"It's quickly written in .NET or PowerShell."
sorry which one? or written by us you mean ?
"If you looked at the MySQL example i provided, the output IS csv. (OLD DB & NEW DB).
A similar query should be possible for Oracle....."
you talking about this ?
"For Mysql: NEW DB:
SELECT id,product,qty,date,pound_
INTO OUTFILE '/tmp/NEWDB/data.csv'
FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n';
During Conversion price was trippled... (USD -> GBP conversion) . so the query for the OLD DB would then be....
SELECT id,product,qty,date,(dolla
INTO OUTFILE '/tmp/OLDDB/data.csv'
FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n';"
SELECT id,product,qty,date,pound_
INTO OUTFILE '/tmp/NEWDB/data.csv'
FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n';
During Conversion price was trippled... (USD -> GBP conversion) . so the query for the OLD DB would then be....
SELECT id,product,qty,date,(dolla
INTO OUTFILE '/tmp/OLDDB/data.csv'
FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n';"
"To get a list of tables: & format it as CSV: you can use this Shell script (bash):"
ok. the output will be a CSV files.
any same version for MySQL/MariaDB which let me run from UI tools ?
"than a diff -y /tmp/CSCV /tmp/OTHERCSV "
any sample output? our oracle are on Windows, then how can we diff that across both platform?
so you are saying there are 2 x method:
1) generate the CSV for both platform and diff that and see the output.
2) select count(*) for each table and eyeball both side
is that all what you mean ?
any data integrity check between both side? and how to do it ?
ste5an,
"This leads to the following questions:
1. Are all data types implicit convertible?"
Ispirer tools do it for us, and what we know now is:
1) NUMBER(10,0) (10 digits / no decimal places) and NUMBER (9,0) (9 digits / no decimal places) will be convert to BIGINT
2) NUMBER(3,0) (3 digits / no decimal places) will be convert to SMALLINT
3) NUMBER(1,0) (1 digits / no decimal places) will be convert to TINYINT.
4) NUMBER without () (e.g. NUMBER) will be convert to Double type.
Actually should be a yes ! I try some table migration and it works with data reserved.
" Then the schema comparison must check the destination system for the column being DATETIME and having a constraint allowing only a time portion of 00:00:00."
how to do it in MariaDB ?
"It's quickly written in .NET or PowerShell."
sorry which one? or written by us you mean ?
ASKER
Please help to answer this if you can:
https://www.experts-exchange.com/questions/29135660/impact-on-MariaDB-GUI-and-report-design-AFTER-changing-from-Oracle.html
https://www.experts-exchange.com/questions/29135660/impact-on-MariaDB-GUI-and-report-design-AFTER-changing-from-Oracle.html
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
"A note on dates, if you do select queries try to format dates as comparable strings: "YYYYMMDD HHMMSS" (strings of years, month, day, hour, minute, seconds, parts of seconds)."
if I export to an excel, do I still have to worry about that ?
if I export to an excel, do I still have to worry about that ?
ASKER
hi sir,
any update ?
"Yes, csv files are flat "almost" unstructured ASCII files that can be copied around"
so this means the same csv can be in windows and linux ?and we can compare it.
any update ?
"Yes, csv files are flat "almost" unstructured ASCII files that can be copied around"
so this means the same csv can be in windows and linux ?and we can compare it.
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
"You may want to look into "Beyond Compare" to do a difference check on windows."
oh that one is a tools ? what is the brand ?
oh that one is a tools ? what is the brand ?
ASKER
hi,
now I figure out how to export csv from UI tools (toad for mySQL) and now it is the comparison tools. is this the tools you are referring to ?
https://www.scootersoftware.com/download.php
?
now I figure out how to export csv from UI tools (toad for mySQL) and now it is the comparison tools. is this the tools you are referring to ?
https://www.scootersoftware.com/download.php
?
ASKER
skullnobrains,
"we may want to sort the data in SQL during the export."
do you know how using Toad for MySQL to export data to CSV, and SQL developer for Oracle, how can we sort it?
you are worrying about the output of both is not the same so the diff -y say it is not the same ?
also anyone know how to make Toad for MySQL export all data to CSV file in one single files ? it now seems that SQL developer can do it but Toad for mySQL can't! Toad for MySQL will create a new CSV for each table it export, but oracle can export all table data in a single CSV files.
How can I compare using program?
Oracle can only export CSV from oracle itself but not MySQL, so hard to export MySQL data to a single file using SQL developer.
noci:
"(you will also need to validate the datamodel by hand as Ste5an said including the indexes (and semantics on indices if differente DBMS's are used)."
how can I vaildate data model ? very hard too.
how it seems that exporting data from MySQL to a SINGLE CSV file has problem, I can't do it using Toad for MySQL and my workbench.
"Beyond Compare" can only compare files, can't compare DB table content directly.
for the script you shown me, should I just copy the code and save it as .sh file and I run it using ./<file>.sh ?
"we may want to sort the data in SQL during the export."
do you know how using Toad for MySQL to export data to CSV, and SQL developer for Oracle, how can we sort it?
you are worrying about the output of both is not the same so the diff -y say it is not the same ?
also anyone know how to make Toad for MySQL export all data to CSV file in one single files ? it now seems that SQL developer can do it but Toad for mySQL can't! Toad for MySQL will create a new CSV for each table it export, but oracle can export all table data in a single CSV files.
How can I compare using program?
Oracle can only export CSV from oracle itself but not MySQL, so hard to export MySQL data to a single file using SQL developer.
noci:
"(you will also need to validate the datamodel by hand as Ste5an said including the indexes (and semantics on indices if differente DBMS's are used)."
how can I vaildate data model ? very hard too.
how it seems that exporting data from MySQL to a SINGLE CSV file has problem, I can't do it using Toad for MySQL and my workbench.
"Beyond Compare" can only compare files, can't compare DB table content directly.
for the script you shown me, should I just copy the code and save it as .sh file and I run it using ./<file>.sh ?
ASKER
so now, the best method is
1) export as CSV and diff -y or compare using application program like Aqua data studio.
2) eyeball on result set from select * tables
right ?
1) export as CSV and diff -y or compare using application program like Aqua data studio.
2) eyeball on result set from select * tables
right ?
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
"cat *.csv >allfiles.csv.all "
but this, you still referring to Unix or linux method, right?
for me, oracle on Windows and MariaDB on linux.
I am a windows person I prefer run all result from UI and then export to CSV, any idea after I export all CSV (one by one using tools) I can combine all of them in a single files ?
"Eyeballing is NEVER the best method..., the best methods can be repeated without a lot of effort.
Eyeballing is a last resort method when all else fails or is too expensive. Eyeball comparing 2Million records is very hard to do...... let alone do it repeatedly."
yes! last sort!
a vendor said just compare report output and that's it, they mean if the report give 1000 rows from DIFFERENT DB, the table give data most likely equal in rows of data, which I don't think so. they just want to save effort!
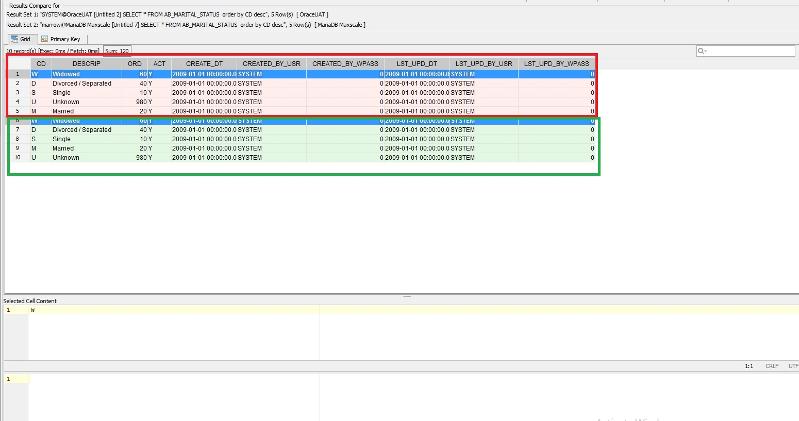
today tried Aqua data studio, seems only them can connect to DIFFERENT DB and compare the result set between them , e.g. both result set is Select * from <Table> , then use Aqua data studio to compare both RESULT SET. but the result in the UI is hard to read.
this is its look and might be you can tell if both result set the same:
"Yes that beyond compare, and it can be used to compare files & directories."
it can only compare files, agree ? not connect to DB directly and compare data between DBs.
". On Unix systems a lot more tools are available to script stuff w.r.t. Windows environment. A point & Click system doesn't help automating tasks."
you prefer command mode.
but this, you still referring to Unix or linux method, right?
for me, oracle on Windows and MariaDB on linux.
I am a windows person I prefer run all result from UI and then export to CSV, any idea after I export all CSV (one by one using tools) I can combine all of them in a single files ?
"Eyeballing is NEVER the best method..., the best methods can be repeated without a lot of effort.
Eyeballing is a last resort method when all else fails or is too expensive. Eyeball comparing 2Million records is very hard to do...... let alone do it repeatedly."
yes! last sort!
a vendor said just compare report output and that's it, they mean if the report give 1000 rows from DIFFERENT DB, the table give data most likely equal in rows of data, which I don't think so. they just want to save effort!
today tried Aqua data studio, seems only them can connect to DIFFERENT DB and compare the result set between them , e.g. both result set is Select * from <Table> , then use Aqua data studio to compare both RESULT SET. but the result in the UI is hard to read.
this is its look and might be you can tell if both result set the same:

"Yes that beyond compare, and it can be used to compare files & directories."
it can only compare files, agree ? not connect to DB directly and compare data between DBs.
". On Unix systems a lot more tools are available to script stuff w.r.t. Windows environment. A point & Click system doesn't help automating tasks."
you prefer command mode.
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
slightwv,
"You can easily diff two files on Windows just as easy as Linux:
https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.utility/compare-object?view=powershell-6"
tks,
"For the Oracle side, you could have had a .sql script that selected ALL rows from ALL tables in a specific format spooled to whatever file or files you want.
I assume the MariaDB side has similar abilities to capture output of a select from a command line."
this is what I am keep seraching for. but seems can't be done by Toad for MySQL and Oracle SQL developer ! I planned to do it in UI and export it to CSV, seems hard. you can share the script for me so that I can run from UI tools instead of command mode.,
do you use any UI tools can export out aLL data from all table easily than command ? now I am using Toad for MysQL and run query but when exporting CSV out each table will create one individual CSV so if I have 2400 tables I will have 2400 CSV,
SQL developer I am figuring how to export the result set to ONE CSV files.
"You could have probably been done by now depending on how long it takes to extract ALL data from ALL tables?"
researching.
noci,
"You need at lease sort statements to "glance" over the data when using AQUA, to get comparable data. (arbitrary sort )
select col1, col2, col3, col4, ... from tbl1 order by col1, col2, col3, col4, ... ;"
need to do it for all column ?
not for each table, right?
AQUA has a result set compare feature but it seems telling me nothing! I try a result that a table has 100 record and the other SAME table in other DB has only 50 records, the compare show me nothing on which one has problem.\
I am checking with their product engine to see why.
skullnobrains,
"Checking the number of rows allows to determine the datadet is complete. "
the compare program will have to check each data triple and see if all field is the same, right ?
now I am looking for script to run from UI tools to return all record from all table on both oracle and MariaDB, I tried bash many time but as I am not a linux player I can't see why it doesn't work.
bash appliation need to install separately on linux ?
"You can easily diff two files on Windows just as easy as Linux:
https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.utility/compare-object?view=powershell-6"
tks,
"For the Oracle side, you could have had a .sql script that selected ALL rows from ALL tables in a specific format spooled to whatever file or files you want.
I assume the MariaDB side has similar abilities to capture output of a select from a command line."
this is what I am keep seraching for. but seems can't be done by Toad for MySQL and Oracle SQL developer ! I planned to do it in UI and export it to CSV, seems hard. you can share the script for me so that I can run from UI tools instead of command mode.,
do you use any UI tools can export out aLL data from all table easily than command ? now I am using Toad for MysQL and run query but when exporting CSV out each table will create one individual CSV so if I have 2400 tables I will have 2400 CSV,
SQL developer I am figuring how to export the result set to ONE CSV files.
"You could have probably been done by now depending on how long it takes to extract ALL data from ALL tables?"
researching.
noci,
"You need at lease sort statements to "glance" over the data when using AQUA, to get comparable data. (arbitrary sort )
select col1, col2, col3, col4, ... from tbl1 order by col1, col2, col3, col4, ... ;"
need to do it for all column ?
not for each table, right?
AQUA has a result set compare feature but it seems telling me nothing! I try a result that a table has 100 record and the other SAME table in other DB has only 50 records, the compare show me nothing on which one has problem.\
I am checking with their product engine to see why.
skullnobrains,
"Checking the number of rows allows to determine the datadet is complete. "
the compare program will have to check each data triple and see if all field is the same, right ?
now I am looking for script to run from UI tools to return all record from all table on both oracle and MariaDB, I tried bash many time but as I am not a linux player I can't see why it doesn't work.
bash appliation need to install separately on linux ?
ASKER
guy I am not sure how to score you all, the wizar disappeared.
>>do you use any UI tools can export out aLL data from all table easily than command ?
I would use command line to execute scripts. I'm not a fan of GUIs. They tend to slow things down.
Even you are finding issues just trying to find some GUI that will do this for you:
If you took the time you have invested in trying to find a GUI, you could have likely had the scripts done and likely had the data compared.
>>I tried bash many time but as I am not a linux player I can't see why it doesn't work.
bash is just a shell. It just allows you to run commands and adds some built-in features. What you likely need is just the MySQL and Oracle programs like mysql and sqlplus to execute queries against the database and capture the output.
>>bash appliation need to install separately on linux ?
as I said above: bash is just a shell. It comes with Linux unless you go out of your way to not install it. If you have a script that isn't working, you will need to debug it.
I would use command line to execute scripts. I'm not a fan of GUIs. They tend to slow things down.
Even you are finding issues just trying to find some GUI that will do this for you:
AQUA has a result set compare feature but it seems telling me nothing!
If you took the time you have invested in trying to find a GUI, you could have likely had the scripts done and likely had the data compared.
>>I tried bash many time but as I am not a linux player I can't see why it doesn't work.
bash is just a shell. It just allows you to run commands and adds some built-in features. What you likely need is just the MySQL and Oracle programs like mysql and sqlplus to execute queries against the database and capture the output.
>>bash appliation need to install separately on linux ?
as I said above: bash is just a shell. It comes with Linux unless you go out of your way to not install it. If you have a script that isn't working, you will need to debug it.
Not sure, under each comment, there are four options with the "is this a solution" pick the ones that were helpful to you, then select the one that you see as the solution for your question.
i know the thread is closed but :
"the compare program will have to check each data triple and see if all field is the same, right ?"
a recursive diff will let you do that. nevertheless it is rather pointless. truncation needs to be checked for. other importation glitches would impact most of the rows, most likely all of them. checking each field of each row is a long road. importing into strict mode will detect most possible mistakes. and completion can be checked using the number of rows.
"the compare program will have to check each data triple and see if all field is the same, right ?"
a recursive diff will let you do that. nevertheless it is rather pointless. truncation needs to be checked for. other importation glitches would impact most of the rows, most likely all of them. checking each field of each row is a long road. importing into strict mode will detect most possible mistakes. and completion can be checked using the number of rows.
ASKER
arnold,
i accidently click the cross site to cancel, but I tried to cancel the this is my answer tab again and the score wizard don't show up any more.
slightwv (䄆 Netminder)
"If you took the time you have invested in trying to find a GUI, you could have likely had the scripts done and likely had the data compared."
knew what you mean but I tried bash one, the bash command doens't work for me.
do I need to install it in Redhat linux ? how ?
next week (this is friday night here) i will try to save it as .sh and try to execute it.
"as I said above: bash is just a shell. It comes with Linux unless you go out of your way to not install it. If you have a script that isn't working, you will need to debug it."
will send you the screenshot on why it doesn't work next week.
i accidently click the cross site to cancel, but I tried to cancel the this is my answer tab again and the score wizard don't show up any more.
slightwv (䄆 Netminder)
"If you took the time you have invested in trying to find a GUI, you could have likely had the scripts done and likely had the data compared."
knew what you mean but I tried bash one, the bash command doens't work for me.
do I need to install it in Redhat linux ? how ?
next week (this is friday night here) i will try to save it as .sh and try to execute it.
"as I said above: bash is just a shell. It comes with Linux unless you go out of your way to not install it. If you have a script that isn't working, you will need to debug it."
will send you the screenshot on why it doesn't work next week.
ASKER
skullnobrains,
"checking each field of each row is a long road. "
but we have to , how can we know all data migrated ?
"and completion can be checked using the number of rows."
you mena other than check triple by triple, someone also use select count(*) from a table instead ? and they will also accept that, right ?
"checking each field of each row is a long road. "
but we have to , how can we know all data migrated ?
"and completion can be checked using the number of rows."
you mena other than check triple by triple, someone also use select count(*) from a table instead ? and they will also accept that, right ?
yes. i gave you a combination of checks that are more than enough. the tools you use are deterministic. do not trust the tools themselves but trust that at least to some extent. there is no way an automated tool will mess one single field of one single row in a huge import.
>>do I need to install it in Redhat linux ? how ?
No. I cannot think of any mainstream Linux distro that doesn't come with it unless you purposely tell it not to install.
>> there is no way an automated tool will mess one single field of one single row in a huge import.
As long as the sample rows you check are known extreme boundaries in the source: Largest number, longest string, earliest and latest dates, etc... special characters in text fields are also a concern: Moving data that might be in a multi-byte characterset can easily fail.
As long as you identify those rows in the source DB, all you should need to do is check those rows in the destination database.
For example: a table with a number column that has 10 million rows: The minimum and maximum values for that column in the table are: 1 and 123456789. After the migration, check those two values in the destination. If they are the same, you can safely assume the other 9,999,998 rows values migrated correctly.
No. I cannot think of any mainstream Linux distro that doesn't come with it unless you purposely tell it not to install.
>> there is no way an automated tool will mess one single field of one single row in a huge import.
As long as the sample rows you check are known extreme boundaries in the source: Largest number, longest string, earliest and latest dates, etc... special characters in text fields are also a concern: Moving data that might be in a multi-byte characterset can easily fail.
As long as you identify those rows in the source DB, all you should need to do is check those rows in the destination database.
For example: a table with a number column that has 10 million rows: The minimum and maximum values for that column in the table are: 1 and 123456789. After the migration, check those two values in the destination. If they are the same, you can safely assume the other 9,999,998 rows values migrated correctly.
Additional:
If you want to do simple checks on large amount of numbers then highest, lowest & #occurences are one measurement, also calculating average & deviation will tell you the spread among those values.
So they should hold the same numbers when all those numbers are the same.
If you want to do simple checks on large amount of numbers then highest, lowest & #occurences are one measurement, also calculating average & deviation will tell you the spread among those values.
So they should hold the same numbers when all those numbers are the same.
You could use a script that can connect to both.
Presumably the referential integrity is of import.
Presumably your application exists to query/interact with the old db, and an instance that interacts with the new.