Pau Lo
asked on
Evidence of capacity/performance management for vSphere architecture
At a practical level, what would be some examples that could demonstrate that IT network engineers are taking capacity and performance management of their virtual sever infrastructure environment seriously?
What actual evidence could be provided to demonstrate to management/risk departments, that your capacity/performance monitoring processes actually align with general good practice? For example, if this is high on your agenda and your area of responsibility, what specifically does (or should) the process involve on a daily/weekly/long term basis?
ASKER CERTIFIED SOLUTION
membership
This solution is only available to members.
To access this solution, you must be a member of Experts Exchange.
Alerting and collecting, because it also predicts how many days left, until X is out of capacity.
All our OP teams, also do 100 physical checks at each shift change 3 times a day.
1. snapshot alarm gone off ?
2. CPU Alert per VM
3. Memory alert per VM
4. CPU Host
5. Memory HOST
6. All are SNMP monitored
etc
This is evidence of management, also have a green, yellow, red for all services which manage e.g. Active Directory, Mail engines etc
ALL logs from everything are ingressed into Sumologic for single pain of glass view!
All our OP teams, also do 100 physical checks at each shift change 3 times a day.
1. snapshot alarm gone off ?
2. CPU Alert per VM
3. Memory alert per VM
4. CPU Host
5. Memory HOST
6. All are SNMP monitored
etc
This is evidence of management, also have a green, yellow, red for all services which manage e.g. Active Directory, Mail engines etc
ALL logs from everything are ingressed into Sumologic for single pain of glass view!
ASKER
Many thanks. Is the engineers checklist something you have defined internally, or at least partially based on any public checklists that you could recommend?
The internal checklist was developed over 24 years. I'm not aware of any public checklists but it's based on standard health checks, which any VMware vSphere Administrator should know about this causes performance issues.
e.g. VMs on snapshots, ISOs and Floppy images connected to VMs, VMs defined with Sockets and not cores etc
Some of the recommendations today feature in Skyline and Runecast Analyzer, like having an expert Appliance monitoring your estate and emailing you, using AI !
e.g. VMs on snapshots, ISOs and Floppy images connected to VMs, VMs defined with Sockets and not cores etc
Some of the recommendations today feature in Skyline and Runecast Analyzer, like having an expert Appliance monitoring your estate and emailing you, using AI !
RVTools might be an option also. https://www.robware.net/rvtools/
@Dale
RVTools will give you an inventory, but it will not give you any performance information, it can advise of snapshots or orphaned virtual disks.
Andy
RVTools will give you an inventory, but it will not give you any performance information, it can advise of snapshots or orphaned virtual disks.
Andy
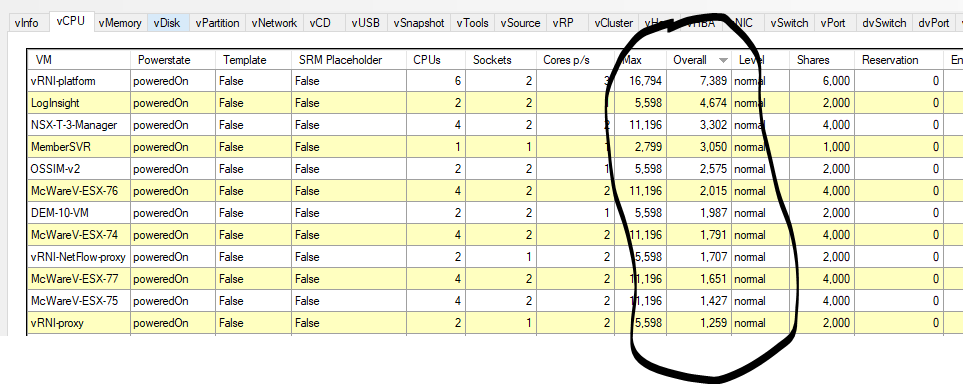
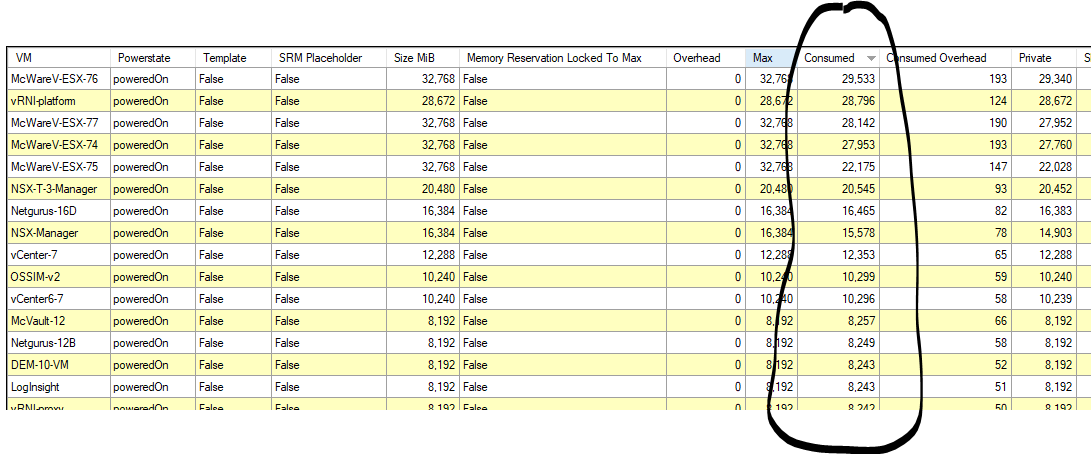
All exportable to CSV file
Not really real time! it's a point in time.
far better tools on the market, if you are serious about capacity management.
Skyline for FREE will do all this for you now, automatically.
If you don't have the Skyline appliance in your inventory you should it's FREE!
far better tools on the market, if you are serious about capacity management.
Skyline for FREE will do all this for you now, automatically.
If you don't have the Skyline appliance in your inventory you should it's FREE!
ASKER