maqskywalker
asked on
t-sql parse comma delimited file to create table using column names found in csv file
I ‘m using SQL Server 2016 and SQL Server Management Studio.
I have a script that looks like this.
When I run this script, it exports the data from a comma delimited file and then creates a table and populates the table using BULK INSERT.
My comma delimited file I’m using for my script is called LooneyEmployees.csv I’m attaching it to this post.
If you look at LooneyEmployees.csv in a text editor like notepad it looks like this:
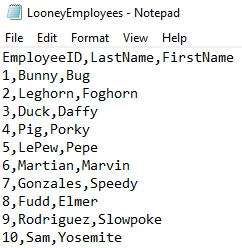
Notice how the column names are in the first row.
So when I run my script I get this. The script works fine.
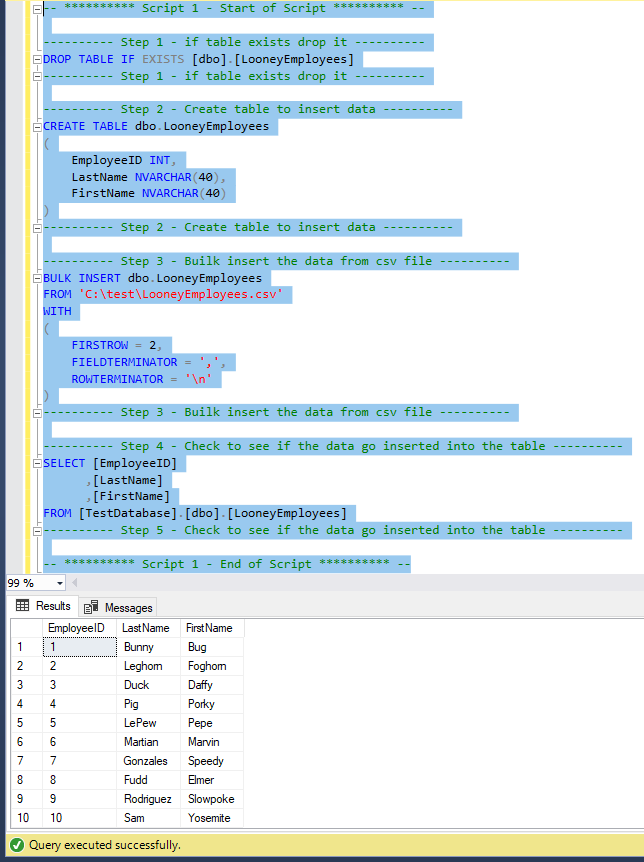
In my script, in Step 2 I create the table and declare the table columns.
Instead of declaring the columns like I am doing in Step 2, Is there a way to look at Row 1 of the CSV file and then creating the table using the column names from the column names found in Row 1 of the CSV file?
See sometimes the LooneyEmployees.csv file will look like this:
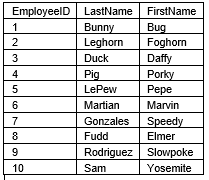
Then after week 2 the LooneyEmployees.csv file will look like this.
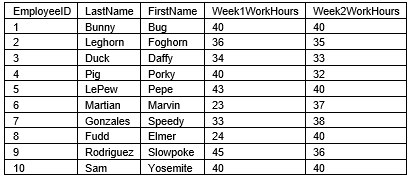
The csv will always have these fields and they will always be of this datatypes:
EmployeeID INT, LastName NVARCHAR(40), FirstName NVARCHAR(40) so I can just hard code these columns.
The only field that will change are the Hours columns and those will always be Integer columns.
LooneyEmployees.csv
LooneyEmployeesAfter2Weeks.csv
I have a script that looks like this.
-- ********** Script 1 - Start of Script ********** --
---------- Step 1 - if table exists drop it ----------
DROP TABLE IF EXISTS [dbo].[LooneyEmployees]
---------- Step 1 - if table exists drop it ----------
---------- Step 2 - Create table to insert data ----------
CREATE TABLE dbo.LooneyEmployees
(
EmployeeID INT,
LastName NVARCHAR(40),
FirstName NVARCHAR(40)
)
---------- Step 2 - Create table to insert data ----------
---------- Step 3 - Builk insert the data from csv file ----------
BULK INSERT dbo.LooneyEmployees
FROM 'C:\test\LooneyEmployees.csv'
WITH
(
FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n'
)
---------- Step 3 - Builk insert the data from csv file ----------
---------- Step 4 - Check to see if the data go inserted into the table ----------
SELECT [EmployeeID]
,[LastName]
,[FirstName]
FROM [TestDatabase].[dbo].[LooneyEmployees]
---------- Step 5 - Check to see if the data go inserted into the table ----------
-- ********** Script 1 - End of Script ********** --When I run this script, it exports the data from a comma delimited file and then creates a table and populates the table using BULK INSERT.
My comma delimited file I’m using for my script is called LooneyEmployees.csv I’m attaching it to this post.
If you look at LooneyEmployees.csv in a text editor like notepad it looks like this:
Notice how the column names are in the first row.
So when I run my script I get this. The script works fine.
In my script, in Step 2 I create the table and declare the table columns.
Instead of declaring the columns like I am doing in Step 2, Is there a way to look at Row 1 of the CSV file and then creating the table using the column names from the column names found in Row 1 of the CSV file?
See sometimes the LooneyEmployees.csv file will look like this:
Then after week 2 the LooneyEmployees.csv file will look like this.
The csv will always have these fields and they will always be of this datatypes:
EmployeeID INT, LastName NVARCHAR(40), FirstName NVARCHAR(40) so I can just hard code these columns.
The only field that will change are the Hours columns and those will always be Integer columns.
LooneyEmployees.csv
LooneyEmployeesAfter2Weeks.csv
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
Thanks for your assistance.
You should add FIELDQUOTE='"' to cover data enclosed in quotes in a field in the event there are commas that are not part of data separators.
You shoukd also include first row=2 to skip the csv header row.
Not sure if you have to do it regularly, why not use a powershell with bcp.exe