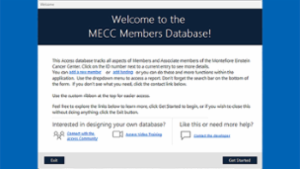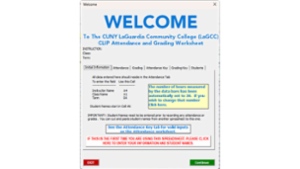
Creating a custom Welcome form in Excel
Not too long ago I wrote this article on doing the same thing in MS Access (https://www.experts-exchange.com/articles/38421/Making-your-Database-More-User-Friendly.html). I found that a similar "Welcome" screen makes Excel worksheets "friendlier" as well.