Isaiah Melendez
asked on
Python CSV File Read: trailing zero truncated in read
Hello, Experts,
I am writing a program in python v 3.7x that will read a CSV file and ingest the contents of that file into a data frame and ultimately written to MySQL.
Here is a column that when I preview the CSV file (not open) you see that the DOB has the 0 as the leading 0.

When you open up the file via Numbers (MacOS) or Excel (MacOS) or read the file via the pandas 1.1.x library the leading 0 you see above is truncated.
Numbers screencap:

Excel screencap:

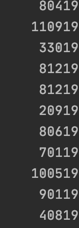
Python Read Screencap:
Python Code to read CSV:
Python code for data frame composition:
I can ultimately append the leading zeros for anything in that dob column using a conditional check that will get the length of the string in that field and anything = 7 to append a 0 in front of the dob.
Should I:
I appreciate your thoughts and suggestions in advance.
Thank you,
Isaiah
I am writing a program in python v 3.7x that will read a CSV file and ingest the contents of that file into a data frame and ultimately written to MySQL.
Here is a column that when I preview the CSV file (not open) you see that the DOB has the 0 as the leading 0.
When you open up the file via Numbers (MacOS) or Excel (MacOS) or read the file via the pandas 1.1.x library the leading 0 you see above is truncated.
Numbers screencap:
Excel screencap:
Python Read Screencap:
Python Code to read CSV:
import pandas as pd
class ReadCSV:
def __init__(self):
self.csv_file_path = '/Users/usr/Downloads/filename.csv'
self.col_names = ['uin', 'store_no', 'dba_name', 'action', 'emp_lname', 'emp_fname', 'emp_mname', 'dob', 'email', 'role', 'hire_orig_date', 'rehire_date', 'term_date']
def csvReader(self):
hireReport = pd.read_csv(self.csv_file_path, names=self.col_names, header=0, na_filter=False, encoding='utf8')
return hireReportfrom modules.db.dbconn import Connection
from modules.utils.buildDataFrame import DataFrameBuilder
from modules.utils.readCSV import ReadCSV
import pandas as pd
dbCaller = Connection()
dfCaller = DataFrameBuilder()
csvCaller = ReadCSV()
class SQLWriter:
def writeToSQL(self, df, table, engine):
df.to_sql(name=table, con=engine, index=False, if_exists='append')
return print('writing data from action csv file to MySQL...')Python code for data frame composition:
from modules.utils.readCSV import ReadCSV
import pandas as pd
import numpy as np
csvCaller = ReadCSV()
class DataFrameBuilder:
def generateActionDataFrame(self, data):
orig_df = pd.DataFrame(data=data, index=None)
df = orig_df.astype({'dob': 'object', 'hire_orig_date': 'datetime64', 'rehire_date': 'datetime64', 'term_date': 'datetime64'})
print(df.dob)
return dfI can ultimately append the leading zeros for anything in that dob column using a conditional check that will get the length of the string in that field and anything = 7 to append a 0 in front of the dob.
Should I:
- continue with the logic I explained just above? Because this is the easiest way...
- there is another way (please suggest any recommendations)
- use date data type instead for this column and format the column when reading from SQL to be mmddyyy with actually containing the 0 leading?
I appreciate your thoughts and suggestions in advance.
Thank you,
Isaiah
ASKER
@norie,
I made a copy, deleted most of the rows, and populated some sample data that was not real for obvious reasons, and resaved and the behavior is no longer there. However, this time if you preview now you no longer see the leading zero in preview, numbers, or excel.
I would share the original file with you but because of the nature of the data, it is sensitive and cannot. Hence the partial screencaps of the specific column I am writing this post about.
I made a copy, deleted most of the rows, and populated some sample data that was not real for obvious reasons, and resaved and the behavior is no longer there. However, this time if you preview now you no longer see the leading zero in preview, numbers, or excel.
I would share the original file with you but because of the nature of the data, it is sensitive and cannot. Hence the partial screencaps of the specific column I am writing this post about.
If you don't want to loose the '0', make sure the 1st column is read as a string type (and make sure that nowhere in your script teh fileds are casted to a numeric type)
The preview you have in excel can not be avoided (unless you configure the import manually), if you load the csv in excel, the 1st column is interpreted as a number, and you get it right aligned by default
The preview you have in excel can not be avoided (unless you configure the import manually), if you load the csv in excel, the 1st column is interpreted as a number, and you get it right aligned by default
Isaiah
Is the relevant column in MySQL a date column?
Is the relevant column in MySQL a date column?
ASKER
@norie,
No, I made it varchar(10). I was thinking of having the team sending me the file format it as date and then changing the schema to reflect either date or DateTime and then use a python function to format, but, did not know if this was the best course of action.
No, I made it varchar(10). I was thinking of having the team sending me the file format it as date and then changing the schema to reflect either date or DateTime and then use a python function to format, but, did not know if this was the best course of action.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
If all you want is to make sure the '0' is untouched...
I made a little test csv
I made a little test csv
foo,bar
01, 02df= pd.read_csv('test.csv', names=['foo', 'bar'], dtype={'foo': 'str', 'bar': 'float'}, header=0, na_filter=False, encoding='utf8')foo bar
01 2.0
Can you upload a sample CSV file?