VMWare Host w/ESXI 6.0 (DELL R710) spontaneously rebooting? UPDATE: possible UPS, power?
Client has a DELL R710 with a the DELL custom ESXI 6.0 installed and about 4 VMs defined. It has been running fine for a couple of years, but just started behaving strangely. It seems like it is spontaneously rebooting, as I will remote in to find all the VMs off. I cannot access the iDRAC to check the the server status, and there is nothing specific to a reboot listed in the VMWare event tab. The main summary page does not show an "Uptime" status, so it is not clear how long the host has been running.
Looked the VMWare system logs, but cannot really decipher the contents well enough to make a determination.
In the Health section, all the sensors report green / normal.
Can anyone advise on how best to troubleshoot and diag?
VMWare Host w/ESXI 6.0 (DELL R710) spontaneously rebooting?
Looked the VMWare system logs, but cannot really decipher the contents well enough to make a determination.
In the Health section, all the sensors report green / normal.
Can anyone advise on how best to troubleshoot and diag?
VMWare Host w/ESXI 6.0 (DELL R710) spontaneously rebooting?
take ssh - check esxcli hardware ipmi sel list and check for hardware issues.. if nothing engage DELL for thorough hardware diagnostics
Test the memory.
Test the CPUs
Check all fans are working.
Your server is old now and needs replacing, in the future it will not support vSphere.
Test the CPUs
Check all fans are working.
Your server is old now and needs replacing, in the future it will not support vSphere.
ASKER
Agreed, but this client is cheap and perhaps not going to be in business much longer. I guarantee they are not going to buy a new server right now.
How can I tell if it is actually crashing / rebooting? With some of the ESXI servers, we get the Pink / Purple crash screen and a code. Should there be some indication in the system logs?
How can I tell if it is actually crashing / rebooting? With some of the ESXI servers, we get the Pink / Purple crash screen and a code. Should there be some indication in the system logs?
Not if it's a serious hardware fault which just causes it to reboot!
it will just reboot.
We have/had a R710 here which did just the same, and one day iDRAC Management blew up, then we got strange random errors about NMI issues on the display in PCI slot X, and then it stopped working and motherboard is shot, which reminds me really need to de-rack it and scrap it.
First thing is test the above....
and then check if the server is full loaded when it occurs, and can you reproduce the fault, does it happened hourly, daily, weekly.... or is this just a one off...
it will just reboot.
We have/had a R710 here which did just the same, and one day iDRAC Management blew up, then we got strange random errors about NMI issues on the display in PCI slot X, and then it stopped working and motherboard is shot, which reminds me really need to de-rack it and scrap it.
First thing is test the above....
and then check if the server is full loaded when it occurs, and can you reproduce the fault, does it happened hourly, daily, weekly.... or is this just a one off...
ASKER
It is happening daily. How would you recommend testing the CPU and RAM on that box?
every hardware has their own hardware diagnostics...
https://www.dell.com/support/article/us/en/04/sln283546/how-to-run-hardware-diagnostics-on-your-poweredge-server?lang=en
https://www.dell.com/support/article/us/en/04/sln283546/how-to-run-hardware-diagnostics-on-your-poweredge-server?lang=en
Why can't you access the iDRAC? That's the easiest way to get to the hardware log.
ASKER
OK. Just use the built-in BIOS diagnostics? I was thinking there might be specific boot disk or USB dongle recommendation. As for iDRAC, the customer never configured or connected it. I can go onsite.
Memtest86+ if you are struggling to find Dell diagnostics..
https://www.memtest86.com/
What are the conditions it reboots in ?
e.g. number of VMs, CPU and RAM usage, is all RAM being used.
https://www.memtest86.com/
What are the conditions it reboots in ?
e.g. number of VMs, CPU and RAM usage, is all RAM being used.
ASKER
Yeah. Know about Memtest86. Wasn't sure if there was something better.
Not sure about the conditions of the reboot. Have always been finding it after the fact. Monitoring it remotely right now in a separate window, and it is not breaking a sweat at all from a CPU & RAM standpoint.
Not sure about the conditions of the reboot. Have always been finding it after the fact. Monitoring it remotely right now in a separate window, and it is not breaking a sweat at all from a CPU & RAM standpoint.
It's whether is starts using a new RAM DIMM, e.g. total RAM in use, and then that causes a fault, because a DIMM failure.
Also take server apart and re-seat all DIMMS, FANS and CPUs
Also take server apart and re-seat all DIMMS, FANS and CPUs
ASKER
Have not been able to make it onsite yet. The location is not nearby, so I have been forced to baby it along for the past few days.
Trying to determine exactly when it happens. This AM, the host was up but all VMs were down (again). I don't believe they are set to auto-restart, but that is probably a good thing right now. The earliest items in the event tab show the listing below. Does this mean that it happened at 7:36AM today? Can I determine anything more from the system log?

Trying to determine exactly when it happens. This AM, the host was up but all VMs were down (again). I don't believe they are set to auto-restart, but that is probably a good thing right now. The earliest items in the event tab show the listing below. Does this mean that it happened at 7:36AM today? Can I determine anything more from the system log?

Host Agent started at BOOT. So i looks like 7.36am host was back up.
ASKER
The odd thing is that the server should be fairly idle at that point. The backups run and complete several hours earlier, and no one is even in the office. One would think that a spontaneous hardware reboot would occur when the host was under some stress. Could anything else be in play here? I just want to have all options on my plate when making the trek out to the site.
without a hardware diagnostic it's difficult to guess.
if it's intermittent, then check hardware, but i would also be good to update firmware and also update ESXi 6.0 to latest version.
if it's intermittent, then check hardware, but i would also be good to update firmware and also update ESXi 6.0 to latest version.
ASKER
OK. Major news flash... it is *not* rebooting. ESXi is ungracefully terminating the VMs.
Went onsite today, shut down the physical server, checked and blew out all fans and heat sinks. Everything looked OK. Configured and connected iDRAC, rebooted and left.
Watched the iDRAC page like a hawk. While all the hardware host parameters looked great, the VMs went down. I logged into the VMWare interface the ESXI was in Maintenance Mode. This is the first time I have seen this. All the times previous to this, it was not in MM - just all VMs were off.
Should I start a new thread at this point in order to approach the troubleshooting from a different angle?
Went onsite today, shut down the physical server, checked and blew out all fans and heat sinks. Everything looked OK. Configured and connected iDRAC, rebooted and left.
Watched the iDRAC page like a hawk. While all the hardware host parameters looked great, the VMs went down. I logged into the VMWare interface the ESXI was in Maintenance Mode. This is the first time I have seen this. All the times previous to this, it was not in MM - just all VMs were off.
Should I start a new thread at this point in order to approach the troubleshooting from a different angle?
Why. was the ESXi in maintenance mode, if you put a host into Maintenance Mode, if could shutdown all the VMs ?
Check VM Event logs, did they have an unexpected shutdown in logs, or a graceful shutdown?
there is a difference.
Check VM Event logs, did they have an unexpected shutdown in logs, or a graceful shutdown?
there is a difference.
ASKER
Thanks for the reply, Andrew.
I may need a second opinion on whether the machine is actually rebooting. Last night, I was thoroughly convinced, that it was not. But this AM, I am again skeptical. It sure *seems* like it is spontaneously restarting, but the IDRAC information does not provide any obvious indication.
For example here is the main log, which only shows my activity from late yesterday (no subsequent boots):
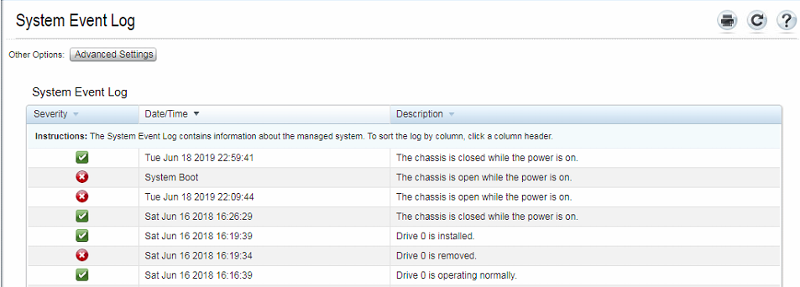
But the Boot Capture screen seems to indicate that another event did happen:
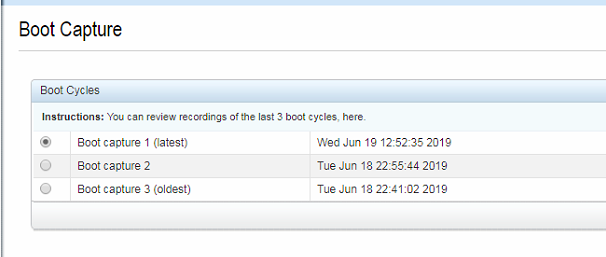
And then we have the IDRAC log that shows some sort of power issue at very similar times:
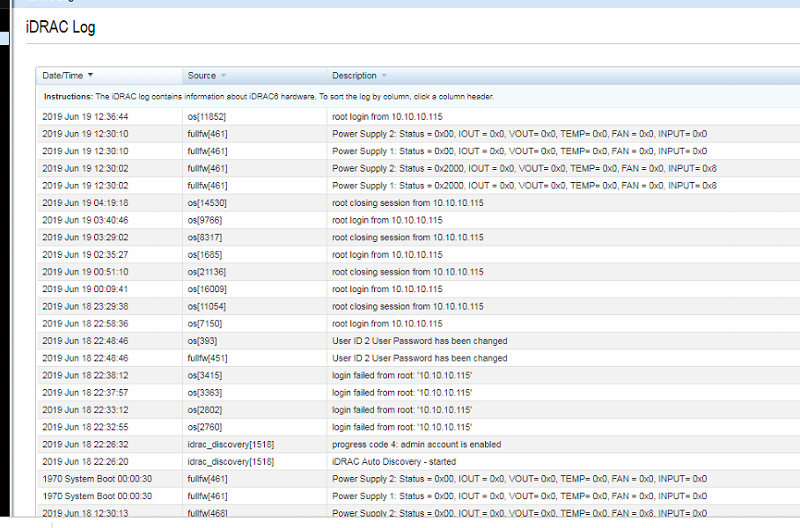
So I am wondering if this might be a UPS / Battery backup thing.....?
I may need a second opinion on whether the machine is actually rebooting. Last night, I was thoroughly convinced, that it was not. But this AM, I am again skeptical. It sure *seems* like it is spontaneously restarting, but the IDRAC information does not provide any obvious indication.
For example here is the main log, which only shows my activity from late yesterday (no subsequent boots):
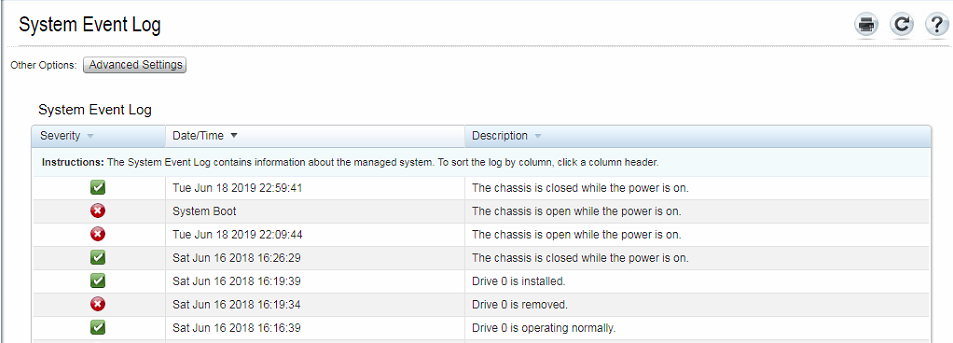
But the Boot Capture screen seems to indicate that another event did happen:
And then we have the IDRAC log that shows some sort of power issue at very similar times:
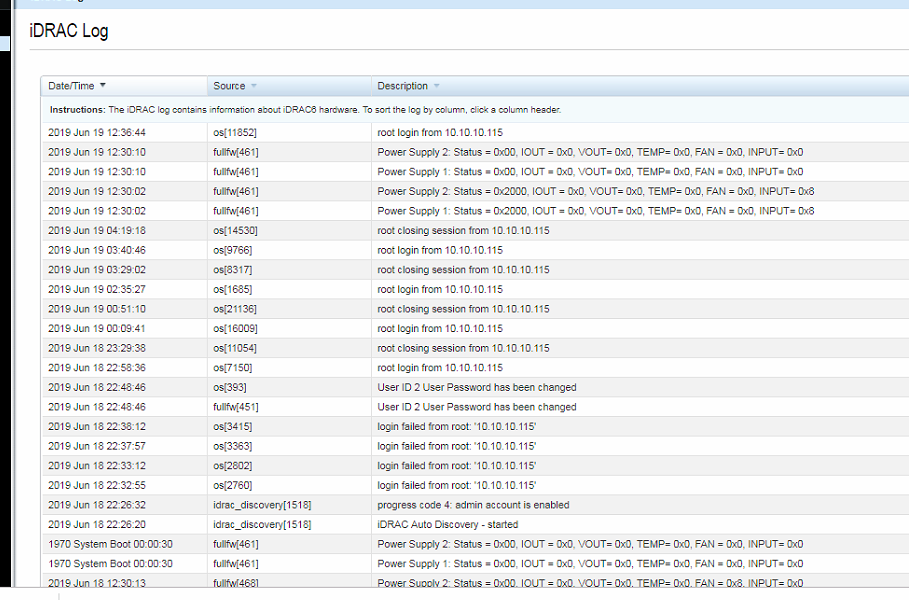
So I am wondering if this might be a UPS / Battery backup thing.....?
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
I am going to tentatively mark this as solved. After replacing the APC UPS, the system has been steady for over 7 days. Giving Andres the Solution because ..... well ... it's Andrew, and it appears that Power was indeed the culprit.
Lessons Learned:
NEVER leave a virtual host without some sort of UPS monitoring in place. I realize this fairly obvious, but the APC VIB software application was somehow removed or not reinstalled during a hardware or ESXi migration. Because of this, here was no visibility to the UPS and what exactly was going on with the machine power.
I am still very surprised that the iDRAC events did not even show that the host was rebooting. Literally there was nothing at all within that referenced the power incidents. The on things it picked up were my manual boots and the chassis being open temporarily (that second one was super useful).
Anyway, thanks - as always - for the input / assistance!
Lessons Learned:
NEVER leave a virtual host without some sort of UPS monitoring in place. I realize this fairly obvious, but the APC VIB software application was somehow removed or not reinstalled during a hardware or ESXi migration. Because of this, here was no visibility to the UPS and what exactly was going on with the machine power.
I am still very surprised that the iDRAC events did not even show that the host was rebooting. Literally there was nothing at all within that referenced the power incidents. The on things it picked up were my manual boots and the chassis being open temporarily (that second one was super useful).
Anyway, thanks - as always - for the input / assistance!
Normally with dual PSUs there's a log of one PSU losing power in the log. There isn't a log entry on single PSU systems or ones where the PSUs are fed from the same feed as no power to write the log entry.
ASKER
This r710 does have dual psu's. And you are correct. We should have plugged them into separate UPS devices. Need to add that to the lessons learned. Thanks, Andy.
Normally one feed from the UPS and one feed from mains is used if you only have one UPS.
Hope you setup the iDRAC for remote access while you were there for the next time there's a hardware fault.
Hope you setup the iDRAC for remote access while you were there for the next time there's a hardware fault.
ASKER
Yes. made the IDRAC remotely accessible immediately after all this started. Unfortunately it didn't really tell me anything.