marrowyung
asked on
How to check MySQL InnodB cluster is working fine.
hi,
our MysQL InnoDB cluster 8.0.12 has 2 nodes out of 3 shut down to save resource for other VM and now I turn them both on, but I suspect that the InnoDB cluster is not working any more:
1) how to justify the cluster status if everthing is ok ?
2) how to make the cluster work again?
3) or how to cluster resync well again?
our MysQL InnoDB cluster 8.0.12 has 2 nodes out of 3 shut down to save resource for other VM and now I turn them both on, but I suspect that the InnoDB cluster is not working any more:
1) how to justify the cluster status if everthing is ok ?
2) how to make the cluster work again?
3) or how to cluster resync well again?
ASKER
"BTW. Mysql nodes (in general: database systems) should run on raw iron not in VM's."
yes, you are right! but here they will still keep using VM anyway!
"You mention INNODB so that presumes a replication cluster:"
why say that ? MySQL will be a replication cluster if, in terms of horizontal scale out?
MariaDB also implement in this way.
"oldest transaction in the active part then you are in trouble. "
you mean if the most active part still hasn't replicated to slave and commit, then we miss that part in ALL slave ?
yes, you are right! but here they will still keep using VM anyway!
"You mention INNODB so that presumes a replication cluster:"
why say that ? MySQL will be a replication cluster if, in terms of horizontal scale out?
MariaDB also implement in this way.
"oldest transaction in the active part then you are in trouble. "
you mean if the most active part still hasn't replicated to slave and commit, then we miss that part in ALL slave ?
Try lookup NBD ( https://mariadb.com/kb/en/library/what-is-mariadb-galera-cluster/ )
this is not just replication.
And if there is a gap between logs available and needed on slaves then all slaves will have trouble.
(this is part of a possible headaches in recovery from a disaster., the other big headache is a split-brain).
this is not just replication.
And if there is a gap between logs available and needed on slaves then all slaves will have trouble.
(this is part of a possible headaches in recovery from a disaster., the other big headache is a split-brain).
ASKER
"And if there is a gap between logs available and needed on slaves then all slaves will have trouble."
it has semi-sync, much better on that !
or what do you meant ?
", the other big headache is a split-brain"
do not use even number of node on both side!
"this is part of a possible headaches in recovery from a disaster."
data not accurate you mean ?
what is NBD btw ?
"Does this help as a starter:
https://severalnines.com/database-blog/how-recover-galera-cluster-or-mysql-replication-split-brain-syndrome"
I am sorry, this one is only a theory and not steps to tell me the command and correct order to execute it.
it has semi-sync, much better on that !
or what do you meant ?
", the other big headache is a split-brain"
do not use even number of node on both side!
"this is part of a possible headaches in recovery from a disaster."
data not accurate you mean ?
what is NBD btw ?
"Does this help as a starter:
https://severalnines.com/database-blog/how-recover-galera-cluster-or-mysql-replication-split-brain-syndrome"
I am sorry, this one is only a theory and not steps to tell me the command and correct order to execute it.
ASKER
"this is not just replication."
which one you referring to :
but it didn't show how these can archive:
so are you saying MySQL innodB will have these problem but MariaDB ?
which one you referring to :
Synchronous replication
Active-active multi-master topology
Read and write to any cluster node
Automatic membership control, failed nodes drop from the cluster
Automatic node joining
True parallel replication, on row level
Direct client connections, native MariaDB look & feelbut it didn't show how these can archive:
No slave lag
No lost transactions
Both read and write scalability
Smaller client latenciesso are you saying MySQL innodB will have these problem but MariaDB ?
Mysql & MariaDB (on equivalent versions) will on par with functionality.
So anything in MySQL would be more or less the same in MariaDB.
MariaDB 10.X lost NBD clustering because they need more maintainers for it.
https://mariadb.com/kb/en/library/getting-started-with-mariadb-galera-cluster/
On setup of Galera Cluster: (MariaDB)
https://www.digitalocean.com/community/tutorials/how-to-configure-a-galera-cluster-with-mariadb-on-ubuntu-18-04-servers
On setup of NBD: (MySQL)
https://www.digitalocean.com/community/tutorials/how-to-create-a-multi-node-mysql-cluster-on-ubuntu-18-04
So anything in MySQL would be more or less the same in MariaDB.
MariaDB 10.X lost NBD clustering because they need more maintainers for it.
https://mariadb.com/kb/en/library/getting-started-with-mariadb-galera-cluster/
On setup of Galera Cluster: (MariaDB)
https://www.digitalocean.com/community/tutorials/how-to-configure-a-galera-cluster-with-mariadb-on-ubuntu-18-04-servers
On setup of NBD: (MySQL)
https://www.digitalocean.com/community/tutorials/how-to-create-a-multi-node-mysql-cluster-on-ubuntu-18-04
ASKER
hi,
I am sorry man, this question is more about any command to check the healthness of the InnoDB cluster, any ?
"Mysql & MariaDB (on equivalent versions) will on par with functionality.
So anything in MySQL would be more or less the same in MariaDB."
the way to setup the cluster already big in difference ! they are totally diff on that.
I am sorry man, this question is more about any command to check the healthness of the InnoDB cluster, any ?
"Mysql & MariaDB (on equivalent versions) will on par with functionality.
So anything in MySQL would be more or less the same in MariaDB."
the way to setup the cluster already big in difference ! they are totally diff on that.
Here is a selection of issues and how to handle them:
Mysql: (innoDB cluster).
https://dev.mysql.com/doc/refman/5.7/en/mysql-innodb-cluster-working-with-cluster.html#check-instance-state
MariaDB Master/Slave:
https://mariadb.com/kb/en/library/replication-commands/
Mysql: (innoDB cluster).
https://dev.mysql.com/doc/refman/5.7/en/mysql-innodb-cluster-working-with-cluster.html#check-instance-state
MariaDB Master/Slave:
https://mariadb.com/kb/en/library/replication-commands/
ASKER
hi,
"Mysql: (innoDB cluster).
https://dev.mysql.com/doc/refman/5.7/en/mysql-innodb-cluster-working-with-cluster.html#check-instance-state"
I switched to this :
https://dev.mysql.com/doc/refman/8.0/en/mysql-innodb-cluster-working-with-cluster.html
for MySQL cluster 8.o.x
"MariaDB Master/Slave:
https://mariadb.com/kb/en/library/replication-commands/"
tks man, I knew that for MariaDB Galera cluster.
actually what way of operation MariaDB and MySQL big difference.
"Mysql: (innoDB cluster).
https://dev.mysql.com/doc/refman/5.7/en/mysql-innodb-cluster-working-with-cluster.html#check-instance-state"
I switched to this :
https://dev.mysql.com/doc/refman/8.0/en/mysql-innodb-cluster-working-with-cluster.html
for MySQL cluster 8.o.x
"MariaDB Master/Slave:
https://mariadb.com/kb/en/library/replication-commands/"
tks man, I knew that for MariaDB Galera cluster.
actually what way of operation MariaDB and MySQL big difference.
ASKER
hi,
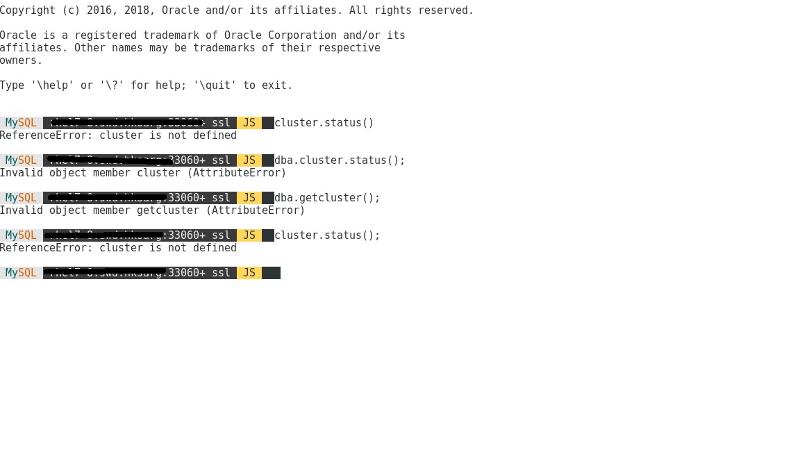
probably 2 out of 3 nodes of my InnodB Cluster down for a long time and now the cluster seems not working at all, that's why I ask this question.
and I do this:
what I got is :
where both of the followings returns that cluster is valid for all the nodes I have:
1) dba.checkInstanceConfigura
2) dba.configureInstance('roo
as I both before for all nodes it seems no need to restart at all, it do not ask for it and they both report all nodes vaild for cluster.
what is the best way to bootstrap the cluster again with all information reserved?
I also tried:
it knows all the nodes I have as it is in the configuration files and the response from mysql shell is :
so what should I do now ?
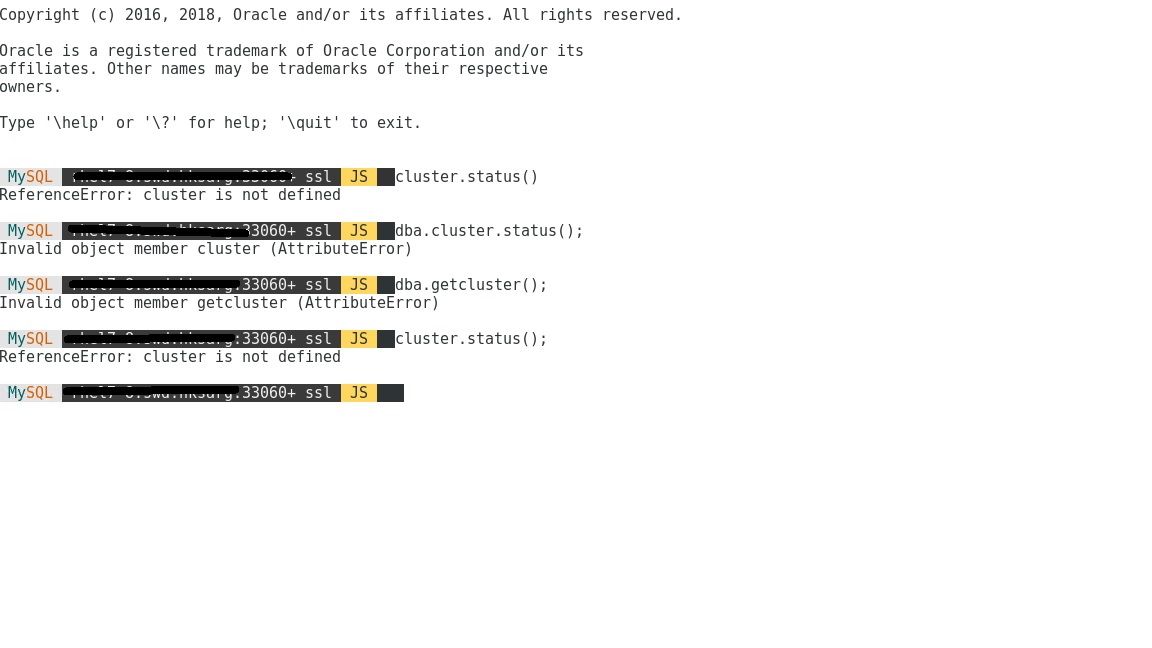
probably 2 out of 3 nodes of my InnodB Cluster down for a long time and now the cluster seems not working at all, that's why I ask this question.
and I do this:
cluster.describe();what I got is :
ReferenceError: cluster is not definedwhere both of the followings returns that cluster is valid for all the nodes I have:
1) dba.checkInstanceConfigura
2) dba.configureInstance('roo
as I both before for all nodes it seems no need to restart at all, it do not ask for it and they both report all nodes vaild for cluster.
what is the best way to bootstrap the cluster again with all information reserved?
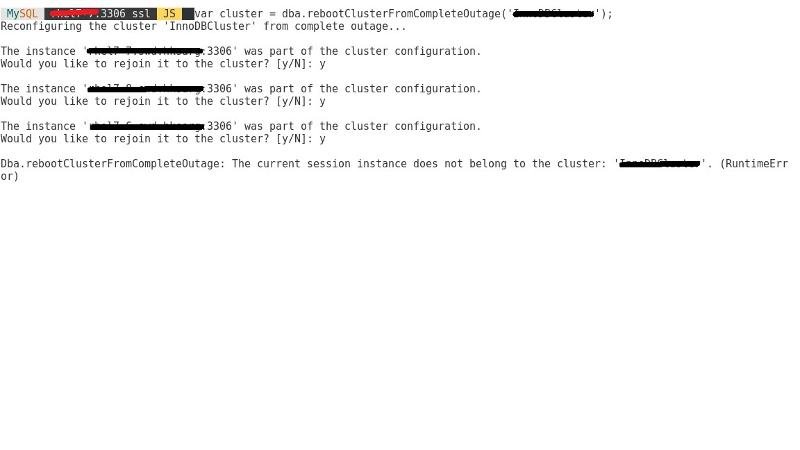
I also tried:
dba.rebootClusterFromCompleteOutage();it knows all the nodes I have as it is in the configuration files and the response from mysql shell is :
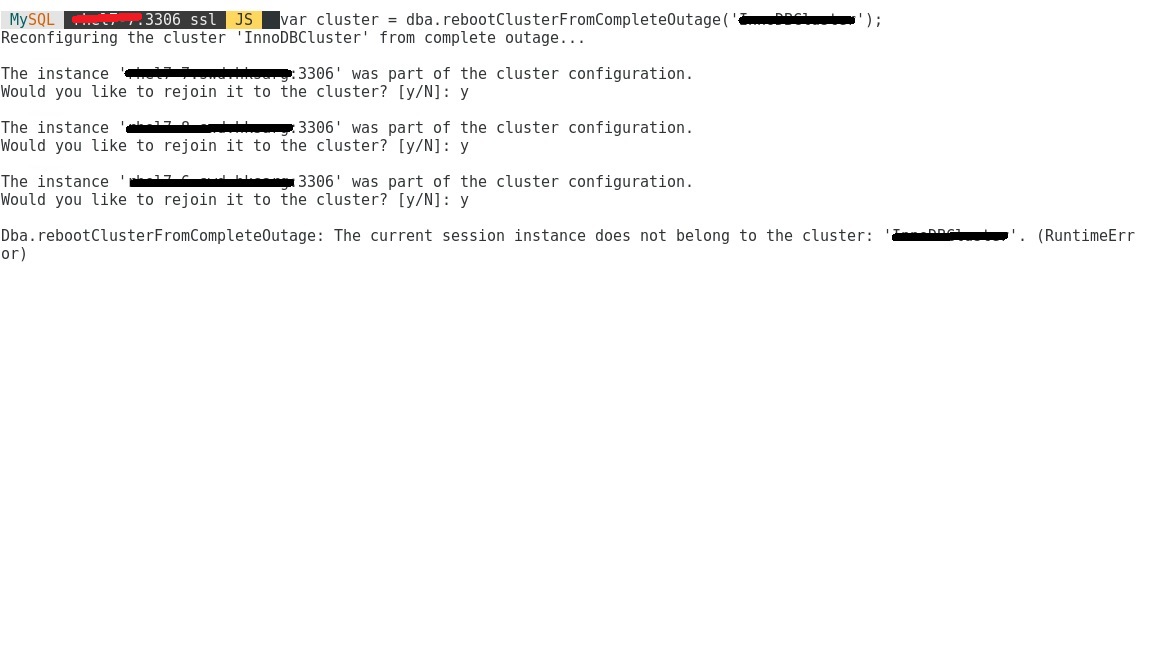
so what should I do now ?
Did you try it from the last active node?...
Also check this article:
https://mysqlserverteam.com/innodb-cluster-in-opc-part2/
See also: (slightly different case).
https://ronniethedba.wordpress.com/2017/04/23/how-to-recover-the-innodb-cluster-from-complete-outage/
Also check this article:
https://mysqlserverteam.com/innodb-cluster-in-opc-part2/
See also: (slightly different case).
https://ronniethedba.wordpress.com/2017/04/23/how-to-recover-the-innodb-cluster-from-complete-outage/
ASKER
cluster.status() has nothign return.
my screenshot said it is not belongs to a cluster right ?
my screenshot said it is not belongs to a cluster right ?
At least the remnants of a cluster are there. The "primary" node during failure should be used for the reboot (it has the most recent write transactions aka updates).
I am using mariaDB in current work env. Recent mysql did go in another direction. (I missed the v8... as i stopped checking mysql).
Anyway you are running in VM's, i think with local data? (i am not sure what what was actualy built from other questions.).
If the data is not local to the VM make a backup of all data.
If so stop the VM, copy the container (and external data if needed) to a safe place.
Important: Work on the copy in a new VM. Try to rebuild the cluster. If it starts you have a valid backup and you can rejoin the nodes. If it fails nothing is lost as the copy failed, you should be able retry other paths.
I am using mariaDB in current work env. Recent mysql did go in another direction. (I missed the v8... as i stopped checking mysql).
Anyway you are running in VM's, i think with local data? (i am not sure what what was actualy built from other questions.).
If the data is not local to the VM make a backup of all data.
If so stop the VM, copy the container (and external data if needed) to a safe place.
Important: Work on the copy in a new VM. Try to rebuild the cluster. If it starts you have a valid backup and you can rejoin the nodes. If it fails nothing is lost as the copy failed, you should be able retry other paths.
ASKER
"The "primary" node during failure should be used for the reboot (it has the most recent write transactions aka updates). "
MariaDB mention it as the most advance nodes, the last shut down nodes with latest data.
actually the same concept MySQL has but MySQL has a much complex process than MariaDB.
"I am using mariaDB in current work env. Recent mysql did go in another direction. (I missed the v8... as i stopped checking mysql)."
MySQL is not good from your option ?
"Anyway you are running in VM's, i think with local data?"
local data means ? you are saying we run that VM on top of a SAN or not ?
"Important: Work on the copy in a new VM. Try to rebuild the cluster. If it starts you have a valid backup and you can rejoin the nodes. If it fails nothing is lost as the copy failed, you should be able retry other paths."
sorry what are you suggesting ? are you worrying all data of my MySQL will lost AFTER join rejoin ?
MariaDB mention it as the most advance nodes, the last shut down nodes with latest data.
actually the same concept MySQL has but MySQL has a much complex process than MariaDB.
"I am using mariaDB in current work env. Recent mysql did go in another direction. (I missed the v8... as i stopped checking mysql)."
MySQL is not good from your option ?
"Anyway you are running in VM's, i think with local data?"
local data means ? you are saying we run that VM on top of a SAN or not ?
"Important: Work on the copy in a new VM. Try to rebuild the cluster. If it starts you have a valid backup and you can rejoin the nodes. If it fails nothing is lost as the copy failed, you should be able retry other paths."
sorry what are you suggesting ? are you worrying all data of my MySQL will lost AFTER join rejoin ?
ASKER
by the way, any way to check the current cluster name ? in case just the name has problem ?
I am not sure if this name stored in My.cnf or what ?
it seems this can help, agree ?
but it say the same name I type so this is not the cluster name problem when typing
what I tried one interest thing today is I do not create a MySQL session via another machine (the MySQL router machine) but login to one of the MySQL node and do the same thing, result is a bit diff:
on one of the nodes I do the same command and then check cluster status, message is diff now.:
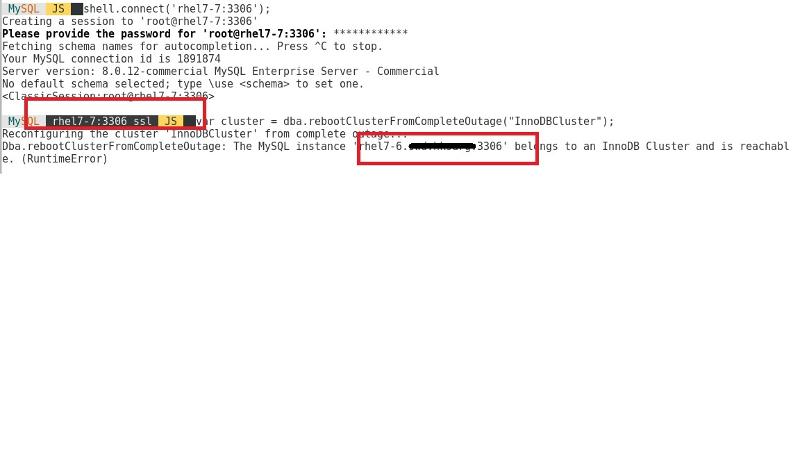
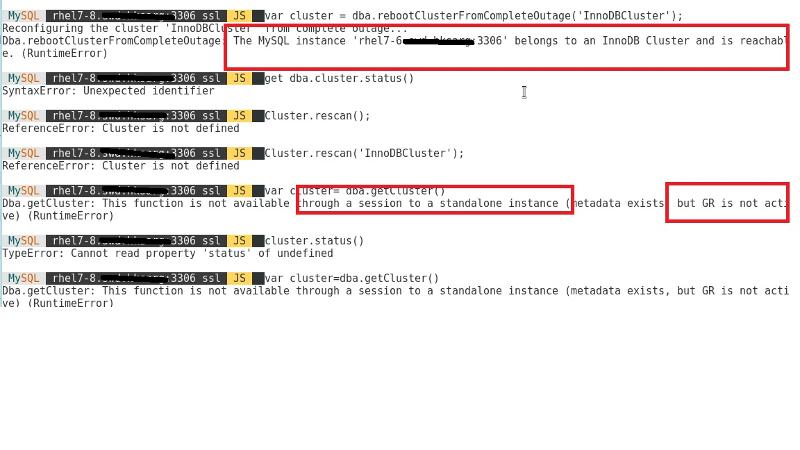
you can see that whatever nodes I shelled to and type reboot cluster again, it will say nodes 7-6 is part of cluster and cluster information is available but just GR not ready , what is that mean?
cluster status() is not working fine.
I am not sure if this name stored in My.cnf or what ?
it seems this can help, agree ?
SELECT cluster_name
FROM `mysql_innodb_cluster_metadata`.`clusters`;but it say the same name I type so this is not the cluster name problem when typing
what I tried one interest thing today is I do not create a MySQL session via another machine (the MySQL router machine) but login to one of the MySQL node and do the same thing, result is a bit diff:
on one of the nodes I do the same command and then check cluster status, message is diff now.:
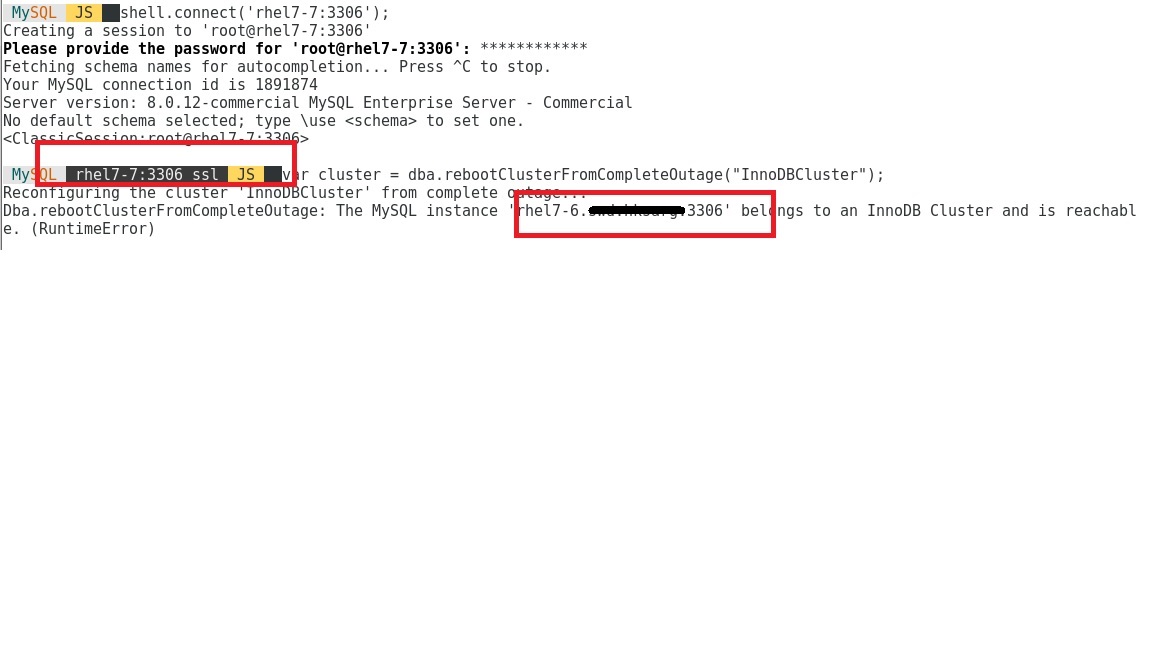
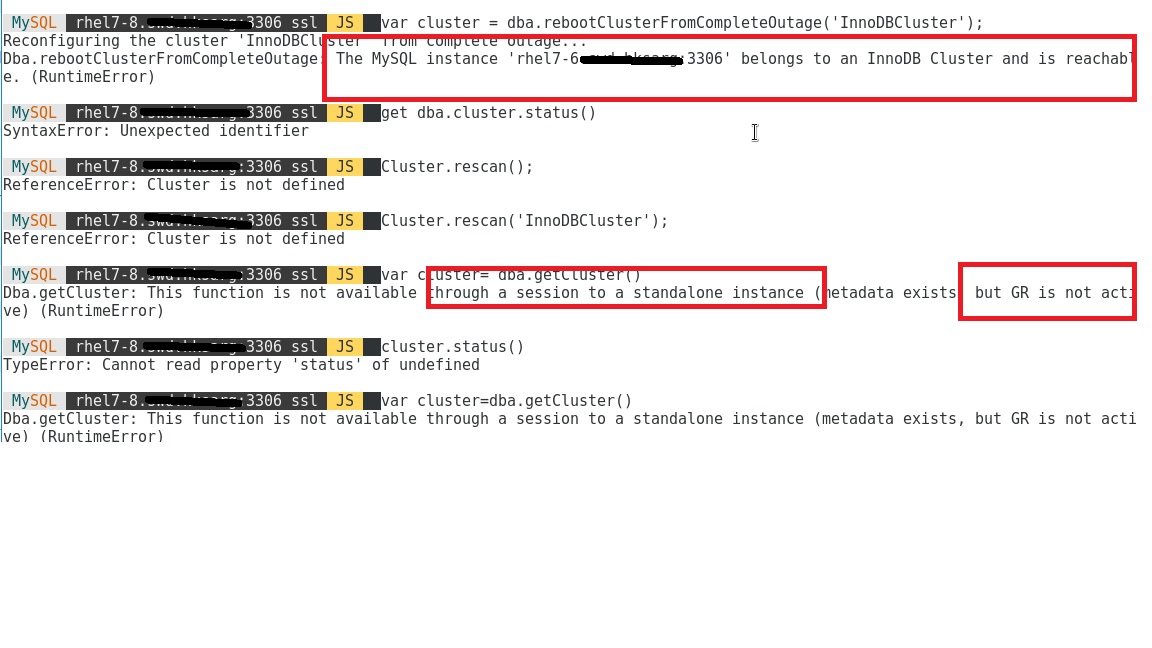
you can see that whatever nodes I shelled to and type reboot cluster again, it will say nodes 7-6 is part of cluster and cluster information is available but just GR not ready , what is that mean?
cluster status() is not working fine.
ASKER
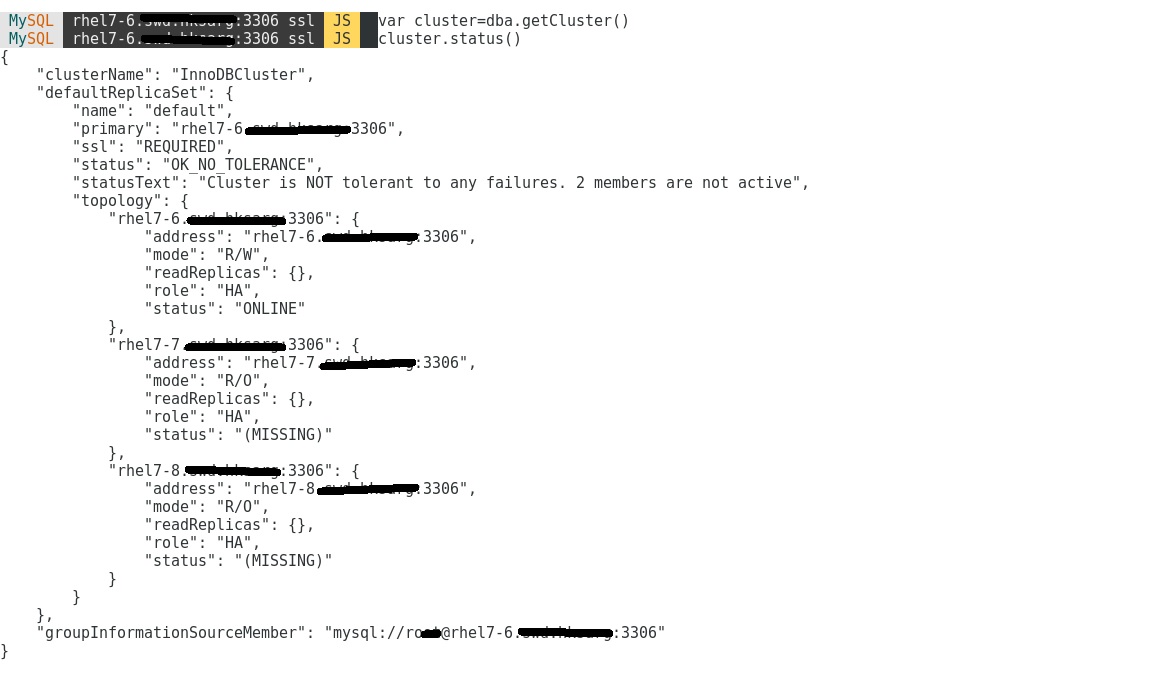
now on host rhel7-6 and I type cluster status I see this information, I think it is a good signal:
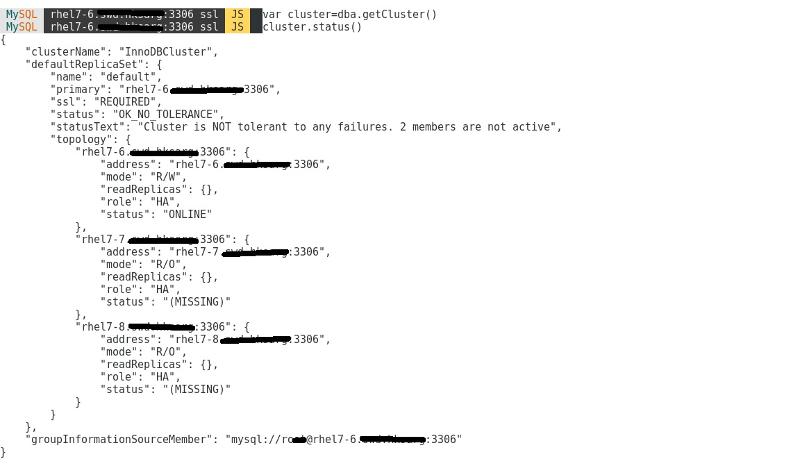
seems everything has to go thought host 7-6 ?and what is the right sytax to run cluster.rescan ?
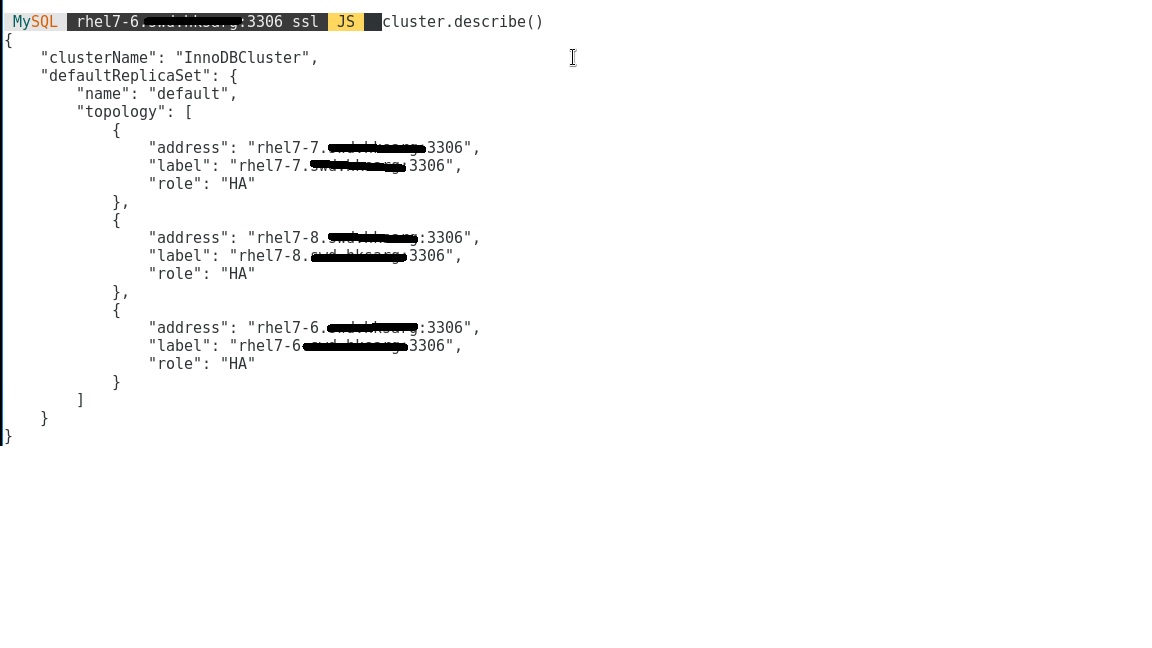
A cluster describe on 7-6 also return sth:
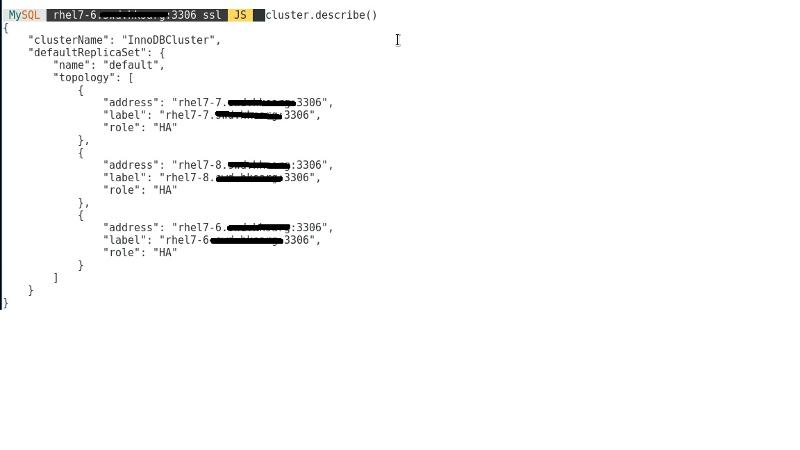
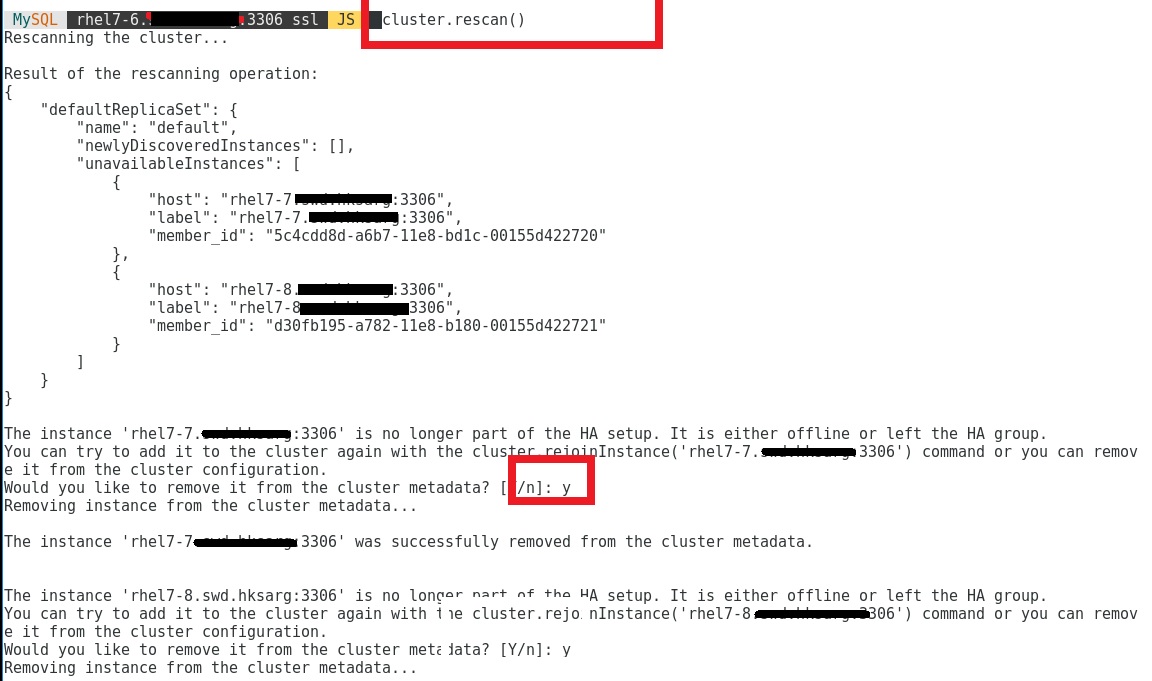
now only run cluster rescan from 7-6 can do the job:
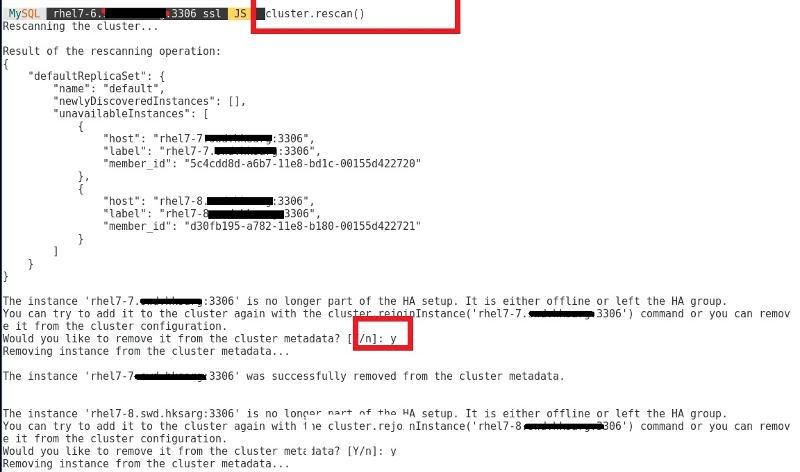
and i just answer Y to remove 7-7 and 7-8 from the cluster .
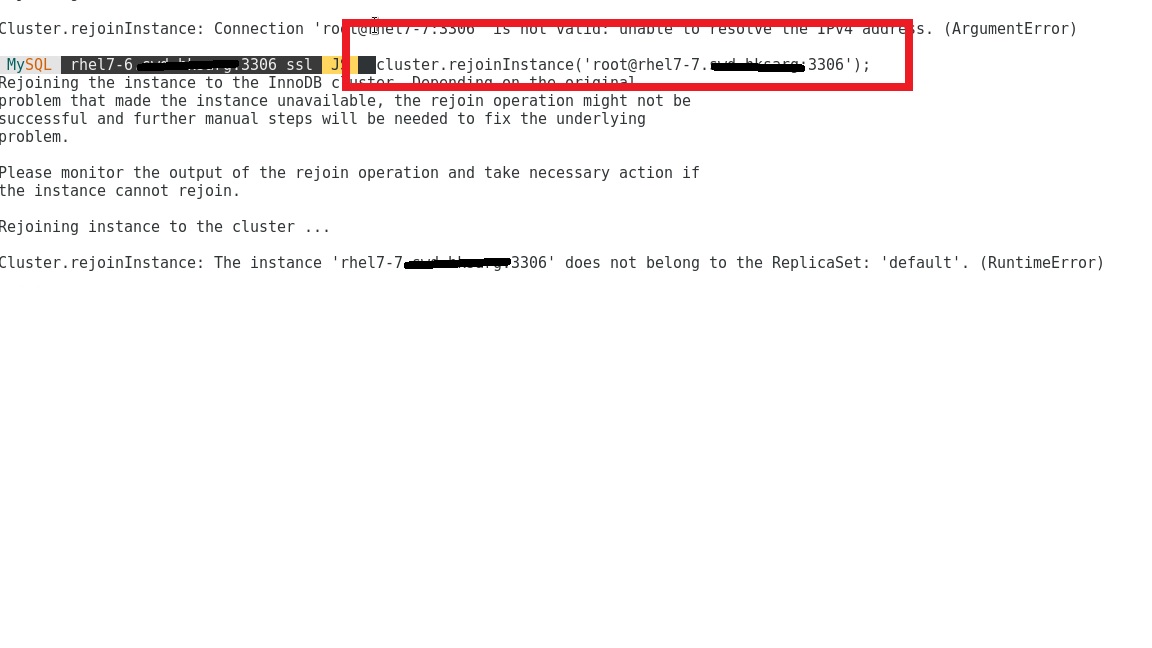
then i tried to rejoin instance using/from 7-6 and this is what got:
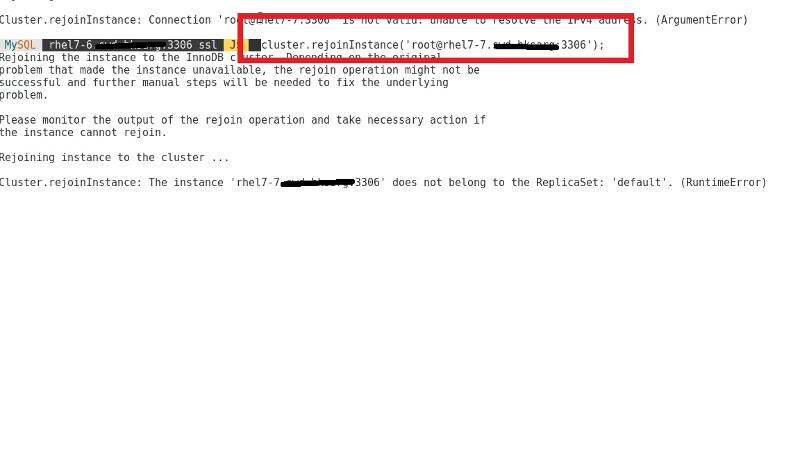
What should I do then ?
seems everything has to go thought host 7-6 ?and what is the right sytax to run cluster.rescan ?
A cluster describe on 7-6 also return sth:
now only run cluster rescan from 7-6 can do the job:
and i just answer Y to remove 7-7 and 7-8 from the cluster .
then i tried to rejoin instance using/from 7-6 and this is what got:
What should I do then ?
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
but one thing, how can I know the last standing nodes STILL part of cluster?
I don't want to trial and error to find it out by login to them one by one .
I don't want to trial and error to find it out by login to them one by one .
cluster.status should report on status (show all members, and thei status).
cluster.rescan should report on anomalies. (nodes configured, not available, ...)
cluster.rescan should report on anomalies. (nodes configured, not available, ...)
ASKER
yeah, for the aim of safety they both need.
https://severalnines.com/database-blog/how-recover-galera-cluster-or-mysql-replication-split-brain-syndrome
You mention INNODB so that presumes a replication cluster:
The cluster is synchronized using the log files. The logfiles do get rotated, so if there is a downtime long enough to get a gap between the newest transaction in the "turned off part" and oldest transaction in the active part then you are in trouble.
Probably you need to setup the slaves again.
BTW. Mysql nodes (in general: database systems) should run on raw iron not in VM's.