
![]() RAID
RAID
RAID stands for Redundant Array of Independent Disks. RAID is data storage technology that allows multiple drives to be used together as a singl...
Read more- 3.2K Content
- 1.7K Contributors
Expert Spotlight

Senior Technical Architect - HA/Compute/Storage

Philip is a Senior Technical Architect specializing in high availability solutions for SMB/SME businesses and hosting companies.
Leading Experts In



Troubleshooting Question
Troubleshooting Question
Can't load RAID 0 drivers in Windows Recovery Console. Any ideas?
Hi all,
Have a 12 year old Server, Dell PowerEdge T110 II, running Windows Small Business Server
Troubleshooting Question
Copy one of two volumes in a Hyper-V guest to faster medium which lacks capacity to copy both volumes
Have a 2022 Hyper-V guest with two volumes. There is a 300 gig C Drive and a 3 TB drive both are on
…
Troubleshooting Question
Starwind VSAN and HyperConverged offering?
Hi guys
Does anyone have any experience using Starwinds VSAN solution, or Hyper-converged appliance?
…
Troubleshooting Question
PowerEdge R720XS not seeing drives bigger then 2TB
We have a Dell PowerEdge Model R720XD with 192GB System Memory and a Dell PERC H710p Mini
…
Troubleshooting Question
Xyratex RS-1220 restore defaults
I have an old xyratex RS-1220 (Pre-owned).
I need to do a factory reset or restore defaults so I
…
Troubleshooting Question
Thoughts on backing up to LTO from one of two ESX hosts Veeam/VM
hi all
Working on replacing EOL Dual R730s that were configured with RAID 10, global hotspare,
…
Troubleshooting Question
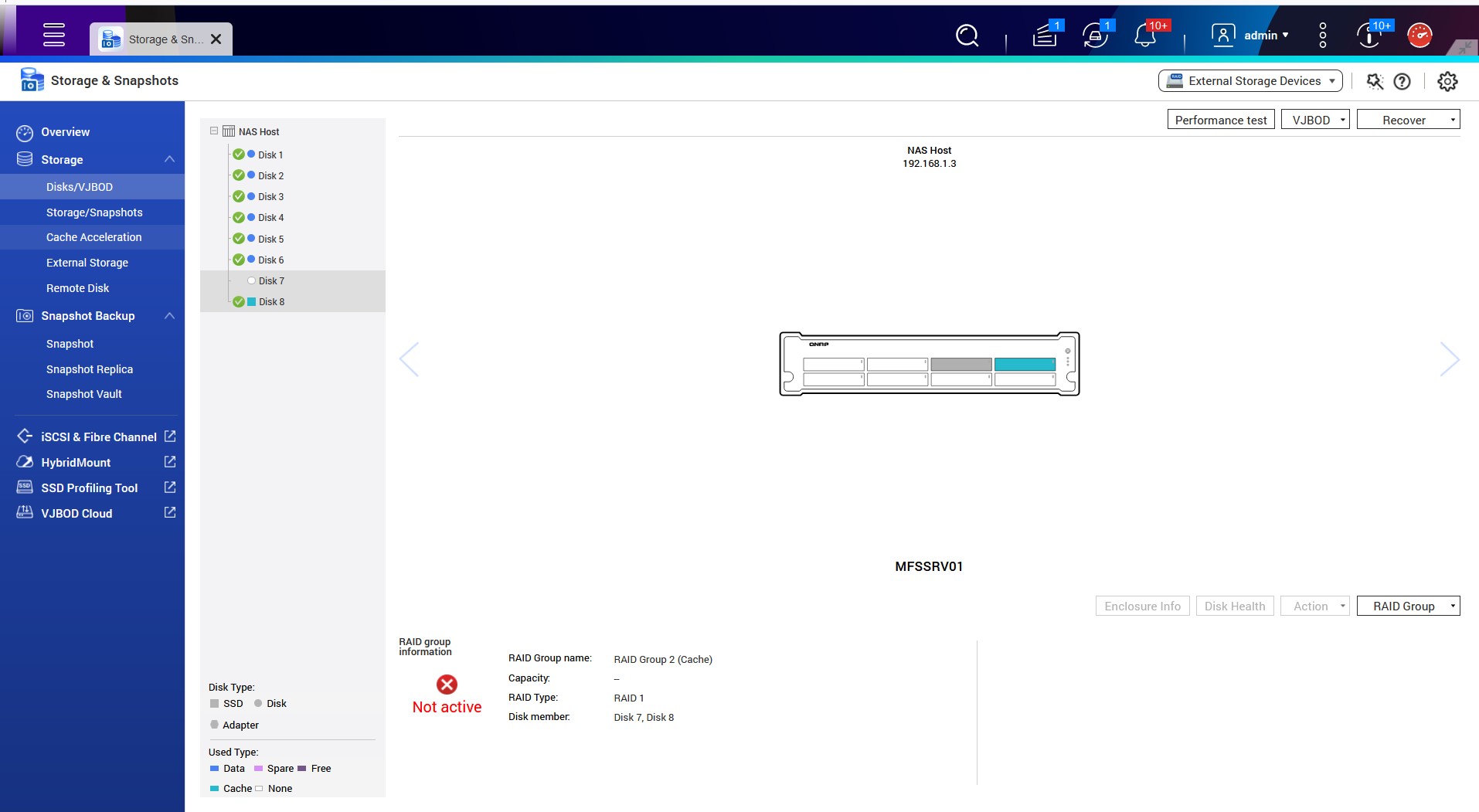
Strange Dell Poweredge RAID 5 Array Issue
We have a PowerEdge T340 with a H730P adapter and have an issue with a RAID5 array. I arrived on
…
Troubleshooting Question
Foreign State on Disks on Dell PERCH310 Mini COntroller
I have inherited a Dell Server PowerEdge R520. It looks like the PERC H310 Mini is having some
…
Advice Question
Rebooting after opening a rendering program
My build keeps rebooting; generally when opening any rendering program, including Windows Movie
…
Advice Question
Replaced disk on Dell PERC H730P not taking over from hot spare.
I have a Dell PERC H730P that's got into an odd state. Disk 12 developed an intermittent connection
…
Troubleshooting Question
Questions about Intel RAID "Temperature Sensor Differential Detected"
Intel RAID controller. RS25NB008. We are getting alerts like below:
Warning 3/26/2023 11:46:19 AM
…
Troubleshooting Question
Windows 11 22H2 LSI Raid Card 9266-8i upgrade issue
Hi ive been using this LSA Raid Card 9266-8i since Windows 10 without issue. Im on Windows 11 21H2
…
Troubleshooting Question
What could be the Problem for the Power down?
Hi
I use a Mac Studio M1 Max and a Lacie 5 big - USB-C and Apple original USB-c to Thunderbolt2
Advice Question
Hardware Recommendations For Virtual Server
Hi Experts,
Looking for hardware advice and recommendations please for a virtual server setup.
We have
…
Troubleshooting Question
Troubleshooting Question
Add entry to Grub to boot into Proxmox HDD in bay 4
Hello. I have an HP Microserver Gen 8 with 5 HDDs installed
Bay 1: Windows server 2019 (Raid 1 disk
…
Troubleshooting Question
Troubleshooting Question
RAID 1 HDD to SSD migration using imaging?
Hello Comunity,
I have a Dell T140 with spinning disks in RAID1 with windows server HyperVisor. I
…
Advice Question
Increase C Drive space on raid 5 server 2016
Hi
We have a Dellshipped / Configured PowerEdge T130 server on Server 2016 which is RAID 5.
As you
…Explore solutions and more





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![]() RAIDBack to the top
RAIDBack to the top
RAID stands for Redundant Array of Independent Disks. RAID is data storage technology that allows multiple drives to be used together as a single virtual drive for reasons such as fault tolerance, reliability and performance. There are several different levels of RAID that determine how the data is stored and the level of redundancy achieved across the drives.