Getting Column Count and value from Table name in schema
I've tried to ask this before, but maybe I was going about it in the wrong way.
If if have this query
that will get me the table names....
Then next part I need, is a loop that will go thru each table, then go and get every column name associated with that table. It will get the count of each column for each value..... including blanks and nulls.
I'm assuming that a cursor is needed, bt i'm looking for a better way than doing this for each table, as it needs to be automated.
If if have this query
select
s.[name] 'Schema',
t.[name] 'Table',
c.[name] 'Column',
d.[name] 'Data Type'
from sys.schemas s
inner join sys.tables t
on s.schema_id = t.schema_id
inner join sys.columns c
on t.object_id = c.object_id
inner join sys.types d
on c.user_type_id = d.user_type_id
where s.name <> 'History'
and t.name not like 'CV%'
and t.name <> 'ServiceLog'
and t.name <> 'sysdiagrams'that will get me the table names....
Then next part I need, is a loop that will go thru each table, then go and get every column name associated with that table. It will get the count of each column for each value..... including blanks and nulls.
I'm assuming that a cursor is needed, bt i'm looking for a better way than doing this for each table, as it needs to be automated.
you want to count the total of columns with different dataypes?
like
nchar columns =5
int colulmns=30 etc?
like
nchar columns =5
int colulmns=30 etc?
ASKER
Not exactly,
I wasnt to display that as part of the result
so smething liek
Database
Colname
datatype
count(value) of the column
and the value of the columne
exmample: (but need to add the data type now as part of the result set)

I wasnt to display that as part of the result
so smething liek
Database
Colname
datatype
count(value) of the column
and the value of the columne
exmample: (but need to add the data type now as part of the result set)
ASKER
I have this in python, but now they've changed and are not allowing me to use python.
schema 1
table 1 has 3 columns
column 1 has N distinct values (maybe repeated)
(offmaritalstatus,offsex (in this case only 2 disctinct values)
offmaritalstatus exists 123456 times in that table1.column1
offSEX 55 times (rows) in table1.column1
same thing for every table in the schema is this correct?
so
HOW MANY TIMES EACH VALUE EXISTS IN EACH COLUMN OF EACH TABLE?
in this case column is called attribute and it can contain attributes like sex, eye color,
at least this is what I could grab from the info OP provided, if this is the cae then the value of column would be "EFFEYES" or will it be more like "EFEYES=BROWN" ?,
does every column hold different attributes?
can the same column contain more than 1 attribute ? (like gender and hair color in same column?)
table 1 has 3 columns
column 1 has N distinct values (maybe repeated)
(offmaritalstatus,offsex (in this case only 2 disctinct values)
offmaritalstatus exists 123456 times in that table1.column1
offSEX 55 times (rows) in table1.column1
same thing for every table in the schema is this correct?
so
HOW MANY TIMES EACH VALUE EXISTS IN EACH COLUMN OF EACH TABLE?
in this case column is called attribute and it can contain attributes like sex, eye color,
at least this is what I could grab from the info OP provided, if this is the cae then the value of column would be "EFFEYES" or will it be more like "EFEYES=BROWN" ?,
does every column hold different attributes?
can the same column contain more than 1 attribute ? (like gender and hair color in same column?)
if you can share the python code, we maybe be able to assist you better, as far as I can see, you dont even need a cursor, seems to me like nested selects could do what you need
ASKER
yes, the columns can hold different attributes>
but it may not say hair color, it wil just be populated with offhaircolor and ther eis another column with the actual color. btu i just want to know how many times it's populated with offhaircolor and in the above example it's 8006 the way it's displayed in the spreadsheet above is correct, i just need to know how to pupulate with those columns into another table so that the developers know how mant tiems each column is populated, and how many times each value is used.... make sense ? i think i shoudl have used another example: like below see how driverconsumedalcohol(COL) in table (DUIFIELDTET) could be Y, N or Blank ? i want those attributes with the count on every column in every table. Also, i need the data type.....
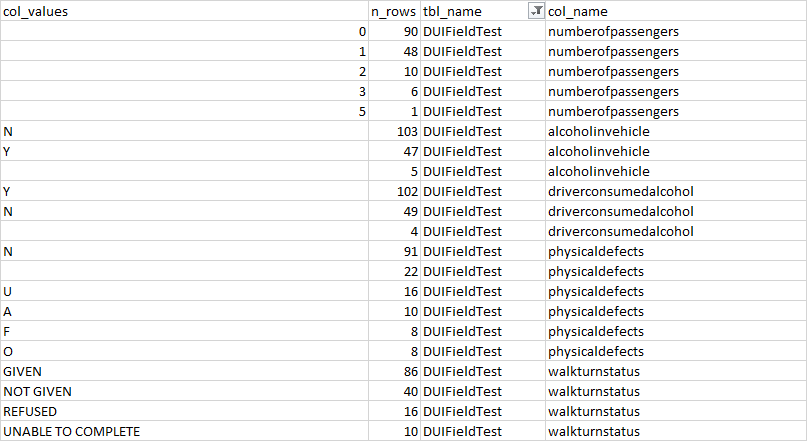
but it may not say hair color, it wil just be populated with offhaircolor and ther eis another column with the actual color. btu i just want to know how many times it's populated with offhaircolor and in the above example it's 8006 the way it's displayed in the spreadsheet above is correct, i just need to know how to pupulate with those columns into another table so that the developers know how mant tiems each column is populated, and how many times each value is used.... make sense ? i think i shoudl have used another example: like below see how driverconsumedalcohol(COL) in table (DUIFIELDTET) could be Y, N or Blank ? i want those attributes with the count on every column in every table. Also, i need the data type.....
ASKER
can you show me what those nested selects are ? i'm really stuck
ASKER
here's the python code used. with the test python as well, excuse the non comments.
# coding: utf-8
# # Load Libraries
# In[1]:
from time import sleep
import numpy as np
import pandas as pd
import pypyodbc
pypyodbc.lowercase = True
pd.set_option("display.max_rows", 200) # pd.reset_option('max_rows')
pd.set_option("display.max_columns", 200)
# pd.set_option('display.max_colwidth', 2000)
# # Globals
# In[2]:
SERVERNM = 'SQLSERVER'
DATABASE = 'Table'
SKIP_TBLS = [
'CVCaseDetail',
'CVComparisonResult',
'CVProdTableDescription',
'CVProdTableKey',
'CVProdTableSchema',
'CVRequestDetail',
'CVRequestInfo',
'CVResponseDetail',
'CVResponseInfo',
'CVSpecificRequestByCase',
'CVSpecificRequestByCaseType'
]
SKIP_COLNMS = [
'nonexisting_col'
]
# # Functions
# ## get sql
# In[3]:
def sql_get(
sql_statement: str = "select 1 as a"
, db = DATABASE, server = SERVERNM
) -> pd.core.frame.DataFrame:
"""
Send a SQL query to server and return results as a pandas data frame
"""
conn = pypyodbc.connect(
"DRIVER={0};" "SERVER={1};" "DATABASE={2};" "UID=;PWD=;".format('SQL Server', server, db)
)
output = pd.read_sql_query(sql_statement, conn)
conn.close()
if not isinstance(output, pd.core.frame.DataFrame):
raise ValueError(
"Did not receive dataframe from server for {query}".format(
query=repr(sql_statement)
)
)
return output
assert sql_get().equals(pd.DataFrame({"a": [1]})) # skeleton test
assert sql_get("select 1 as AbCd").equals(
pd.DataFrame({"abcd": [1]})
) # lowercase rule test
# ## get colnames
# In[4]:
def get_colnames(db = DATABASE, in_schema = 'dbo', tbl = 'dkt'):
"""
Return column names of a given table
"""
try:
output = sql_get(f'select top 1 * from {db}.{in_schema}.{tbl}').columns.tolist()
except Exception as e:
print(f'Warning: trying without schema...')
output = sql_get(f'select top 1 * from {tbl}').columns.tolist()
return output
assert ['dkt_id',
'case_id',
'dkt_cd',
'dkt_cd_dscr',
'dt',
'amt_owed',
'amt_paid',
'amt_dismissed',
'images_flg',
'dkt_text',
'ins_dttm',
'upd_dttm',
'modifieddatetime'] == get_colnames()
# ## get tables
# In[5]:
def get_table_names():
output = sql_get("select name from sys.tables where type = 'U' and schema_id = 1 order by name")['name'].tolist()
return output
get_table_names()
# ## get freq tbl
# In[6]:
def freq_on_col_in_tbl(
db = DATABASE, in_schema = 'dbo', tbl = 'DKT', col = 'dkt_cd'
, threshold = 1500
):
try:
n_unique_check_df = sql_get(f'select case when count(distinct {col}) < {threshold} then 1 else 0 end as n_unique_check from {db}.{in_schema}.{tbl}')
n_unique_check = n_unique_check_df.loc[0, 'n_unique_check']
if n_unique_check == 1:
output = sql_get(f'select {col} as col_values, count(*) as n_rows from {db}.{in_schema}.{tbl} group by {col} order by n_rows desc')
output['tbl_name'] = tbl
output['col_name'] = col
return output
else:
n_unique_df = sql_get(f'select count(distinct {col}) n_unique from {db}.{in_schema}.{tbl}')
n_unique = n_unique_df.loc[0, 'n_unique']
print(f'Too many (n={n_unique}) unique values found in {col} at {tbl}')
return None
except Exception as e:
print(f'Failed for {tbl} {col} due to: ({e})')
return None
freq_on_col_in_tbl()
# ## get n of blanks and nulls
# In[7]:
def get_n_blanks_null_in_tbl(
db = DATABASE, in_schema = 'dbo', tbl = 'DKT', col = 'dkt_cd'
):
try:
output = sql_get(f"select count(*) as n_rows_blank_null from {db}.{in_schema}.{tbl} where isnull(ltrim(rtrim({col})), '') = ''")
except Exception as e:
print(f'Failed for {tbl} {col} due to: ({e})')
return None
output['tbl_name'] = tbl
output['col_name'] = col
return output
get_n_blanks_null_in_tbl()
# In[8]:
get_n_blanks_null_in_tbl(db = 'SccrcDB', tbl = 'TblCaseDetail', col = 'casetype')
# ## implement all
# In[9]:
def main() -> tuple:
blanks_nulls = []
freq_tbls = []
for atbl in get_table_names():
if atbl in SKIP_TBLS:
print(f'-> Skipping tbl {atbl}')
next
else:
print(f'-- Working on table {atbl}')
for acol in get_colnames(tbl=atbl):
if acol in SKIP_COLNMS:
print(f'-> Skipping col {acol} in tbl {atbl}')
next
else:
print(f'--- Working on column {acol} in {atbl}')
sleep(0.5)
blanks_nulls.append(
get_n_blanks_null_in_tbl(tbl=atbl, col=acol)
)
sleep(0.5)
freq_tbls.append(
freq_on_col_in_tbl(col=acol, tbl=atbl)
)
print('--DONE requesting--')
# filter out nulls
blanks_nulls = [i for i in blanks_nulls if isinstance(i, pd.DataFrame)]
freq_tbls = [i for i in freq_tbls if isinstance(i, pd.DataFrame)]
# merge data files
all_blanks_nulls = pd.concat(blanks_nulls)
all_freq_tbls = pd.concat(freq_tbls)
return (blanks_nulls, freq_tbls)
# # Explore
# In[10]:
blanks_nulls = []
freq_tbls = []
# for atbl in get_table_names():
for atbl in ['ACTNCD', 'DCSNCD', 'CASEs']:
if atbl in SKIP_TBLS:
print(f'-> Skipping tbl {atbl}')
next
else:
print(f'-- Working on table {atbl}')
for acol in get_colnames(tbl=atbl):
print(f'--- Working on column {acol} in {atbl}')
# sleep(0.5)
blanks_nulls.append(
get_n_blanks_null_in_tbl(tbl=atbl, col=acol)
)
# sleep(0.5)
freq_tbls.append(
freq_on_col_in_tbl(col=acol, tbl=atbl)
)
print('--DONE--')
# In[13]:
# filter out nulls
blanks_nulls = [i for i in blanks_nulls if isinstance(i, pd.DataFrame)]
freq_tbls = [i for i in freq_tbls if isinstance(i, pd.DataFrame)]
# In[14]:
all_blanks_nulls = pd.concat(blanks_nulls)
all_freq_tbls = pd.concat(freq_tbls)
# In[16]:
all_blanks_nulls
# In[17]:
all_freq_tbls
# # Implement
# In[ ]:
blanks_nulls, freq_tbls = main()
# In[ ]:
all_freq_tbls.to_csv('frequency of values.csv')
# In[ ]:
all_blanks_nulls.to_csv('blanks and nulls occurences.csv')
ASKER
also, we are not allowed to use python in production, so that's why i have to use SQL
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
This is great! can it be tweaked, to take into account, when a column has value, blank, zero or null? and those counts ? like this pic
so if a column is populated, use has value in the column
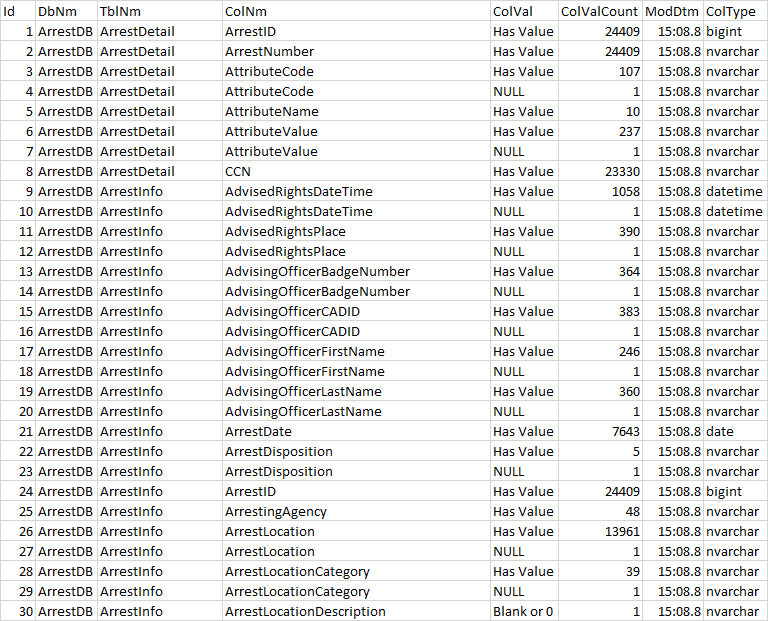
so if a column is populated, use has value in the column
Nested selects: one select inside another like excelent Ste5an Code showed
for the blanks and nulls try to replace this part to handle the nulls and blanks
Also not sure if we need DISCTINCT in the count or if it is making us not include items that should be included, try with and without DISTINCT and compare with a known good result.
here is a small set example I prepared for you on sqlfiddle using the count of nulls and blanks with and without distinct
Counting nulls and blanks with and without disctinct
for the blanks and nulls try to replace this part to handle the nulls and blanks
COUNT(DISTINCT ' + D.column_name + ') FROM ' + D.table_nameCOUNT(DISTINCT ' + coalesce(iif(D.column_name='','BLANK',D.column_name),'NULL') + ')Also not sure if we need DISCTINCT in the count or if it is making us not include items that should be included, try with and without DISTINCT and compare with a known good result.
here is a small set example I prepared for you on sqlfiddle using the count of nulls and blanks with and without distinct
Counting nulls and blanks with and without disctinct
ASKER
is it possible to put all of that together so I get it all on one result set ?
ASKER
Hi
The above statement was working before, not I get an error that says:
Msg 8117, Level 16, State 1, Line 1
Operand data type xml is invalid for count operator.
Any ideas ?
The above statement was working before, not I get an error that says:
Msg 8117, Level 16, State 1, Line 1
Operand data type xml is invalid for count operator.
Any ideas ?
There's more than one statement "above"? Post the according statement..
ASKER
Actually it was the one you wrote. I can't seem to paste it in for some reason ?
ASKER
Here it is pasted.
DECLARE @Statement NVARCHAR(MAX);
WITH Data
AS ( SELECT QUOTENAME(S.name) + '.' + QUOTENAME(T.name) AS table_name ,
QUOTENAME(C.name) AS column_name ,
QUOTENAME(DT.name) AS data_type_name
FROM sys.schemas S
INNER JOIN sys.tables T ON T.schema_id = S.schema_id
INNER JOIN sys.columns C ON C.object_id = T.object_id
INNER JOIN sys.types DT ON DT.user_type_id = C.user_type_id
WHERE S.name != 'History'
AND T.name != 'ServiceLog'
AND T.name != 'sysdiagrams'
AND T.name NOT LIKE 'CV%' )
SELECT @Statement = STUFF(
( SELECT ' UNION ALL SELECT ''' + D.table_name + ''', ''' + D.column_name + ''', ''' + D.data_type_name + ''', COUNT(DISTINCT ' + D.column_name
+ ') FROM ' + D.table_name
FROM Data D
FOR XML PATH(''), TYPE ).value('.', 'NVARCHAR(MAX)') ,
1 ,
11 ,
'');
SET @Statement = N'INSERT INTO #Counts (table_name, column_name, data_type_name, distinct_value_count) ' + @Statement + ';';
DROP TABLE IF EXISTS #Counts;
CREATE TABLE #Counts (
table_name NVARCHAR(515) ,
column_name NVARCHAR(257) ,
data_type_name NVARCHAR(257) ,
distinct_value_count INT
);
EXECUTE ( @Statement );
SELECT C.table_name ,
C.column_name ,
C.data_type_name ,
C.distinct_value_count
FROM #Counts C
ORDER BY 1 ASC ,
4 DESC ,
2 ASC;
DECLARE @Statement NVARCHAR(MAX);
WITH Data
AS ( SELECT QUOTENAME(S.name) + '.' + QUOTENAME(T.name) AS table_name ,
QUOTENAME(C.name) AS column_name ,
QUOTENAME(DT.name) AS data_type_name
FROM sys.schemas S
INNER JOIN sys.tables T ON T.schema_id = S.schema_id
INNER JOIN sys.columns C ON C.object_id = T.object_id
INNER JOIN sys.types DT ON DT.user_type_id = C.user_type_id
WHERE S.name != 'History'
AND T.name != 'ServiceLog'
AND T.name != 'sysdiagrams'
AND T.name NOT LIKE 'CV%' )
SELECT @Statement = STUFF(
( SELECT ' UNION ALL SELECT ''' + D.table_name + ''', ''' + D.column_name + ''', ''' + D.data_type_name + ''', COUNT(DISTINCT ' + D.column_name
+ ') FROM ' + D.table_name
FROM Data D
FOR XML PATH(''), TYPE ).value('.', 'NVARCHAR(MAX)') ,
1 ,
11 ,
'');
SET @Statement = N'INSERT INTO #Counts (table_name, column_name, data_type_name, distinct_value_count) ' + @Statement + ';';
DROP TABLE IF EXISTS #Counts;
CREATE TABLE #Counts (
table_name NVARCHAR(515) ,
column_name NVARCHAR(257) ,
data_type_name NVARCHAR(257) ,
distinct_value_count INT
);
EXECUTE ( @Statement );
SELECT C.table_name ,
C.column_name ,
C.data_type_name ,
C.distinct_value_count
FROM #Counts C
ORDER BY 1 ASC ,
4 DESC ,
2 ASC;
That statement runs without error here.
ASKER
could it be data type related ??
ASKER
Fixed by eliminating new columns that were of XML type.
ASKER
Open in new window
*****This is where i need the help......
--Cursor here to loop thru all the tables then columns and get a count of each type of value......
Begin
declare column_cursor for
select