Uniqueidentifier column - Clustered vs. Non-clustered primary key?
Hi all
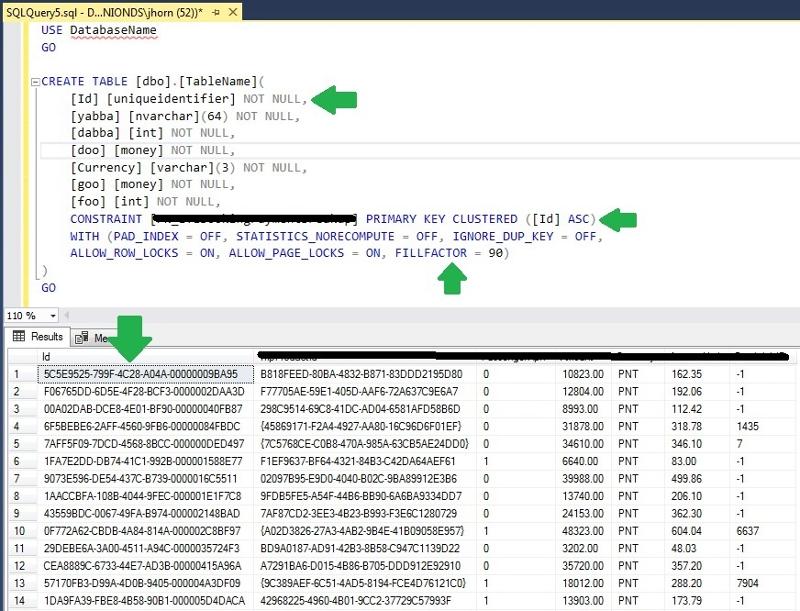
My current employer has a number of SQL Server 2008R2* tales whose clustered primary key is a uniqueidentifier column (usually with FILLFACTOR = 90) that either our front-end randomly generates, or is INSERTed via a stored procedure with passed parameters that generates a NEWID() value. This all happened way before my time.
Potentially stupid question: Since clustered primary keys physically store the data in order, and the uniqueidentifiers are randomly generated, should I change the clustered primary key to a non-clustered, and save all the time spent on page splits inserting values when the order truly does not matter?
Thanks in advance.
Jim
* We're in the middle of a 2016 conversion.
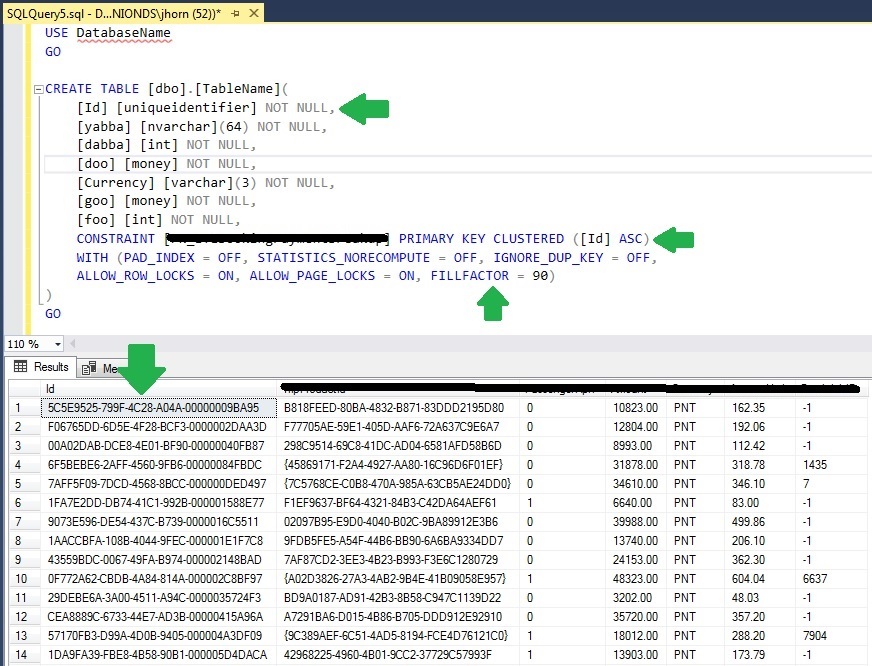
My current employer has a number of SQL Server 2008R2* tales whose clustered primary key is a uniqueidentifier column (usually with FILLFACTOR = 90) that either our front-end randomly generates, or is INSERTed via a stored procedure with passed parameters that generates a NEWID() value. This all happened way before my time.
Potentially stupid question: Since clustered primary keys physically store the data in order, and the uniqueidentifiers are randomly generated, should I change the clustered primary key to a non-clustered, and save all the time spent on page splits inserting values when the order truly does not matter?
Thanks in advance.
Jim
* We're in the middle of a 2016 conversion.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
You only get one clustered-index on a table, I wouldn't waste it on a primary-key.
I would suggest not using a clustered-index, it's expensive.
Exception: if your table contains a date-field that is commonly used in a between-clause, greater-than, greater-than-or-equal-to then cluster on the date-field.
I would suggest not using a clustered-index, it's expensive.
Exception: if your table contains a date-field that is commonly used in a between-clause, greater-than, greater-than-or-equal-to then cluster on the date-field.
Physically speaking, index usage is what makes the choice between clustered unique index or non clustered unique index relevant. logically speaking, you *must* have at least on primary key or a unique identifier per table to prevent duplicates. Having no mecanism to distinguish tuples is a design mistake.
Hope this helps.
Hope this helps.
The primary-key constraint is to ensure uniqueness, but this field does not need to be physically sorted on a data-page because I doubt anyone would use the primary-key in a range-test (between, >, >=).
@John
Distinguishibility necessity between tuples has nothing to do with performance at usage time. SQL offers the possibility to either implement unique identifiers as primary clustered keys for range queries or unique identifiers as non clustered unique keys for random queries. Trading integrity for performance is always a bad idea.
Distinguishibility necessity between tuples has nothing to do with performance at usage time. SQL offers the possibility to either implement unique identifiers as primary clustered keys for range queries or unique identifiers as non clustered unique keys for random queries. Trading integrity for performance is always a bad idea.
You can have:
1 a unique identifier with clustered index(known as sql primary key)
2 a unique key with non clustered index
3 all of the above
4 none of the above in which case you will have dupplicates causing incorrect results
1 a unique identifier with clustered index(known as sql primary key)
2 a unique key with non clustered index
3 all of the above
4 none of the above in which case you will have dupplicates causing incorrect results
@Racim
I didn't state to eliminate primary/foreign key constraints/indexes, I'm suggesting not to waste the tables only clustering on the primary-key because the constraint/index already enforces uniqueness, clustering will not help/improve uniqueness. But clusterting will help in performance if applied to a date-field if that date-field is used often in a range-test.
I didn't state to eliminate primary/foreign key constraints/indexes, I'm suggesting not to waste the tables only clustering on the primary-key because the constraint/index already enforces uniqueness, clustering will not help/improve uniqueness. But clusterting will help in performance if applied to a date-field if that date-field is used often in a range-test.
1 a unique identifier with clustered index(known as sql primary key)
Primary key has nothing to do with a column having the IDENTITY property or being clustered: a primary key can be clustered or non-clustered. The primary key is a logical and physical declaration that given column(s) will have no NULL values and will have no duplicate values in that table.
Having no mecanism to distinguish tuples is a design mistake. ... Trading integrity for performance is always a bad idea.
It's not that simple. Often it's best to leave purely staging tables with no indexes (formally called a "heap" in SQL). If the entire table will always be processed later, there's no need for an index and no need to distinguish between rows and/or find duplicate rows.
ASKER
@Scott - Thanks. When doing further research it appears that the id column ONLY exists to be a primary key, generated randomly by SP's using NEWID().
Looking at the remaining columns at least the first three do not guarantee uniqueness, and I'm wild guessing that the id column was created because somebody did not want to put the work into the upstream ETL code (This table is in a datamart) to guarantee uniqueness across multiple columns, so it was easier to just create a random NEWID() as the clustered PK.
I've noticed this with every airline client I've had as sometimes the takeoff time of a flight changes, and ETL's if not designed to handle this scenario will interpret that as an INSERT and not an UPDATE.
I ran sp_BlitzIndex on the table and noticed that out of 353k singleton lookups per the Op Stats column, there were only >> Reads: 1,771 (1,373 seek 392 scan 6 lookup) Writes:14,746 << on the PK column, which for the moment I'll attribute only to developer lookups while doing prod support. Will verify that to be sure.
Looking at the remaining indexes all are <700 reads, 13k-ish writes.
So my knee-jerk options are..
Further down the road will be changing all of these (multiple expletives deleted) PK uniqueidentifier columns to int identity's, but that is a much bigger task.
Looking at the remaining columns at least the first three do not guarantee uniqueness, and I'm wild guessing that the id column was created because somebody did not want to put the work into the upstream ETL code (This table is in a datamart) to guarantee uniqueness across multiple columns, so it was easier to just create a random NEWID() as the clustered PK.
I've noticed this with every airline client I've had as sometimes the takeoff time of a flight changes, and ETL's if not designed to handle this scenario will interpret that as an INSERT and not an UPDATE.
I ran sp_BlitzIndex on the table and noticed that out of 353k singleton lookups per the Op Stats column, there were only >> Reads: 1,771 (1,373 seek 392 scan 6 lookup) Writes:14,746 << on the PK column, which for the moment I'll attribute only to developer lookups while doing prod support. Will verify that to be sure.
Looking at the remaining indexes all are <700 reads, 13k-ish writes.
So my knee-jerk options are..
- Spend some time fixing the upstream ETL code to guarantee uniqueness.
- Delete the id column entirely, and make the second column the non-clustered primary key.
- Delete the id column entirely, and make the multiple columns the clustered primary key.
Further down the road will be changing all of these (multiple expletives deleted) PK uniqueidentifier columns to int identity's, but that is a much bigger task.
Sounds good. Looks like you've done the proper research.
Before doing anything please look at the index statitics usage.