Data capture of multiple text and value pairs (LAMDA content too)
=LAMBDA(INVNO,LEDGER,LET(csv,TEXTJOIN("",1,INVNO,TEXT(LEDGER,"00000000.00;-0000000.00")),csv))(A4,B4) These from the same row.
I have other texts and values to add to this string, from unspecified other rows and the values will reduce the value captured above.
Seems to me I will have to manually type those.
Any ideas?
Example:
!LEDGERSDEV-19EXTRACT.xlsx
earlier question here:
https://www.experts-exchange.com/questions/29212550/LAMBDA-and-LET-works-and-no-works-same-logic-why.html?anchor=a43268874¬ificationFollowed=268948213#a43268874
I changed your C2 and D2 formulas to:
=LAMBDA(INVNO,LEDGER,LET(Separator,",",csv,TEXTJOIN(Separator,1,INVNO,TEXT(LEDGER,"00000000.00;-0000000.00")),csv))(A2,B2)
=LAMBDA(REFS,ALLOCS,LET(Separator,",",StartHere,FIND(Separator & REFS & Separator,Separator & ALLOCS)+LEN(REFS)+LEN(Separator),NumChars,11,SUM(IFERROR(--MID(ALLOCS,StartHere,NumChars),0))))(A2,C$2:C$5)ASKER
no leading comma?
just evaluating ..
just evaluating ..
Don't know if there is a UK equivalent to this reference to an old American TV series, but: "Danger, Will Robinson. Danger."
When the number of characters in the numerical amounts vary, you need to calculate the number of digits by finding the next comma. Doing so adds a level of complexity.
When the number of characters in the numerical amounts vary, you need to calculate the number of digits by finding the next comma. Doing so adds a level of complexity.
I added the leading comma in the second LAMBDA. Kind of hidden, isn't it?
ASKER
oh yes! there is, that is why I had the fixed 11 chars created by using text formatting text,"00000.00;0000.00" (apologies for bad syntax)
edit: hidden comma, ok not got there yet, in the absence of the formula evaluator I have to copy the formula to my notepad and break it down by splitting it across lines - so it looks like "normal" code I suppose. It takes a while. ok spotted "," ah, penny just dropped, as you said a while back, add the comma in the LAMBDA not the original text.
Even an online version of the evaluator would be useful
btw there is a new series out; no polystyrene sets ;-)
edit: hidden comma, ok not got there yet, in the absence of the formula evaluator I have to copy the formula to my notepad and break it down by splitting it across lines - so it looks like "normal" code I suppose. It takes a while. ok spotted "," ah, penny just dropped, as you said a while back, add the comma in the LAMBDA not the original text.
Even an online version of the evaluator would be useful
btw there is a new series out; no polystyrene sets ;-)
ASKER
much as I have enjoyed our live engagement (most unusual on here I think), it's 1am here and tiredness is affecting my thinking - abstract thought = zero. We are of course doing the impossible, 3D spreadsheeting in 2D like in 1984.
ASKER
in fact the leading zeros 11 digits idea (to allow for values far greater than ever likely (famous last words)) is/was to avoid the counting commas or value lengths complexity.
which goes back several Questions to my static array question.
which goes back several Questions to my static array question.
It's OK to grab more characters than exist provided that you aren't stacking multiple pairs of value in a single cell. If there are multiple value pairs, you need to find the separator characters and tokenize each cell. That's why I said Danger, Will Robinson. Danger.
ASKER
yes understood, if I wasn't stacking multiple pairs in a single cell, I wouldn't be doing this as a pivot table would work nicely (as indeed do the various xxxIF type formulae. - which it does until that second allocation (second pair) when it is blind, to the second and subsequent pairs.
"tokenise", what's that? (can't sleep, raiding the fridge)
"tokenise", what's that? (can't sleep, raiding the fridge)
Tokenize means to split a text value into pieces at each occurrence of a separator character
ASKER
why is it called that? It sounds like some technique of science is in play.
https://towardsdatascience.com/an-introduction-to-tweettokenizer-for-processing-tweets-9879389f8fe7
so not blockchain, but text analysis
https://towardsdatascience.com/an-introduction-to-tweettokenizer-for-processing-tweets-9879389f8fe7
so not blockchain, but text analysis
If you concatenate a bunch of values together, breaking them apart again is sometimes referred to as producing tokens from the original text. A tokenizer is a piece of code (formula in your case) that does this.
Here is a LAMBDA that tokenizes cell C5:
=LAMBDA(text,separator,
LET(LenSep,LEN(separator),
Dummy,CHAR(1),
nTokens,LEN(text)-LEN(SUBSTITUTE(text,separator,""))+1,
TokenNum,SEQUENCE(nTokens),
End,FIND(Dummy,SUBSTITUTE(text & separator,separator,Dummy,TokenNum)),
Start,FIND(Dummy,SUBSTITUTE(separator & text,separator,Dummy,TokenNum))-LEN(Dummy),
MID(text,Start+LenSep,End-Start-LenSep))
)(C5,",")
I've hit a brick wall when applying the tokenizer to a range of cells in column C. I believe the problem is that I am needing to make an array of arrays, something that current releases of Excel cannot do.
One workaround is to use JOINTEXT to concatenate the values in column C. Then possibly use a recursive LAMBDA to search the tokens from that. I'll need to noodle on that some more.
One workaround is to use JOINTEXT to concatenate the values in column C. Then possibly use a recursive LAMBDA to search the tokens from that. I'll need to noodle on that some more.
ASKER
I need to ponder, but JOINTEXT was where I came in originally.. joining you in your noodle pot.
here's a wider context view, (your Token generator included, I changed CHAR1 because it was generating a value error), after working on it all today
!LEDGERSDEV-23reprise.xlsx
So this is the concatenator for my new sheet used to create the payment allocations. I do not want extra sheets, but it struck me I will be needing a practical way to create the amount of the payment in the first place, and that would be a very small spreadsheet, whether integral or not. All it does is add the text above to the text on current row, if either exist; straightforward formula:
and the allocator column is the same where there is one to one payment to invoice, or manually replaced with the result of the above for one-to-many splits of payments against several invoices
and the AMOUNT column, picks up every third column value to its left, i.e. transaction values. Entered as LAMBDA's name "AMOUNT(P2:AG2)"
Several running total columns use LAMBDA =XBalance(AE:AE) being:
There is now Reconciliation tab/sheet which reconciles (or not) the LEDGER Column and INVBAL columns, which is to say the total overall customer or supplier balance compared to the total of all invoices' balances added up. Should be identical, difference controls to zero.
Some other columns may not make sense because I have randomised all or most of the text in the file.
I have also tidied up the names used to match the actual column names and added the column letters to make it easier to follow.
I need to include payment references (e.g. cheque numbers) to create the audit trail, but this is low priority as regards EE questions.
The IF statement in the INVBAL column should probably be incorporated in to the LAMBDA, it is there to try to reduce the resources used when the calc is not required.
I lost my LET versions, because I broke the file and only got this far in fixing it.
Looking at reinstating those now.
here's a wider context view, (your Token generator included, I changed CHAR1 because it was generating a value error), after working on it all today
!LEDGERSDEV-23reprise.xlsx
So this is the concatenator for my new sheet used to create the payment allocations. I do not want extra sheets, but it struck me I will be needing a practical way to create the amount of the payment in the first place, and that would be a very small spreadsheet, whether integral or not. All it does is add the text above to the text on current row, if either exist; straightforward formula:
=IF(C4=C5,TEXTJOIN("",0,A4,D5,TEXT(E5,"00000000.00;-0000000.00")),TEXTJOIN("",0,D5,TEXT(E5,"00000000.00;-0000000.00")))and the allocator column is the same where there is one to one payment to invoice, or manually replaced with the result of the above for one-to-many splits of payments against several invoices
=LAMBDA(InvNo,Ledger,CONCATENATE(InvNo,TEXT(Ledger,"00000000.00;-0000000.00")))(K2,AE2)=IF(EXACT(AG2,"Invoice"),LAMBDA(Allocator_AH,LEDGER_AE,INVNO_K,SUM(IFERROR((-MID(Allocator_AH,FIND(INVNO_K,Allocator_AH)+LEN(INVNO_K),(LEN(TEXT(LEDGER_AE,"00000000.00;-0000000.00"))))),0)))(AH:AH,AE2,K2),"")and the AMOUNT column, picks up every third column value to its left, i.e. transaction values. Entered as LAMBDA's name "AMOUNT(P2:AG2)"
=LAMDA(LEDGERS,SUM(IF(MOD(COLUMN(LEDGERS)-1,3)=0,LEDGERS)))
Several running total columns use LAMBDA =XBalance(AE:AE) being:
=LAMBDA(COLUMN,-SUM(INDEX(COLUMN,1):INDEX(COLUMN,ROW())))
There is now Reconciliation tab/sheet which reconciles (or not) the LEDGER Column and INVBAL columns, which is to say the total overall customer or supplier balance compared to the total of all invoices' balances added up. Should be identical, difference controls to zero.
Some other columns may not make sense because I have randomised all or most of the text in the file.
I have also tidied up the names used to match the actual column names and added the column letters to make it easier to follow.
I need to include payment references (e.g. cheque numbers) to create the audit trail, but this is low priority as regards EE questions.
The IF statement in the INVBAL column should probably be incorporated in to the LAMBDA, it is there to try to reduce the resources used when the calc is not required.
I lost my LET versions, because I broke the file and only got this far in fixing it.
Looking at reinstating those now.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
I may be some time
My post was made prior to seeing your lengthy post earlier today. So you will need to patch my Tokens LAMBDA up, among other things.
ASKER
Struggling here with this:
any ideas? Mac Here PC there.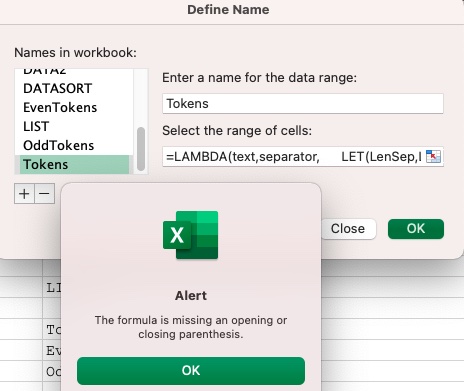
That came up when creating the name in my sheet. So i loaded it in "your" sheet and without making any changes this arose when I clicked ok
any ideas? Mac Here PC there.
That came up when creating the name in my sheet. So i loaded it in "your" sheet and without making any changes this arose when I clicked ok
ASKER
this is as far as I have got sub analysing:
Tokens
Tokens
=LAMBDA(text,separator,
LET(
LenSep,LEN(separator),Dummy,CHAR(1),
nTokens,LEN(text)-LEN(SUBSTITUTE(text,separator,""))+1,
TokenNum,SEQUENCE(nTokens),
End),
FIND(Dummy,SUBSTITUTE(text&separator,separator,Dummy,TokenNum))ASKER
-LEDGERSDEV-19EXTRACT.xlsx
I just opened this file using Mac Microsoft 365 and added sample formulas for Tokens, OddTokens and EvenTokens. Since I am running ing the same Beta Channel Mac software as you are, perhaps I made a copy & paste error when transcribing the formulas to my last post.
I just opened this file using Mac Microsoft 365 and added sample formulas for Tokens, OddTokens and EvenTokens. Since I am running ing the same Beta Channel Mac software as you are, perhaps I made a copy & paste error when transcribing the formulas to my last post.
ASKER
QED, maybe it will show up while I reverse engineer your work
p.s. I get the same error using the file you attached just there - but can't see any missing brackets
p.s. I get the same error using the file you attached just there - but can't see any missing brackets
The SUBSTITUTE function can either replace all instances of a substring or a specified instance. If you want to return a specific token, you need SUBSTITUTE to put a funny character in a place of interest (either the beginning or end of the token).
Had I used FIND(Dummy, SUBSTITUTE(separator & text, separator, Dummy, TokenNum )) I'd have gotten the beginning of the token.
FIND(Dummy,SUBSTITUTE(text&separator,separator,Dummy,TokenNum))Had I used FIND(Dummy, SUBSTITUTE(separator & text, separator, Dummy, TokenNum )) I'd have gotten the beginning of the token.
In your "sub analyzing" Comment for Tokens, I don't see the expression for Start, and the expression for End in statement 6 has a right parenthesis that doesn't belong there.
ASKER
suggest copy that reply to here:
https://www.experts-exchange.com/questions/29212669/Analyse-LAMBDA-LET-formula.html
https://www.experts-exchange.com/questions/29212669/Analyse-LAMBDA-LET-formula.html
ASKER
In your "sub analyzing" Comment for Tokens, I don't see the expression for Start, and the expression for End in statement 6 has a right parenthesis that doesn't belong there.I'll delete it, think I have, I was looking for missing brackets. Start I will look for
While the Excel MVP Community is enthusiastic about the capabilities of LAMBDA functions, suffice to say editing, testing, debugging, documenting and sharing are less awesome.
BTW, Windows Excel 2013 and later have the FILTERXML function, "abuse" of which parses delimited text into tokens with a shorter formula than the one I gave you. Alas, FILTERXML is not supported in Mac Excel.
ASKER
Well. Interesting. Is it any more difficult than a long complex formula? Strikes me that with LET and chopping it up in to chunks it becomes more readable.
Some ability to annotate would sure be useful.
Yes that lack of FILTERXML was what brought me to this.
Made me laugh, yes t I thought it was an "abuse" of FILTERXML.
Some ability to annotate would sure be useful.
Yes that lack of FILTERXML was what brought me to this.
Made me laugh, yes t I thought it was an "abuse" of FILTERXML.
ASKER
looking for start in here: https://www.experts-exchange.com/questions/29212669/Analyse-LAMBDA-LET-formula.html
ASKER
Sup001,1000,Supp004,500,supp010,25
and now I see that will need to be captured by a more complex formula in the "allocations" column. And the leading comma and maybe a trailing comma will have to be added - or maybe not the trailing as that is a value not text being searched for.