Extract Key and Value of Json String Key/Value Pairs
I have a deeply nested Json string data in a table - with IDs. I want to extract (deserialize) the Key and Values (Values should be in comma separated string if more than one Value ) of the Key/Value Pairs in the Json String in separate columns in the table using PostgreSQL or even Python - As long as the Keys and Values of the Key/Value Pairs of each row or record is extract into the separate columns side by side as shown in the excel table attached below.
I have tried to do this On Redshift using Redshift's version of PostgreSQL where my data is hosted and I have not been able to get it done, So I need your help. Thanks
ASKER
The Json_String column has the Json as it is in the database column . Its all already loaded in the database column. I will update the Excel to show what s the expected result.
ASKER
Hello slightwv,
I have provided an updated version of the excel with the Json values expected when the Json_string is flattened or deserialized.
Expert Exchange Data.xlsx
Each Excel row is a complete record with the ID column and Json_String column. The data is already in a table in Redshift , so the potential solution will run for each row and populate the Key and Value column.
I have provided an updated version of the excel with the Json values expected when the Json_string is flattened or deserialized.
Expert Exchange Data.xlsx
Each Excel row is a complete record with the ID column and Json_String column. The data is already in a table in Redshift , so the potential solution will run for each row and populate the Key and Value column.
Some questions:
Not sure how you get the single "THAT'S HOW YOU LIKE IT" when the three key values differ:
"titleValue":"THAT S HOW YOU LIKE IT"
"titleValue":"THAT'S HOW YOU LIKE IT"
"titleValue":"THATS HOW YOU LIKE IT"
Notice only one has the apostrophe.
For the next one:
{"[CISAC:23]agreedSplitAut
The entire key value is "[CISAC:23]agreedSplitAuth
Not sure how you get the single "THAT'S HOW YOU LIKE IT" when the three key values differ:
"titleValue":"THAT S HOW YOU LIKE IT"
"titleValue":"THAT'S HOW YOU LIKE IT"
"titleValue":"THATS HOW YOU LIKE IT"
Notice only one has the apostrophe.
For the next one:
{"[CISAC:23]agreedSplitAut
The entire key value is "[CISAC:23]agreedSplitAuth
ASKER
Hello slightwv,
You are perfectly correct in your last response to me . I got the Json Key Value Examples wrong . I have updated the Excel sheet now to what is expected and the rest follows the same pattern .
The idea is to identify the keys and the Values in each Json_string row or record and extract them out dynamically in a comma separated string in the Json_Value and Json_Key columns each.
Expert Exchange Data.xlsx
You are perfectly correct in your last response to me . I got the Json Key Value Examples wrong . I have updated the Excel sheet now to what is expected and the rest follows the same pattern .
The idea is to identify the keys and the Values in each Json_string row or record and extract them out dynamically in a comma separated string in the Json_Value and Json_Key columns each.
Expert Exchange Data.xlsx
ASKER
My troubleshooting ask - Does anyone have an idea of a solution in PostgreSQL or Python that can dynamically extract Values of Keys of variously deeply nested Json as in my excel, and provide the values in a comma separated string in a separate column - This is the crux of my Json problem.
I've not forgotten about this. Not sure why other Experts haven't opted to try.
I'm just at a stumbling block and not sure how to get around it without coding that I feel is unnecessary.
Also: I'm not familiar with Redshift SQL. I know conventional Postgres RDS SQL.
I also a little curious about the value of the output you want.
For example:
Value Example: THAT S HOW YOU LIKE IT,THAT'S HOW YOU LIKE IT,THATS HOW YOU LIKE IT
Key Example: Titles, AT
Not sure any possible meaning you can get from those two fields.
Even if you still want this, wouldn't' the keys for that row be:
Titles, AT, titleValue
I'm just at a stumbling block and not sure how to get around it without coding that I feel is unnecessary.
Also: I'm not familiar with Redshift SQL. I know conventional Postgres RDS SQL.
I also a little curious about the value of the output you want.
For example:
Value Example: THAT S HOW YOU LIKE IT,THAT'S HOW YOU LIKE IT,THATS HOW YOU LIKE IT
Key Example: Titles, AT
Not sure any possible meaning you can get from those two fields.
Even if you still want this, wouldn't' the keys for that row be:
Titles, AT, titleValue
ASKER
Hello slightwv,
Yes you are right with this consolidated example below:
Value Example: THAT S HOW YOU LIKE IT,THAT'S HOW YOU LIKE IT,THATS HOW YOU LIKE IT
Key Example: Titles, AT, titleValue
However, if titleValue is included in the key or not, it will work.
So that output above is okay and that applies across that other Json strings as well.
Redshift is based on PostgreSQL but AWS moved away from the regular open source PostgreSQL. If any idea is based on any version of PostgreSQL , that is acceptable.
Your help is much appreciated and I am already learning from it.
Thanks a lot.
Yes you are right with this consolidated example below:
Value Example: THAT S HOW YOU LIKE IT,THAT'S HOW YOU LIKE IT,THATS HOW YOU LIKE IT
Key Example: Titles, AT, titleValue
However, if titleValue is included in the key or not, it will work.
So that output above is okay and that applies across that other Json strings as well.
Redshift is based on PostgreSQL but AWS moved away from the regular open source PostgreSQL. If any idea is based on any version of PostgreSQL , that is acceptable.
Your help is much appreciated and I am already learning from it.
Thanks a lot.
I'm still interested in what you will be using the result for?
and need to know if normal Postgres will work for you.
From a quick google of RedShift, the regular Postgres JSON functions don't appear to be available.
If this must be redshift, then you might be suck using the Python approach.
Would like to know so I don't continue down the Postgres road.
and need to know if normal Postgres will work for you.
From a quick google of RedShift, the regular Postgres JSON functions don't appear to be available.
If this must be redshift, then you might be suck using the Python approach.
Would like to know so I don't continue down the Postgres road.
ASKER
The separated Keys and Values columns in the table will be used in a legacy application that consumes the Keys and Values as Separate columns from the table. We are not looking to change the application yet for some really cogent reasons - Hence the required to be provided as such.
Yes normal Postgres will work and Python will work too , I dont have the luxury of choosing , anyone will do and I will find a way to use it. So if your happy with Python, yes , I can run the Python in AWS Data pipeline to process into the table new columns with Key and Values.
Yes normal Postgres will work and Python will work too , I dont have the luxury of choosing , anyone will do and I will find a way to use it. So if your happy with Python, yes , I can run the Python in AWS Data pipeline to process into the table new columns with Key and Values.
Just seeing this question, but would Powershell work as well? Might not be too hard there but I haven't fully digested the entire thread yet...
»bp
»bp
ASKER
Hello Bill,
Quite open to what can work as long as it can populate results into a column in a table in database , however preferably Python or Postgres , whichever one is suited to anyone between the two.
Thanks for your help
Quite open to what can work as long as it can populate results into a column in a table in database , however preferably Python or Postgres , whichever one is suited to anyone between the two.
Thanks for your help
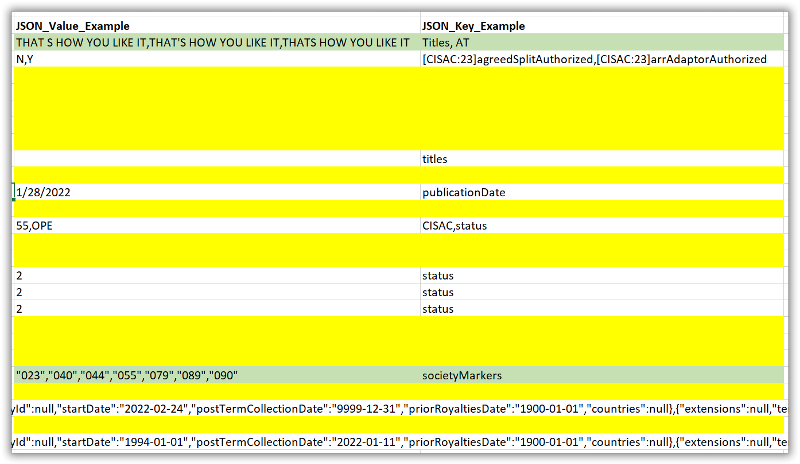
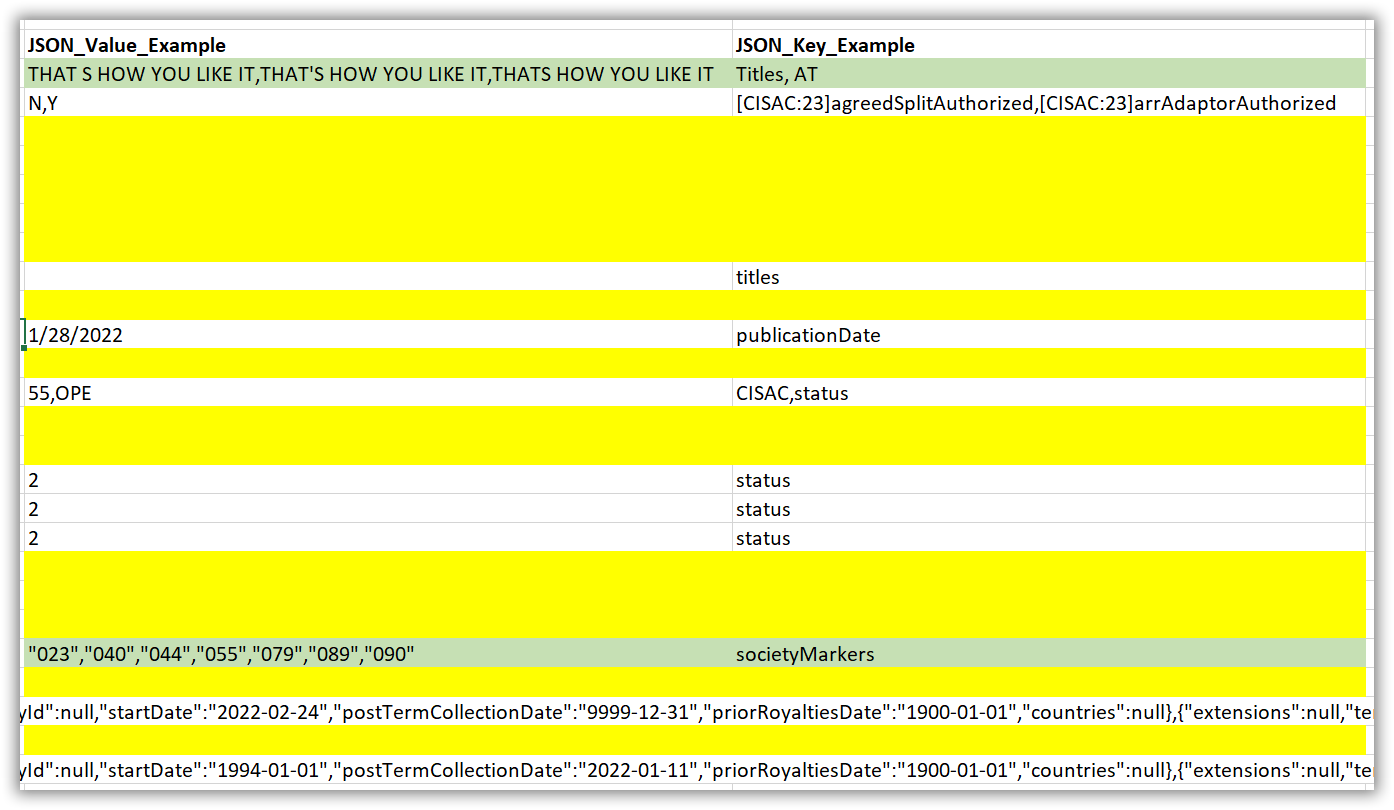
It's not clear to me what the "logic" is for extracting data from the JSON data? I can sort of guess from your Excel sheet where you populated the JSON_Value_Example and JSON_Key_Example columns, but make of the rows in those columns where there was JSON data are blank, why is that?
For example, in the image below, why are all the yellow highlighted cells empty?
Also, for the green highlighted ones, I think you are creating a problem. My expectation was that there would be a one to one correspondence between the comma delimited elements in the JSON_Value_Example and JSON_Key_Example columns. But in these cases, you have created entries there where the number of comma delimited elements in those two columns does not match. This seems like it will cause a problem when loading into the database, since it will be impossible to map the right value to the right key.
»bp
For example, in the image below, why are all the yellow highlighted cells empty?
Also, for the green highlighted ones, I think you are creating a problem. My expectation was that there would be a one to one correspondence between the comma delimited elements in the JSON_Value_Example and JSON_Key_Example columns. But in these cases, you have created entries there where the number of comma delimited elements in those two columns does not match. This seems like it will cause a problem when loading into the database, since it will be impossible to map the right value to the right key.
»bp
ASKER
Hello Bill,
The ones in Yellow are the Json strings that I did not provide example JSON_value and JSON_Key ; I provided random example output but did not for every row.
Row 25 and 27 are just long Json strings that is part of the Json data , if you expand the excel columns to the right you will see the rest of it.
This is the difficulty of this issue , there is no one to one match between the Keys and the Values , and the idea is not to map the Keys and Value output in the separate columns as a one to one match - dont worry about that . Its just to output the keys and values to their respective columns regardless of if they map one to one or not - Just the values and keys in a column from the JSON string .
The ones in Yellow are the Json strings that I did not provide example JSON_value and JSON_Key ; I provided random example output but did not for every row.
Row 25 and 27 are just long Json strings that is part of the Json data , if you expand the excel columns to the right you will see the rest of it.
This is the difficulty of this issue , there is no one to one match between the Keys and the Values , and the idea is not to map the Keys and Value output in the separate columns as a one to one match - dont worry about that . Its just to output the keys and values to their respective columns regardless of if they map one to one or not - Just the values and keys in a column from the JSON string .
Shouldn't this JSON:
{"[CISAC:55]status":["OPE"
Yield:
Key: [CISAC:55]status
Value: OPE
»bp
{"[CISAC:55]status":["OPE"
Yield:
Key: [CISAC:55]status
Value: OPE
»bp
ASKER
Hello Bill,
The example you just highlight above is correct. I made some mistakes in my examples in the sheet, however corrected now.
Expert-Exchange-Data.xlsx
Thanks
The example you just highlight above is correct. I made some mistakes in my examples in the sheet, however corrected now.
Expert-Exchange-Data.xlsx
Thanks
ASKER
I think the very long Json string examples on Row 25 and 27 can actually be ignored if there is a solution for the other ones.
Disclaimers:
-I'm pretty new to Python so I'm sure there are some better ways to do some of this.
-Given previous confusions about the actual expected results provided then changed:
I didn't walk through all your expected results to confirm they are all the same.
Setup:
Create a file named test.json with the following contents:
I created a bash script called parse.py:
Saved and ran.
-I'm pretty new to Python so I'm sure there are some better ways to do some of this.
-Given previous confusions about the actual expected results provided then changed:
I didn't walk through all your expected results to confirm they are all the same.
Setup:
Create a file named test.json with the following contents:
{"titles":{"AT":[{"titleValue":"THAT S HOW YOU LIKE IT"},{"titleValue":"THAT'S HOW YOU LIKE IT"},{"titleValue":"THATS HOW YOU LIKE IT"}]}}
{"[CISAC:23]agreedSplitAuthorized":["N"],"[CISAC:23]arrAdaptorAuthorized":["Y"]}
{"termTerritory":{"tisDate":"2022-02-12","inExTisns":["+2136"],"countries":null}}
{"[CISAC:23]agreedSplitAuthorized":["N"],"[CISAC:23]arrAdaptorAuthorized":["Y"]}
{"[CISAC:23]agreedSplitAuthorized":["N"],"[CISAC:23]arrAdaptorAuthorized":["N"]}
{"grading":[{"gradingStatus":null,"gradingDecider":null,"gradingDate":null,"gradingValue":"b"}]}
{"[CISAC:23]agreedSplitAuthorized":["Y"],"[CISAC:23]arrAdaptorAuthorized":["N"]}
{"titles":{}}
{"[CISAC:23]agreedSplitAuthorized":["Y"],"[CISAC:23]arrAdaptorAuthorized":["Y"]}
{"publicationDate":"2022-01-28"}
{"instruments":[{"numberOfPlayers":1,"numberOfInstruments":2,"instrumentCode":"ACC"}]}
{"[CISAC:55]status":["OPE"]}
{"[CISAC:23]arrAdaptorAuthorized":["N"]}
{"societyMarkers":["035","040","044","055","089","090"]}
{"status":"2"}
{"status":"2"}
{"status":"2"}
{"titles":{"UT":[{"titleValue":"Title-ICEQA-WW004723531000"}]}}
{"[CISAC:23]arrAdaptorAuthorized":["Y"]}
{"status":"2"}
{"societyMarkers":["023","040","044","055","079","089","090"]}
{"termTerritory":{"tisDate":"2022-02-24","inExTisns":["+724"],"countries":null}}
{"shares":[{"extensions":null,"territories":["+724"],"shareIn":10000,"endDate":"9999-12-31","shareOut":5000,"rights":["ER","MP","OB","OD","PC","PR","PT","RB","RT","TB","TO","TP","TV"],"societyId":null,"startDate":"2022-02-24","postTermCollectionDate":"9999-12-31","priorRoyaltiesDate":"1900-01-01","countries":null},{"extensions":null,"territories":["+724"],"shareIn":10000,"endDate":"9999-12-31","shareOut":10000,"rights":["BT","MA","MB","MD","MR","MT","MV","RL","SY"],"societyId":null,"startDate":"2022-02-24","postTermCollectionDate":"9999-12-31","priorRoyaltiesDate":"1900-01-01","countries":null}]}
{"titles":{"AT":[{"titleValue":"$20 FOR BOBAN"}]}}
{"shares":[{"extensions":null,"territories":["+372"],"shareIn":10000,"endDate":"2022-01-11","shareOut":5000,"rights":["ER","MP","OB","OD","PC","PR","PT","RB","RT","TB","TO","TP","TV"],"societyId":null,"startDate":"1994-01-01","postTermCollectionDate":"2022-01-11","priorRoyaltiesDate":"1900-01-01","countries":null},{"extensions":null,"territories":["+616"],"shareIn":10000,"endDate":"2022-01-25","shareOut":5000,"rights":["ER","MP","OB","OD","PC","PR","PT","RB","RT","TB","TO","TP","TV"],"societyId":null,"startDate":"1994-01-01","postTermCollectionDate":"2022-01-26","priorRoyaltiesDate":"1900-01-01","countries":null},{"extensions":null,"territories":["+2136","-372","-616"],"shareIn":10000,"endDate":"2022-01-11","shareOut":5000,"rights":["ER","MP","OB","OD","PC","PR","PT","RB","RT","TB","TO","TP","TV"],"societyId":null,"startDate":"1994-01-01","postTermCollectionDate":"2022-01-11","priorRoyaltiesDate":"1900-01-01","countries":null},{"extensions":null,"territories":["+372"],"shareIn":10000,"endDate":"2022-01-11","shareOut":10000,"rights":["BT","MA","MB","MD","MR","MT","MV","RL","SY"],"societyId":null,"startDate":"1994-01-01","postTermCollectionDate":"2022-01-11","priorRoyaltiesDate":"1900-01-01","countries":null},{"extensions":null,"territories":["+616"],"shareIn":10000,"endDate":"2022-01-25","shareOut":10000,"rights":["BT","MA","MB","MD","MR","MT","MV","RL","SY"],"societyId":null,"startDate":"1994-01-01","postTermCollectionDate":"2022-01-26","priorRoyaltiesDate":"1900-01-01","countries":null},{"extensions":null,"territories":["+2136","-372","-616"],"shareIn":10000,"endDate":"2022-01-11","shareOut":10000,"rights":["BT","MA","MB","MD","MR","MT","MV","RL","SY"],"societyId":null,"startDate":"1994-01-01","postTermCollectionDate":"2022-01-11","priorRoyaltiesDate":"1900-01-01","countries":null}]}
{"[CISAC:23]agreedSplitAuthorized":["N"],"[CISAC:23]arrAdaptorAuthorized":["N"]}I created a bash script called parse.py:
#!/usr/bin/env python3
import json
def parse_json_object(json_object):
for key, value in json_object.items():
all_keys.append(key)
if isinstance(value, str):
all_values.append(value)
if isinstance(value, dict):
parse_json_object(value)
elif isinstance(value, list):
parse_json_array(value)
def parse_json_array(json_array):
for data in json_array:
if isinstance(data, dict):
parse_json_object(data)
elif isinstance(data, list):
parse_json_array(data)
file1 = open('test.json', 'r')
Lines = file1.readlines()
for line in Lines:
all_keys=[]
all_values=[]
raw_json=json.loads(line)
if isinstance(raw_json, dict):
parse_json_object(raw_json)
elif isinstance(raw_json, list):
parse_json_array(raw_json)
print("keys:", ", ".join(set(all_keys)))
print("values", ", ".join(all_values))
print("--------------------------------------------------")Saved and ran.
This is funny, I was working on the same thing today, and we seem to have worked in similar paths. I haven't fully digested your version, or the results, but here is where mine stands right now.
I was inspired by these sources:
*** RESULTS ***
I was inspired by these sources:
- iterate through nested JSON object and get values with Python - Stack Overflow
- Extract Nested Data From Complex JSON
import json
def json_extract(obj):
arrVal = []
arrKey = {}
def extract(obj, arrKey, arrVal):
if isinstance(obj, dict):
for k, v in obj.items():
arrKey[k] = None
if isinstance(v, (dict, list)):
extract(v, arrKey, arrVal)
else:
arrVal.append(v)
elif isinstance(obj, list):
for item in obj:
extract(item, arrKey, arrVal)
else:
arrVal.append(obj)
return arrKey, arrVal
values = extract(obj, arrKey, arrVal)
return values
tests = ('{"status":"2"}',
'{"societyMarkers":["023","040","044","055","079","089","090"]}',
'{"[CISAC:23]agreedSplitAuthorized":["N"],"[CISAC:23]arrAdaptorAuthorized":["Y"]}',
'{"titles":{"AT":[{"titleValue":"THAT S HOW YOU LIKE IT"},{"titleValue":"THAT\'S HOW YOU LIKE IT"},{"titleValue":"THATS HOW YOU LIKE IT"}]}}',
'{"instruments":[{"numberOfPlayers":1,"numberOfInstruments":2,"instrumentCode":"ACC"}]}'
)
for test in tests:
jObject = json.loads(test)
r = json_extract(jObject)
print ('json => ', end = '')
print (jObject)
print ('keys => ', end = '')
print (list(r[0].keys()))
print ('vals => ', end = '')
print (r[1])
print ('------------------------------------------------------------------')*** RESULTS ***
json => {'status': '2'}
keys => ['status']
vals => ['2']
------------------------------------------------------------------
json => {'societyMarkers': ['023', '040', '044', '055', '079', '089', '090']}
keys => ['societyMarkers']
vals => ['023', '040', '044', '055', '079', '089', '090']
------------------------------------------------------------------
json => {'[CISAC:23]agreedSplitAuthorized': ['N'], '[CISAC:23]arrAdaptorAuthorized': ['Y']}
keys => ['[CISAC:23]agreedSplitAuthorized', '[CISAC:23]arrAdaptorAuthorized']
vals => ['N', 'Y']
------------------------------------------------------------------
json => {'titles': {'AT': [{'titleValue': 'THAT S HOW YOU LIKE IT'}, {'titleValue': "THAT'S HOW YOU LIKE IT"}, {'titleValue': 'THATS HOW YOU LIKE IT'}]}}
keys => ['titles', 'AT', 'titleValue']
vals => ['THAT S HOW YOU LIKE IT', "THAT'S HOW YOU LIKE IT", 'THATS HOW YOU LIKE IT']
------------------------------------------------------------------
json => {'instruments': [{'numberOfPlayers': 1, 'numberOfInstruments': 2, 'instrumentCode': 'ACC'}]}
keys => ['instruments', 'numberOfPlayers', 'numberOfInstruments', 'instrumentCode']
vals => [1, 2, 'ACC']
------------------------------------------------------------------
Need to knock off for the day, but I adjusted my approach and slightwv's a bit (no functional changes, just labeling in output, and including the json test strings there) so they are easier to compare the results of. I suspect neither is going to be the final result, but in interest of collaboration this felt useful. Attaching the two python scripts, and the corresponding results in a test here.
EE29234126_billprew.py
EE29234126_slightwv.py
results_billprew.txt
results_slightwv.txt
EE29234126_billprew.py
EE29234126_slightwv.py
results_billprew.txt
results_slightwv.txt
@Bill,
No problems from my end.
I do like how you got around the part I hated about mine: Repeating the isinstance code 3 times!
I tell myself and people here all the time: If you see the same code more than, you are doing it wrong!
Didn't feel like taking the time to make it smarter. Glad I didn't because I probably would not have come up with your approach!
No problems from my end.
I do like how you got around the part I hated about mine: Repeating the isinstance code 3 times!
I tell myself and people here all the time: If you see the same code more than, you are doing it wrong!
Didn't feel like taking the time to make it smarter. Glad I didn't because I probably would not have come up with your approach!
Recursion often makes my head spin a bit, but it can be a useful tool. I think both our codes are not a final version, so it's good we can maybe learn from both and get to a best approach.
(I'm not a very experienced python coder at this point...)
»bp
(I'm not a very experienced python coder at this point...)
»bp
ASKER
Wow !!! Two potential solutions at the same time . This is really promising guys . Thank you !!!.
I need to see how to process with these scripts and get the resulting Keys and Values in a table column format alongside their original Json_strings and also the IDs in the sample data.
Thanks for these great ideas.
I need to see how to process with these scripts and get the resulting Keys and Values in a table column format alongside their original Json_strings and also the IDs in the sample data.
Thanks for these great ideas.
>>get the resulting Keys and Values in a table column format alongside their original Json_strings and also the IDs in the sample data
It is all in the prints. However you read in the id and json, just put them all in the same print of however you will be outputting them.
Since you mention Redshift, I'm guessing AWS. Can I assume you want Python so you can use this in a Lambda call?
The more information you can provide us, the more detailed our responses.
It is all in the prints. However you read in the id and json, just put them all in the same print of however you will be outputting them.
Since you mention Redshift, I'm guessing AWS. Can I assume you want Python so you can use this in a Lambda call?
The more information you can provide us, the more detailed our responses.
ASKER
Yes I am going to process using AWS but using Data Pipeline where I will run the Python script to process the Json_String and return the extracted Key Value data into the table column before final usage.
Hopefully this gives you a good starting point, let us know any questions.
»bp
»bp
ASKER
Yes It does give me a very good starting point and is well acceptable
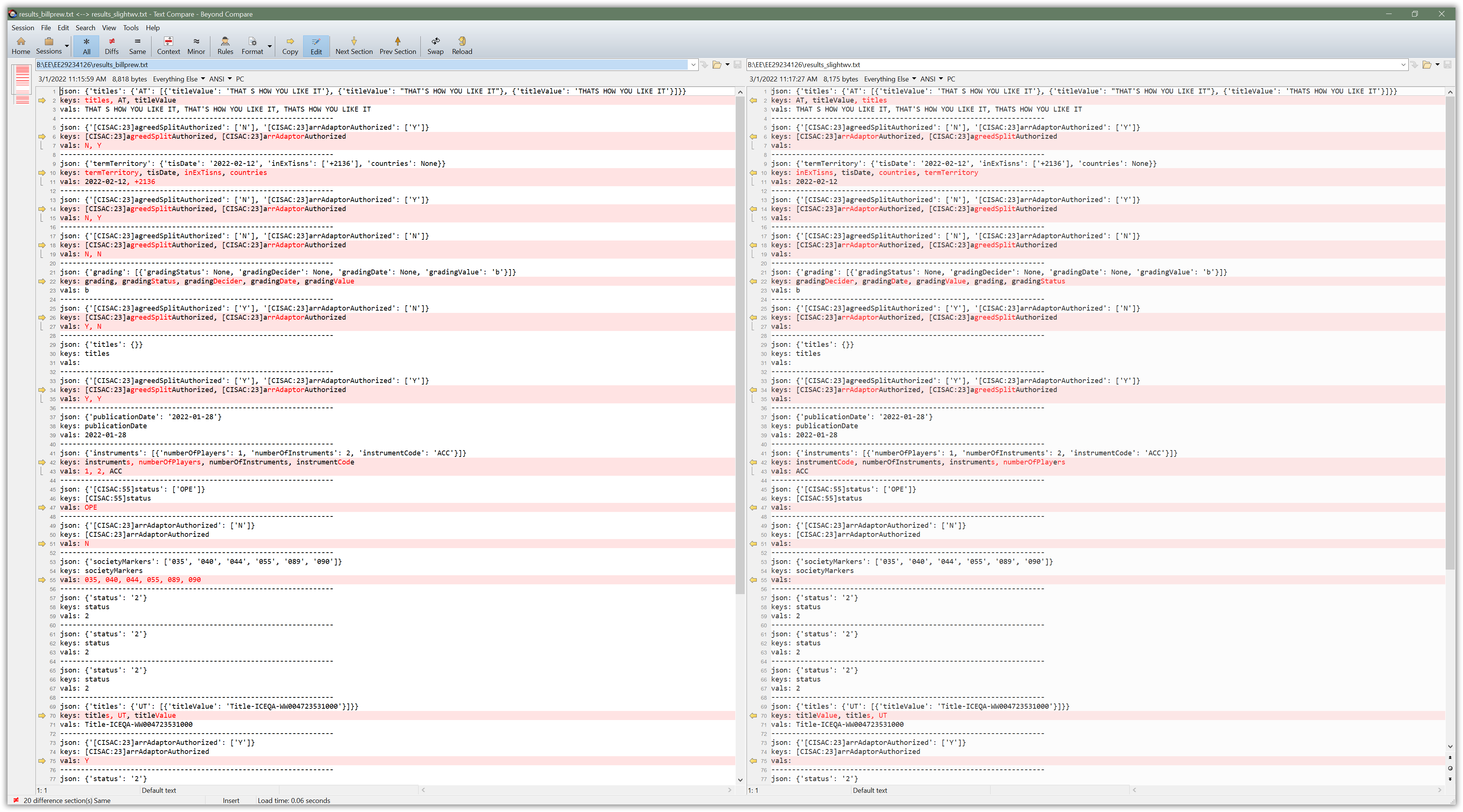
Tweaked a few things to get the outputs more the same so they can be compared side by side (I use Beyond Compare, WinMerge also another good tool) to see the differences in the two approaches. Can't say which is right or wrong, but hope this helps a little more.
EE29234126_billprew.py
EE29234126_slightwv.py
results_billprew.txt
results_slightwv.txt
test.json
EE29234126_billprew.py
EE29234126_slightwv.py
results_billprew.txt
results_slightwv.txt
test.json
Well, I would say yours is probably correct since I'm obviously missing some of the N/Y values.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
I'm not sure Excel was the best method to give us sample data. I see several JSON fragments in it's own cell. Is that what you have in Postgres? Multiple rows?
Is the JSON already in Postgres or were you trying to load it into Postgres in an attempt to parse it?
Once parsed, what are you going to do wit with results?
Please calirfy your actual JSON format(all in one column of one row) or multiple fragments in multiple rows as it appears in Excel.
Can you provide the expected results from the sample data you provided?