I need to JOIN two tables based on not-quite-matching (seconds/milliseconds) time stamps
I'm working with an industrial system that is collecting data from a wide variety of sources and, in this case, samples are collected at 10-second intervals. However, not all inputs are received at the SAME 10-second interval, leaving me at a loss as to how to perform JOINs. In this case, I need to JOIN two tables based on the their t_stamp values.
Example data from table a:
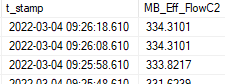 Example data from table b:
Example data from table b:
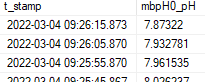 Both t_stamp values share the same year, month, day, hour and minute, but there's no way to get the seconds to line up.
Both t_stamp values share the same year, month, day, hour and minute, but there's no way to get the seconds to line up.
Is there a way to join the two t_stamp columns based on the nearest/closest-matching seconds value?
ste5an
I would generate a sequence number with ROW_NUMBER() for the JOIN instead of using the time stamps directly.
Typically you use MIN(ABS(<time_difference>)) to match up rows like that.
The only issue is the potential overhead with that, so you'll want to be sure that you have an index that can be used to do the join, preferably a completely covering index.
What is the max variance in time you will allow to consider rows to be matched? For example, if one monitoring system stops providing results for some reason, how long before you say a match can't be made?
The only issue is the potential overhead with that, so you'll want to be sure that you have an index that can be used to do the join, preferably a completely covering index.
What is the max variance in time you will allow to consider rows to be matched? For example, if one monitoring system stops providing results for some reason, how long before you say a match can't be made?
ASKER
Scott,
I suppose the max variance would be +/- 4 seconds? I'm having a hard time wrapping my brain around how to avoid incorrectly associating leading/lagging records. If I can get any rows to return, I can start dealing with how to minimize that issue, I think.
In the example data, the difference between samples is approximately three seconds.
Regarding the indexing, I'm going to need to read up on how to do that, as I only dunk my head in the SQL ocean when I can't do a task in the logic controller. Any suggested articles beyond the obvious TechNet stuff would be welcome.
Thanks!
I suppose the max variance would be +/- 4 seconds? I'm having a hard time wrapping my brain around how to avoid incorrectly associating leading/lagging records. If I can get any rows to return, I can start dealing with how to minimize that issue, I think.
In the example data, the difference between samples is approximately three seconds.
Regarding the indexing, I'm going to need to read up on how to do that, as I only dunk my head in the SQL ocean when I can't do a task in the logic controller. Any suggested articles beyond the obvious TechNet stuff would be welcome.
Thanks!
ASKER
Here's the testing query I've been working on, if it helps. I was trying to zero out the seconds, but couldn't get it to work and it wasn't really a proper solution anyway:
SELECT
a.t_stamp
,CASE
WHEN b.MB_Eff_FlowC2 = 0
THEN 0
ELSE a.mbpH0_pH
END AS pH
, b.MB_Eff_FlowC2 AS "Flow Rate"
FROM dbo.V4_Sensors AS a
INNER JOIN dbo.C2_10_sec AS b
ON DATEADD(minute, DATEDIFF(second,0,a.t_stamp),0) = DATEADD(second, DATEDIFF(minute,0,b. t_stamp),0)
WHERE a.t_stamp > '2022-03-01 00:00:00'
AND a.t_stamp < '2022-03-04 00:00:00'
ORDER BY a.t_stamp
SELECT a.t_stamp, a.MB_Eff_RowC2, b.t_stamp, b.mbpH0_pH /*...*/
FROM dbo.tablea a
OUTER APPLY (
SELECT TOP (1) *
FROM dbo.tableb b
WHERE b.t_stamp BETWEEN DATEADD(SECOND, -4, a.t_stamp) AND DATEADD(SECOND, +4, a.t_stamp)
ORDER BY MIN(ABS(DATEDIFF(MS, a.t_stamp, b.t_stamp)))
) AS b
FROM dbo.tablea a
OUTER APPLY (
SELECT TOP (1) *
FROM dbo.tableb b
WHERE b.t_stamp BETWEEN DATEADD(SECOND, -4, a.t_stamp) AND DATEADD(SECOND, +4, a.t_stamp)
ORDER BY MIN(ABS(DATEDIFF(MS, a.t_stamp, b.t_stamp)))
) AS b
Oops, just now saw your last post. Hopefully you can restructure my code to apply to that example. If not, I can be back a little later today to help write it up.
ASKER
I'm giving it a shot.
ASKER
I'm lost. I can't seem to avoid the error:
Msg 8124, Level 16, State 1, Line 18
Multiple columns are specified in an aggregated expression containing an outer reference.
Here's where I left off:
Msg 8124, Level 16, State 1, Line 18
Multiple columns are specified in an aggregated expression containing an outer reference.
Here's where I left off:
SELECT
a.t_stamp
,CASE
WHEN b.MB_Eff_FlowC2 = 0
THEN 0
ELSE a.mbpH0_pH
END AS pH
, b.MB_Eff_FlowC2 AS "Flow Rate"
FROM dbo.V4_Sensors AS a
OUTER APPLY (
SELECT TOP (1) *
FROM dbo.C2_10_sec b
WHERE b.t_stamp BETWEEN DATEADD(SECOND, -4, a.t_stamp) AND DATEADD(SECOND, +4, a.t_stamp)
ORDER BY MIN(ABS(DATEDIFF(MS, a.t_stamp, b.t_stamp)))
) AS b
WHERE a.t_stamp > '2022-03-01 00:00:00'
AND a.t_stamp < '2022-03-04 00:00:00'
ORDER BY a.t_stampASKER
I also feel like there still needs to be a JOIN somewhere. So confused...
Hmm, yeah, the MIN will cause an issue there, I should have thought of that. Let's just get rid of the MIN.
ASKER
I do see (reading...) that an OUTER APPLY is like an LEFT INNER JOIN, kind of. So, maybe not?
...
OUTER APPLY ( ...
ORDER BY ABS(DATEDIFF(MS, a.t_stamp, b.t_stamp))
) AS b
...
OUTER APPLY ( ...
ORDER BY ABS(DATEDIFF(MS, a.t_stamp, b.t_stamp))
) AS b
...
Correct, the OUTER APPLY is basically a type of LEFT JOIN, but it lets you reference columns from the other table too, which a JOIN doesn't, and we need to do that here, since we need to look at a.t_stamp when pulling from the b table.
If two entries happen to be the same time apart in opposite directions -- say minus 0.5 second and plus 0.5 second -- which one you will get will be random.
If you'd like to prefer one over the other -- minus or plus the same amount -- we can add that as well.
If you'd like to prefer one over the other -- minus or plus the same amount -- we can add that as well.
ASKER
Okay. that worked! I see what you mean about the indexing, though. The query took 13 seconds to execute -- and it was only looking at 3 days. The actual query will need to look at an entire MONTH! Yikes.
Yes. You'll need an index that directly supports the query.
You'll need an index on
dbo.C2_10_sec
on ( t_stamp ) INCLUDE ( MB_Eff_FlowC2 )
If you don't already have an index like that, let's add one and see how the response is then (you can never be sure whether SQL will use an index or not until you try it).
You'll need an index on
dbo.C2_10_sec
on ( t_stamp ) INCLUDE ( MB_Eff_FlowC2 )
If you don't already have an index like that, let's add one and see how the response is then (you can never be sure whether SQL will use an index or not until you try it).
CREATE NONCLUSTERED INDEX [C2_10_sec__IX_t_stamp] ON dbo.C2_10_sec ( t_stamp ) INCLUDE ( MB_Eff_FlowC2 ) WITH ( FILLFACTOR = 96, SORT_IN_TEMPDB = ON );
ASKER
Well, that reduced execution time from 13 seconds to 5 seconds. Is that what is expected, or does it indicate more needs to be done?
ASKER
I just ran the query on a single day. Returned 8,255 rows in 1 second.
That's about the best you can expect really, if you have to query it every time. Having to compute the ABS time difference is going to take some time.
You could add a column to table a that had the id (key) for the matching row in table b. A trigger -- or other code -- could maintain that value. Then the query itself would be able to do a join directly to the matching row, which should be very quick.
You could add a column to table a that had the id (key) for the matching row in table b. A trigger -- or other code -- could maintain that value. Then the query itself would be able to do a join directly to the matching row, which should be very quick.
>> I just ran the query on a single day. Returned 8,255 rows in 1 second. <<
Sounds pretty good to me!
Sounds pretty good to me!
ASKER
This is a long-standing problem I've had with this kind of data, so I'm definitely going to look at your idea of creating a reference table.
It will open up a lot of possibilities that I've tossed out in the past because of the trouble matching up the time stamps.
Thank you VERY much for the assist.
It will open up a lot of possibilities that I've tossed out in the past because of the trouble matching up the time stamps.
Thank you VERY much for the assist.
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
You're welcome!
I've done similar things many times at work here.
Column added to table a to contain the key column(s) could do it. You could use a separate reference table, but that will be somewhat more overhead.
I've done similar things many times at work here.
Column added to table a to contain the key column(s) could do it. You could use a separate reference table, but that will be somewhat more overhead.
ASKER
Just so I'm clear. if I need to reference any additional columns, the index needs to be ALTERED?
And, it looks like I'd just add any new columns to the INCLUDE section of the index query?
Also, how often does the index "run"? Or does it just get updated as new records are added once it's created?
And, it looks like I'd just add any new columns to the INCLUDE section of the index query?
Also, how often does the index "run"? Or does it just get updated as new records are added once it's created?
Correct.
Again, for overall performance of any table, what's critical is how it is clustered.
Those tables should be clustered first on t_stamp. If t_stamp is not unique by itself, then use an identity column to insure that the key is unique.
If you're not sure about what the indexes are, you can use this command to list them for us:
EXEC sys.sp_helpindex V4_Sensors
EXEC sys.sp_helpindex C2_10_sec
Again, for overall performance of any table, what's critical is how it is clustered.
Those tables should be clustered first on t_stamp. If t_stamp is not unique by itself, then use an identity column to insure that the key is unique.
If you're not sure about what the indexes are, you can use this command to list them for us:
EXEC sys.sp_helpindex V4_Sensors
EXEC sys.sp_helpindex C2_10_sec
ASKER
I gather these results are acceptable, based on your statement regarding t_stamp: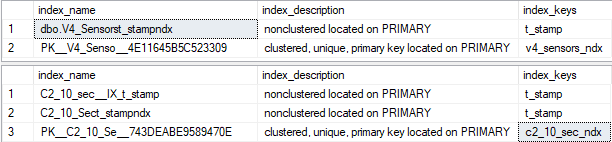
No. Nonclustered index does not have nearly the same effect.
What is column "%_ndx"? Is it an identity column? If so, the clustered index should be changed to
( t_stamp, v4_sensors_ndx /* or c2_10_sec_ndx */ )
The PK can still be on v4_sensors_ndx, we will just have to make it nonclus.
Naturally you'll need time to allow these commands to complete. The new clus index will likely have to rewrite all or most of the existing table. But you'll get much better overall performance for nearly all queries against the table.
DROP INDEX [dbo.V4_Sensorst_stampndx] ON dbo.V4_Sensors;
ALTER TABLE dbo.V4_Sensors DROP CONSTRAINT [PK__V4_Senso_4E11645B5C523309];
CREATE UNIQUE CLUSTERED INDEX [CL__V4_Sensors]
ON dbo.V4_Sensors ( t_stamp, v4_sensors_ndx )
WITH ( DATA_COMPRESSION = PAGE, /*or ROW or NONE, as you prefer*/
FILLFACTOR = 99 /*again, adjust if needed*/,
SORT_IN_TEMPDB = ON /*leave this as is!*/ );
ALTER TABLE dbo.V4_Sensors ADD CONSTRAINT [PK__V4_Sensors]
PRIMARY KEY NONCLUSTERED ( v4_sensors_ndx )
WITH ( DATA_COMPRESSION = ROW, FILLFACTOR = 99, SORT_IN_TEMPDB = ON );
And similarly for the other table. In fact, even more critical for that table, as that is the one referenced by the APPLY.
What is column "%_ndx"? Is it an identity column? If so, the clustered index should be changed to
( t_stamp, v4_sensors_ndx /* or c2_10_sec_ndx */ )
The PK can still be on v4_sensors_ndx, we will just have to make it nonclus.
Naturally you'll need time to allow these commands to complete. The new clus index will likely have to rewrite all or most of the existing table. But you'll get much better overall performance for nearly all queries against the table.
DROP INDEX [dbo.V4_Sensorst_stampndx] ON dbo.V4_Sensors;
ALTER TABLE dbo.V4_Sensors DROP CONSTRAINT [PK__V4_Senso_4E11645B5C523309];
CREATE UNIQUE CLUSTERED INDEX [CL__V4_Sensors]
ON dbo.V4_Sensors ( t_stamp, v4_sensors_ndx )
WITH ( DATA_COMPRESSION = PAGE, /*or ROW or NONE, as you prefer*/
FILLFACTOR = 99 /*again, adjust if needed*/,
SORT_IN_TEMPDB = ON /*leave this as is!*/ );
ALTER TABLE dbo.V4_Sensors ADD CONSTRAINT [PK__V4_Sensors]
PRIMARY KEY NONCLUSTERED ( v4_sensors_ndx )
WITH ( DATA_COMPRESSION = ROW, FILLFACTOR = 99, SORT_IN_TEMPDB = ON );
And similarly for the other table. In fact, even more critical for that table, as that is the one referenced by the APPLY.
ASKER
Scott -- before I go nuts and fire off that query, are there any risks I need to know about since I didn't create any of those indexes and don't have enough SQL knowledge to understand what you've put together?
Also, do I need to use that query to rebuild the indexes on ALL tables that are using _ndx as the identity column? If not, what am I looking for to know something's wrong? The tables are automatically created when I created a "transaction group" inside of the SCADA system I'm working with, so I don't know if that system is specifying anything related to the indexes or if it's just SQL defaults at work.
Also, do I need to use that query to rebuild the indexes on ALL tables that are using _ndx as the identity column? If not, what am I looking for to know something's wrong? The tables are automatically created when I created a "transaction group" inside of the SCADA system I'm working with, so I don't know if that system is specifying anything related to the indexes or if it's just SQL defaults at work.
SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
ASKER
Scott has forgotten more about SQL than I'll ever know.
Lol. I'm useless in the real world, just good with SQL Server.