marrowyung
asked on
change table schema when mysql replication enabled/MySQL Percona XtraDB Cluster
hi,
usually in an MySQL Percona XtraDB Cluster, change schema is a nightmare, how you guys handle schema change for it?
usually in an MySQL Percona XtraDB Cluster, change schema is a nightmare, how you guys handle schema change for it?
ASKER
I am sorry sir, when replication enabled , like the one in Percona XtraDB Cluster, this is a total different story.
like in replication, schema can't change at all or replication break down !
like in replication, schema can't change at all or replication break down !
Abolutely not. Schema changes do work and do not break replication. But yoj may need to either putg the db offline, or make sure you use a huge gcache before changing huge datasets.
In many cases, copying to a new table and renaming afterwards is less painful. Make sure you lock the table during the operation. Sometimes you can play with views to keep the destination table writeable ( but not read exhaustive ( during the operation
In many cases, copying to a new table and renaming afterwards is less painful. Make sure you lock the table during the operation. Sometimes you can play with views to keep the destination table writeable ( but not read exhaustive ( during the operation
ASKER
skullnobrains,
"Abolutely not. Schema changes do work and do not break replication"
is that mean you are using this in your office production platform now and whenever replicating table has schema change replication keep going ?
when I get training trainer also said we can't alter schema on a replicating table or replication will breaks.
" or make sure you use a huge gcache before changing huge datasets."
what is gcache ?
"In many cases, copying to a new table and renaming afterwards is less painful."
yeah! but why need this ? as it will break replication . ...
"Make sure you lock the table during the operation. "
how to lock ? if lock how can I ALTER it ?
"play with views to keep the destination table writeable"
view is read only right ?
"Abolutely not. Schema changes do work and do not break replication"
is that mean you are using this in your office production platform now and whenever replicating table has schema change replication keep going ?
when I get training trainer also said we can't alter schema on a replicating table or replication will breaks.
" or make sure you use a huge gcache before changing huge datasets."
what is gcache ?
"In many cases, copying to a new table and renaming afterwards is less painful."
yeah! but why need this ? as it will break replication . ...
"Make sure you lock the table during the operation. "
how to lock ? if lock how can I ALTER it ?
"play with views to keep the destination table writeable"
view is read only right ?
Yes i Do use the gallera cluster on productions servers
gcache is the replication buffer in gallera. You should google such things before asking here. This is well documented.
Renaming tables do not break replication either. Are you actually using a gallera cluster ? If not mysql regular replication does not have the same features.
No views are not always read only. As long as the server can figure out what to update. basically whatever view is based on a single table with no group by clause will be updatable. This is also well documented.
There is a lock table statement if you need to lock tables.
gcache is the replication buffer in gallera. You should google such things before asking here. This is well documented.
Renaming tables do not break replication either. Are you actually using a gallera cluster ? If not mysql regular replication does not have the same features.
No views are not always read only. As long as the server can figure out what to update. basically whatever view is based on a single table with no group by clause will be updatable. This is also well documented.
There is a lock table statement if you need to lock tables.
ASKER
" If not mysql regular replication does not have the same features."
I am sorry, do not have what feature ?
"No views are not always read only. As long as the server can figure out what to update. basically whatever view is based on a single table with no group by clause will be updatable. "
you are talking about MySQL, not oracle, right?
"There is a lock table statement if you need to lock tables."
so when I need to do Alter table on replicated table I need:
1) lock table first then change schema ?
2) or db offline (still can change schema?), or make sure you use a huge gcache before changing huge datasets and then change schema ?
3) or use views to keep the destination table writeable so that operation do not stop while schema changing ?
" This is also well documented."
please share the link of the documentation.
I am sorry, do not have what feature ?
"No views are not always read only. As long as the server can figure out what to update. basically whatever view is based on a single table with no group by clause will be updatable. "
you are talking about MySQL, not oracle, right?
"There is a lock table statement if you need to lock tables."
so when I need to do Alter table on replicated table I need:
1) lock table first then change schema ?
2) or db offline (still can change schema?), or make sure you use a huge gcache before changing huge datasets and then change schema ?
3) or use views to keep the destination table writeable so that operation do not stop while schema changing ?
" This is also well documented."
please share the link of the documentation.
i meant the ability to replicate schema changes.
mysql, yes.
you need to first figure out whether the replication you use supports schema changes. then check you have enough disk space for twice the relevant table size. then there is no steps we can give without an idea of the volume, cluster structure, and requirements in terms of availability. given your usual questions, i'd give a 99% chance that if the schema change is actually supported, you should just run the query during not-too-busy hours. noone in his right mind would advise you with exact steps without that information.
i won't provide a link. i googled for "writable view mysql" and the first 2 links are a tuto regarding said views, and the mysql manual section regarding updateable/insertable views. i am not willing to answer more unless you bother doing that much of personal work before asking me.
mysql, yes.
you need to first figure out whether the replication you use supports schema changes. then check you have enough disk space for twice the relevant table size. then there is no steps we can give without an idea of the volume, cluster structure, and requirements in terms of availability. given your usual questions, i'd give a 99% chance that if the schema change is actually supported, you should just run the query during not-too-busy hours. noone in his right mind would advise you with exact steps without that information.
i won't provide a link. i googled for "writable view mysql" and the first 2 links are a tuto regarding said views, and the mysql manual section regarding updateable/insertable views. i am not willing to answer more unless you bother doing that much of personal work before asking me.
ASKER
"then there is no steps we can give without an idea of the volume, cluster structure, and requirements in terms of availability."
data volume: 886GB.
Availabilty: 12Hours.(amazing.. !!)
cluster structure: 3 x mariaDB nodes per site, 1 x maxscale per site and we will have 2 x sites.
around 160 concurrent connection at peak time.
5781 queries in 63 hours
" given your usual questions, i'd give a 99% chance that if the schema change is actually supported, you should just run the query during not-too-busy hours."
Usually it will be. when change is executing, application will be stopped ! but the question is also, technically, even when we do not have transaction ongoing, replication is not going to break (technically) ?
data volume: 886GB.
Availabilty: 12Hours.(amazing.. !!)
cluster structure: 3 x mariaDB nodes per site, 1 x maxscale per site and we will have 2 x sites.
around 160 concurrent connection at peak time.
5781 queries in 63 hours
" given your usual questions, i'd give a 99% chance that if the schema change is actually supported, you should just run the query during not-too-busy hours."
Usually it will be. when change is executing, application will be stopped ! but the question is also, technically, even when we do not have transaction ongoing, replication is not going to break (technically) ?
Those volumes are rather small, so reasonable hardware should be able to cope with a schema change within minutes. The more indexes the longer. I d plan about one hour with partial downtime to be on the safe side but that obviouly depends on the hardware. You can very effectively test the timing by creating a new table based on the existing one. That will use up quite some ram, but will not block read queries and give you a decent idea of how long the actual alter table will take. And you can interrupt the process any time if necessary.
As a side note, beware that a single mariadb cluster spawning two datacenters is a bad idea with a quorum based cluster. your two datacenters have identical weights, so both sides will stop being primary if the connection between the datacenters is lost. You need to setup an additional site with a weight of 3. This can be done using garbd if you do not want to store data on the 3rd site.
If you have 2 different clusters and a regular multimaster replication between bogh sites, the replication will indeed break. In that case, you will need some downtime. there are various ways to cope with that situation but all of them end up with some downtime. Given the 12 hours, this should not be a problem.
As a side note, beware that a single mariadb cluster spawning two datacenters is a bad idea with a quorum based cluster. your two datacenters have identical weights, so both sides will stop being primary if the connection between the datacenters is lost. You need to setup an additional site with a weight of 3. This can be done using garbd if you do not want to store data on the 3rd site.
If you have 2 different clusters and a regular multimaster replication between bogh sites, the replication will indeed break. In that case, you will need some downtime. there are various ways to cope with that situation but all of them end up with some downtime. Given the 12 hours, this should not be a problem.
Bottom line is the mariadb clusters do handle schema changes.
Regular row based mysql replications do not.
i m unsure about transaction based replications in current mysql versions. Last time i used such setups, they did not.
Regular row based mysql replications do not.
i m unsure about transaction based replications in current mysql versions. Last time i used such setups, they did not.
ASKER
"your two datacenters have identical weights, so both sides will stop being primary if the connection between the datacenters is lost"
yeah, this is brain split and we need quorum on third datacenter !
but in MariaDB, which is the quorum ?
"This can be done using garbd if you do not want to store data on the 3rd site."
what is garbd ? any URL for it ?
"If you have 2 different clusters "
SAME MariaDB cluster ACROSS 2 x different datacenter, it should be ok, right ?I know MySQL do not prefer that and PostgreSQL can't even do it.
" the replication will indeed break"
why it will break, this is what oracle MySQL suggest us to do in this way as MySQL can't across site.
"Bottom line is the mariadb clusters do handle schema changes."
seems yes! but I forgot how.
yeah, this is brain split and we need quorum on third datacenter !
but in MariaDB, which is the quorum ?
"This can be done using garbd if you do not want to store data on the 3rd site."
what is garbd ? any URL for it ?
"If you have 2 different clusters "
SAME MariaDB cluster ACROSS 2 x different datacenter, it should be ok, right ?I know MySQL do not prefer that and PostgreSQL can't even do it.
" the replication will indeed break"
why it will break, this is what oracle MySQL suggest us to do in this way as MySQL can't across site.
"Bottom line is the mariadb clusters do handle schema changes."
seems yes! but I forgot how.
but in MariaDB, which is the quorum ?
the quroum is whichever part of the cluster contains more than half the nodes compared to the last cluster state
what is garbd ? any URL for it ?
use google and pick the first link. i'm not getting paid to help you and already pointed out not providing any basic work on your side is disrespectful.
seems yes! but I forgot how.
just run the query during non busy hours. a galera cluster will handle it gracefully though nodes will not respond during the schema change. assuming you did not hack unwanted settings by enabling rolling schema updates. if you have no idea what i'm talking about, then you did not so JUST RUN THE QUERY
ASKER
"the quroum is whichever part of the cluster contains more than half the nodes compared to the last cluster state"
so this mean all nodes still not down is the quorum ?
"As a side note, beware that a single mariadb cluster spawning two datacenters is a bad idea with a quorum based cluster."
so MariaDB is not quorum based cluster, right? it just a pool of server join together ! so should be no problem failover across site ?
"just run the query during non busy hours. a galera cluster will handle it gracefully though nodes will not respond during the schema change. a"
of course, all deployment will have down time for it but I just do not want replication break down and probably no one can troubleshoot it after that.
so if replication/cluster breaks it can't support that.
Actually I trust MariadB cluster for it.
"garbd"
are you referring to GALERA ARBITRATOR ?
so this mean all nodes still not down is the quorum ?
"As a side note, beware that a single mariadb cluster spawning two datacenters is a bad idea with a quorum based cluster."
so MariaDB is not quorum based cluster, right? it just a pool of server join together ! so should be no problem failover across site ?
"just run the query during non busy hours. a galera cluster will handle it gracefully though nodes will not respond during the schema change. a"
of course, all deployment will have down time for it but I just do not want replication break down and probably no one can troubleshoot it after that.
so if replication/cluster breaks it can't support that.
Actually I trust MariadB cluster for it.
"garbd"
are you referring to GALERA ARBITRATOR ?
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
"i'm baffled that you could be using a cluster in production without knowing for sure you know how to restart it or the implementations basics."
I setup the whole thing myself from zero, that's why I knew galera arbitrator, it is the same thing is MS quorum vote ! when 2 x out of 3 nodes is down this quorum will vote itself is 1 so number of nodes in total is 2 and more than 1.5 ! cluster still working !
galera arbitrator is in our design too. Do you know the topological diagram on where to install galera arbitrator when maxscale and mariaDB all together in 2 x diff data center?
and sure I will rest alter schema on this cluster (replication)...
I setup the whole thing myself from zero, that's why I knew galera arbitrator, it is the same thing is MS quorum vote ! when 2 x out of 3 nodes is down this quorum will vote itself is 1 so number of nodes in total is 2 and more than 1.5 ! cluster still working !
galera arbitrator is in our design too. Do you know the topological diagram on where to install galera arbitrator when maxscale and mariaDB all together in 2 x diff data center?
and sure I will rest alter schema on this cluster (replication)...
ASKER
tks all.
galera arbitrator is in our design too. Do you know the topological diagram on where to install galera arbitrator when maxscale and mariaDB all together in 2 x diff data center?
i have no experience with maxscale and do not believe using it makes a difference regarding galera or is even useful in any way with such a cluster but i may miss something.
you need a 3rd location for your garbd, and you need each locations to carry identical weights. running 3 garbds or a single one with weight 3 is a personal choice. using different per-datacenter weight is usually a bad idea.
--
note that the cluster does not behave exactly like m$ quorum. the next quorum is always half the weight of the previous total cluster weight. pulling down members one at a time will in theory not break the cluster as long as you have 2 running members, whatever the initial number of members.
ASKER
"i have no experience with maxscale and do not believe using it makes a difference regarding galera or is even useful in any way with such a cluster but i may miss something."
you seems telling me that when maxscale here galera arbitrator is no need at all. but they are different.
"you need a 3rd location for your garbd, and you need each locations to carry identical weights"
yes should use 3rd location, but is that mean install garbd on each site is not necessary ? I am thinking about HA the garbd too ! should we ?
identical weights means: e.g., 2 x mariaDB each site? but their suggestion is, odd number of nodes in total, like 3 x MariaDB node on primary site and 2 x mariaDB in DR site, so total number is 5 , odd number, right?
we will have a PoC test platform that has primary site containing:
1) 1 x maxscale
2) 2x mariaDB.
on secondary site:
1) 1 x maxscale
2) 1x mariaDB.
it will not works by your theory ... ?
"using different per-datacenter weight is usually a bad idea."
what is different per datacenter weight ?
"pulling down members one at a time will in theory not break the cluster as long as you have 2 running members, whatever the initial number of members."
?? the theory is node majority cluster, and it means 1 out of 3 is down the cluster stil runs, down 1 more will stop the cluster from running good, right? yeah, one at a time to test it but in reality, can be all together or 2 out of 3 together.
initial number of members should be matter, right? node majority, right? odd number!
"note that the cluster does not behave exactly like m$ quorum. the next quorum is always half the weight of the previous total cluster weight."
what is NEXT quroum? each cluster should have only 1 quorum, right?
you seems telling me that when maxscale here galera arbitrator is no need at all. but they are different.
"you need a 3rd location for your garbd, and you need each locations to carry identical weights"
yes should use 3rd location, but is that mean install garbd on each site is not necessary ? I am thinking about HA the garbd too ! should we ?
identical weights means: e.g., 2 x mariaDB each site? but their suggestion is, odd number of nodes in total, like 3 x MariaDB node on primary site and 2 x mariaDB in DR site, so total number is 5 , odd number, right?
we will have a PoC test platform that has primary site containing:
1) 1 x maxscale
2) 2x mariaDB.
on secondary site:
1) 1 x maxscale
2) 1x mariaDB.
it will not works by your theory ... ?
"using different per-datacenter weight is usually a bad idea."
what is different per datacenter weight ?
"pulling down members one at a time will in theory not break the cluster as long as you have 2 running members, whatever the initial number of members."
?? the theory is node majority cluster, and it means 1 out of 3 is down the cluster stil runs, down 1 more will stop the cluster from running good, right? yeah, one at a time to test it but in reality, can be all together or 2 out of 3 together.
initial number of members should be matter, right? node majority, right? odd number!
"note that the cluster does not behave exactly like m$ quorum. the next quorum is always half the weight of the previous total cluster weight."
what is NEXT quroum? each cluster should have only 1 quorum, right?
you seems telling me that when maxscale here galera arbitrator is no need at all. but they are different.
absolutely not. an arbitrator is clearly required. using maxscale has no incidence regarding those matters.
is that mean install garbd on each site is not necessary
... and pointless
I am thinking about HA the garbd too
you can but that is not really required. if the garbd fails, you'll end up with 2 working sites with weigth 6 out of 9, so you still have the quorum.
if either datacenter fails or the datacenters cannot communicate together, whichever dc sees the garbd will reach the quorum as well.
identical weights means...
i believe i told you about twice to use the same weigth for each datacenter. if you have 3 servers per dc, and a single garbd , use a weight of 3. the total weight will be 3, 6, 9... depending on the number of mariadb hosts per location.
initial number of members should be matter
NO. what counts is the last known cluster state. please do not make me repeat the same thing over and over. your theory is correct if you unplug n members at the same time as would happen if a datacenter fails.
when a member dies, after a few seconds, the cluster size changes, and that size will be used for the next quorum calculation. not like m$. and NO there is not a single cluster size which is why you can add and remove nodes easily.
ASKER
"you can but that is not really required. if the garbd fails, you'll end up with 2 working sites with weigth 6 out of 9, so you still have the quorum."
yeah ! and if one site failed and that site with garbd failed too, then really depends on DR site then...
seems unlucky!
This is my design:
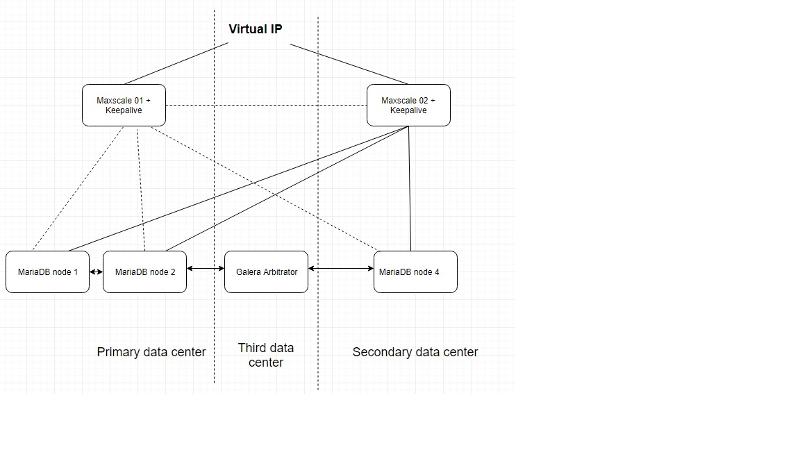
if focus on same weight per site, I will remove one maxscale and add one MariaDB node to secondary site, that one is what you meant, right?
yeah ! and if one site failed and that site with garbd failed too, then really depends on DR site then...
seems unlucky!
This is my design:
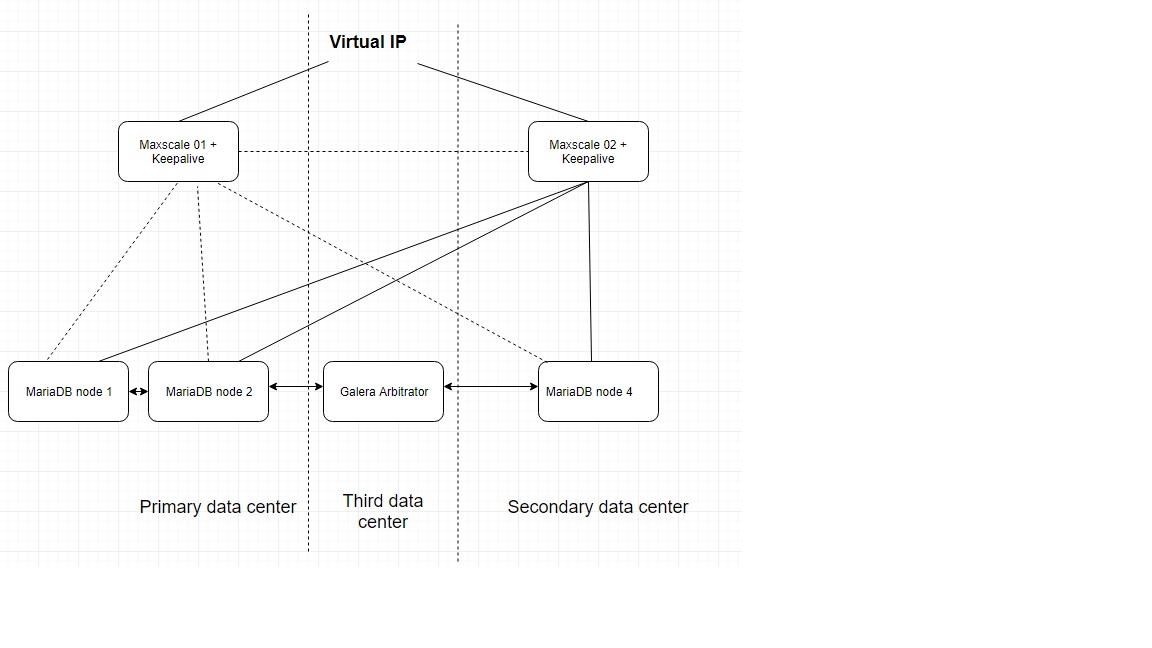
if focus on same weight per site, I will remove one maxscale and add one MariaDB node to secondary site, that one is what you meant, right?
yeah ! and if one site failed and that site with garbd failed too
yes : you can afford to loose 1 site at a time but not 2
one way to improve tolerance can be to stick multiple garbds in different locations on the internet.
another can be to cheat with the weights : use 3 per dc and 2 for garbd : if one dc fails first and garbd afterwards, the cluster will stay live. if garbd is the first to fail, and one site fails afterwards, you'll still loose all.
if you understand the algorythm, you should be able to define what happens in each scenario.
--
i thought you had 3 nodes per site. all above comments were based on that assertion.
in the above case, you probably should allocate a weight of 2 to node4 and garbd
if you keep your existing setup with or without garbd and the main site fails, the rest of the cluster will not reach quorum and will fail as well. likewise if both garbd and the backup dc go down exactly at the same time, the main site will fail as well.
if you can run 2 separate garbds in 2 separate locations, all the better. do not forget that garbd requires the same bandwidth as other nodes.
maxscale is not related to these issues in any way.
... you may want to open a dedicated thread : we're far from your original question
ASKER
"one way to improve tolerance can be to stick multiple garbds in different locations on the internet."
what you mean different location on the internet ? the cloud you mean ? so can have more than one garbds in the single cluster ?
"another can be to cheat with the weights : use 3 per dc and 2 for garbd : if one dc fails first and garbd afterwards, the cluster will stay live. if garbd is the first to fail, and one site fails afterwards, you'll still loose all."
then we will have more and more sites, seems not cheap at all but can offer really good DR.
between garbd and cluster nodes, what is the network requirement? network latency ?
"in the above case, you probably should allocate a weight of 2 to node4 and garbd"
weight of 2 seems an internal setting in the cluster? and you mean weight of 2 to both nodes?
"if you keep your existing setup with or without garbd and the main site fails, the rest of the cluster will not reach quorum and will fail as well. likewise if both garbd and the backup dc go down exactly at the same time, the main site will fail as well."
if garbd and DR site failes, I still have 2 x nodes out of 3 alive, right? why it will die ? and assuming primary site die, DR site only has one and garbd at that time say I am one of the node too, so in total 2 x node out of 3 survive and cluster keep running right?
""one way to improve tolerance can be to stick multiple garbds in different locations on the internet."
what you mean different location on the internet ? the cloud you mean ? so can have more than one garbds in the single cluster ?
"another can be to cheat with the weights : use 3 per dc and 2 for garbd : if one dc fails first and garbd afterwards, the cluster will stay live. if garbd is the first to fail, and one site fails afterwards, you'll still loose all."
then we will have more and more sites, seems not cheap at all but can offer really good DR.
between garbd and cluster nodes, what is the network requirement? network latency ?
"in the above case, you probably should allocate a weight of 2 to node4 and garbd"
weight of 2 seems an internal setting in the cluster? and you mean weight of 2 to both nodes?
"if you keep your existing setup with or without garbd and the main site fails, the rest of the cluster will not reach quorum and will fail as well. likewise if both garbd and the backup dc go down exactly at the same time, the main site will fail as well."
if garbd and DR site failes, I still have 2 x nodes out of 3 alive, right? why it will die ? and assuming primary site die, DR site only has one and garbd at that time say I am one of the node too, so in total 2 x node out of 3 survive and cluster keep running right?
"i thought you had 3 nodes per site. all above comments were based on that assertion."
latest information is we have 6x nodes so with maxscale and if I like to keep both site same weight should I say 1 x maxscale and 2 x nodes on primary site, 1 x garbd on a third DC, and 2 x mariaDB on DR site ?
what you mean different location on the internet ? the cloud you mean ? so can have more than one garbds in the single cluster ?
"another can be to cheat with the weights : use 3 per dc and 2 for garbd : if one dc fails first and garbd afterwards, the cluster will stay live. if garbd is the first to fail, and one site fails afterwards, you'll still loose all."
then we will have more and more sites, seems not cheap at all but can offer really good DR.
between garbd and cluster nodes, what is the network requirement? network latency ?
"in the above case, you probably should allocate a weight of 2 to node4 and garbd"
weight of 2 seems an internal setting in the cluster? and you mean weight of 2 to both nodes?
"if you keep your existing setup with or without garbd and the main site fails, the rest of the cluster will not reach quorum and will fail as well. likewise if both garbd and the backup dc go down exactly at the same time, the main site will fail as well."
if garbd and DR site failes, I still have 2 x nodes out of 3 alive, right? why it will die ? and assuming primary site die, DR site only has one and garbd at that time say I am one of the node too, so in total 2 x node out of 3 survive and cluster keep running right?
""one way to improve tolerance can be to stick multiple garbds in different locations on the internet."
what you mean different location on the internet ? the cloud you mean ? so can have more than one garbds in the single cluster ?
"another can be to cheat with the weights : use 3 per dc and 2 for garbd : if one dc fails first and garbd afterwards, the cluster will stay live. if garbd is the first to fail, and one site fails afterwards, you'll still loose all."
then we will have more and more sites, seems not cheap at all but can offer really good DR.
between garbd and cluster nodes, what is the network requirement? network latency ?
"in the above case, you probably should allocate a weight of 2 to node4 and garbd"
weight of 2 seems an internal setting in the cluster? and you mean weight of 2 to both nodes?
"if you keep your existing setup with or without garbd and the main site fails, the rest of the cluster will not reach quorum and will fail as well. likewise if both garbd and the backup dc go down exactly at the same time, the main site will fail as well."
if garbd and DR site failes, I still have 2 x nodes out of 3 alive, right? why it will die ? and assuming primary site die, DR site only has one and garbd at that time say I am one of the node too, so in total 2 x node out of 3 survive and cluster keep running right?
"i thought you had 3 nodes per site. all above comments were based on that assertion."
latest information is we have 6x nodes so with maxscale and if I like to keep both site same weight should I say 1 x maxscale and 2 x nodes on primary site, 1 x garbd on a third DC, and 2 x mariaDB on DR site ?
ASKER
"... you may want to open a dedicated thread : we're far from your original question"
https://www.experts-exchange.com/questions/29146868/MariaDB-HA-and-DR-architecture.html?headerLink=workspace_open_questions
https://www.experts-exchange.com/questions/29146868/MariaDB-HA-and-DR-architecture.html?headerLink=workspace_open_questions
Provide...
1) A copy of your current schema
2) Alter command you're executing
3) Explanation of what "nightmare" might mean, like time for ALTER TABLE to complete or some error where ALTER TABLE failed to run.