Xpdf - PDFtoText - Convert PDF Files to Plain Text Files
Posted on
56,449 Points
5:01
 Joe Winograd
Joe Winograd
50+ years in computers
EE FELLOW 2017 — first ever recipient of Fellow award
MVE 2015,2016,2018
CERTIFIED GOLD EXPERT
DISTINGUISHED EXPERT
EE FELLOW 2017 — first ever recipient of Fellow award
MVE 2015,2016,2018
CERTIFIED GOLD EXPERT
DISTINGUISHED EXPERT
This third video of my Xpdf series discusses and demonstrates the PDFtoText utility, which converts PDF files into plain text files. It does this via a command line interface, making it suitable for use in batch files, programs, and scripts — any place where a command line call can be made.
You'll see that this video says it is "Part 3 of 3". However, after publishing the first three tutorials, I decided to do one for each of the other tools, as well as one for the Xpdf configuration file (xpdfrc). Links to all of the videos are in the first video in this series.
You'll see that this video says it is "Part 3 of 3". However, after publishing the first three tutorials, I decided to do one for each of the other tools, as well as one for the Xpdf configuration file (xpdfrc). Links to all of the videos are in the first video in this series.
Video Steps
1. Download and install the software.
You may have already downloaded and installed the Xpdf tools while watching the first or second video in the Xpdf series , but if you haven't, then visit the Xpdf website at:http://www.foolabs.com/xpdf/
Click the Download link and then click the pre-compiled Windows binary ZIP archive to download the Xpdf utilities for Windows.
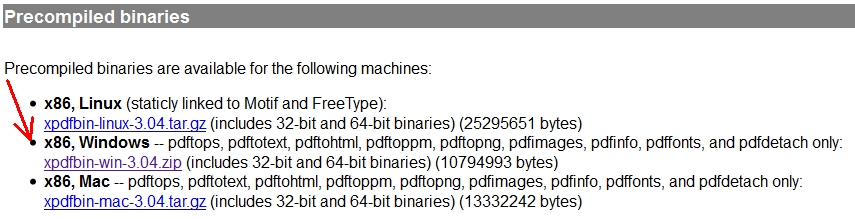
2. Locate the documentation folder for the Xpdf utilities.
Go to the folder where you unzipped the downloaded ZIP file and find the <doc> folder.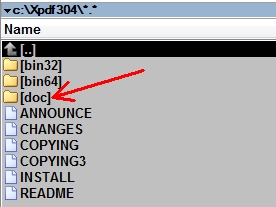
3. Read the documentation for the PDFtoText tool.
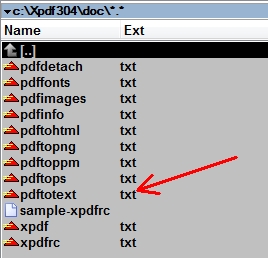
Go into the <doc> folder and find the plain text file called <pdftotext.txt>.Open it with any text editor, such as Notepad, and read it. This is the documentation for the PDFtoText tool.
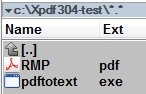
4. Set up a test folder.
Create a test folder.Copy <pdftotext.exe> from the unzipped <bin32> folder into your test folder.
Copy a sample PDF file into your test folder (in the video and the screenshots below, the file is called <RMP.pdf>).
5. Set up a command prompt for testing.
Open a command prompt window.Navigate to your test folder.
Issue a DIR command in the command prompt to be sure that only two files are in it - the PDFtoText executable and the sample PDF file.
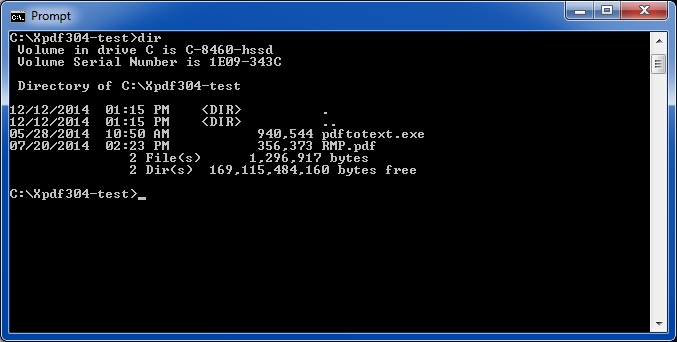
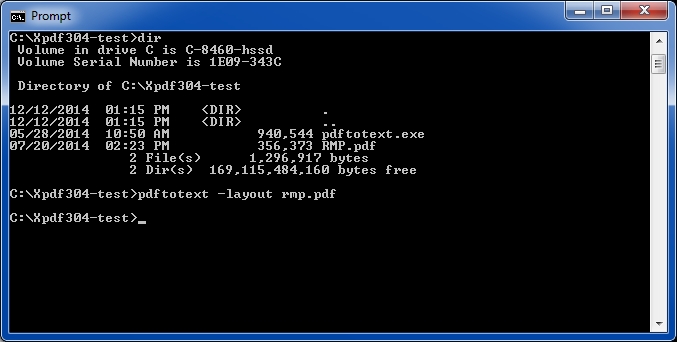
6. Run the PDFtoText utility on the sample PDF file.
In the command prompt window, enter the following command:pdftotext -layout samplefilename.pdf
7. Verify that the text file that was created.
Issue a DIR command in the command prompt to show that the text file was created. There should be one text file with the same file name as the PDF file, but with a file type of TXT.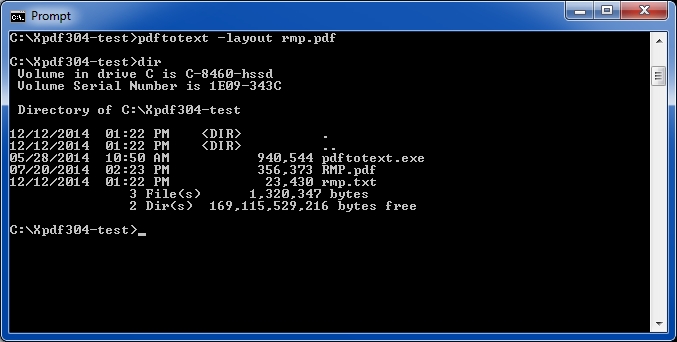
8. View the text file that was created.
Open the text file with whatever text editor you prefer, such as Notepad or WordPad.That's it! If you find this video to be helpful, please click the thumbs-up icon below. Thank you for watching!
-
6
 2
2
- +4


13 Comments
Active today
You're welcome, James. I'm glad you find it useful. And thanks to you for the comment — authors really appreciate hearing words like that! Regards, Joe
I have a file with bullets (see below). When I run 'pdftotext -layout -enc UTF-8' on this file, the bullets are turn into some weird character.
Is there a way to tell pdftotext to map these characters to '•' ?
• Provide electronic monitoring of the network, supporting devices and services, including
network devices, peripherals, switches, routers, servers and applications.
• Provide for the management and security of all ONR legacy network accounts.
• Monitor computer and network activity including system load, response time, available disk
Is there a way to tell pdftotext to map these characters to '•' ?
• Provide electronic monitoring of the network, supporting devices and services, including
network devices, peripherals, switches, routers, servers and applications.
• Provide for the management and security of all ONR legacy network accounts.
• Monitor computer and network activity including system load, response time, available disk
Active today
Hi Ed,
Thanks for joining Experts Exchange yesterday and watching my video — much appreciated! I'm very glad to hear that you think pdftotext is a great program — I'm in full agreement!
I'm guessing that the "weird character" that you're getting instead of the bullet ("•") is this:
•
Right? If so, that's happening because of the -enc UTF-8 parameter on your command line. You probably don't want UTF-8 encoding, unless you have characters that aren't part of the Latin1 character set, such as Chinese, Cyrillic, Eastern European, etc. In any case, the way to fix mapping problems is to create a custom xpdfrc file, which is the configuration file used by all of the Xpdf tools, and have it point to a corrected Unicode mapping file. The documentation for it is in a file called xpdfrc.txt in the doc subfolder of the unpacked download (and there's an example of it called sample-xpdfrc in the same doc subfolder). Here's the relevant section from the documentation, which is copyright 1996-2017 Glyph & Cog, LLC (with this small portion of it being copied here under "Fair Use"):
In your case, I suspect the character that's being mapped wrong is U+2022, so I would map that to extended ASCII character 149/x'95' in the Latin1 encoding. Attached is a modified Latin1 file for you. It contains the built-in Latin1 mappings, with my hyphen fix (U+2010 mapped to x'2D', a hyphen) and your bullet fix (U+2022 mapped to x'95', a bullet). It is attached as a .txt file. After downloading it, rename it to:
Latin1.unicodeMap
Then create a text file called customxpdfrc.txt with these two lines in it:
unicodeMap Latin1fixed "c:\folder\Latin1.unicodeM
textEncoding Latin1fixed
Of course, c:\folder\ may be wherever you want it.
Then run pdftotext with the -cfg parameter, such as:
pdftotext.exe -layout -cfg customxpdfrc.txt input.pdf output.txt
I tested it here on a PDF with a bullet and it worked fine, but, as always, YMMV, so please let me know if it does or doesn't fix it for you.
Btw, Xpdf's built-in Latin1 encoding maps U+2022 to x'B7', which the Windows Latin1 extended character set calls Middle Dot (aka Georgian Comma). I changed that to x'95' in the attached Latin1 file, but note that x'95' is not in the ISO-8859-1 (Latin-1) specification — it is in the Windows-1252 spec, i.e., code page 1252 (aka WinLatin1).
To give credit where credit is due, my thanks to Derek Noonburg of Glyph & Cog, who explained this method to me when I first ran into the hyphen issue.
Regards, Joe
Latin1.txt
Thanks for joining Experts Exchange yesterday and watching my video — much appreciated! I'm very glad to hear that you think pdftotext is a great program — I'm in full agreement!
I'm guessing that the "weird character" that you're getting instead of the bullet ("•") is this:
•
Right? If so, that's happening because of the -enc UTF-8 parameter on your command line. You probably don't want UTF-8 encoding, unless you have characters that aren't part of the Latin1 character set, such as Chinese, Cyrillic, Eastern European, etc. In any case, the way to fix mapping problems is to create a custom xpdfrc file, which is the configuration file used by all of the Xpdf tools, and have it point to a corrected Unicode mapping file. The documentation for it is in a file called xpdfrc.txt in the doc subfolder of the unpacked download (and there's an example of it called sample-xpdfrc in the same doc subfolder). Here's the relevant section from the documentation, which is copyright 1996-2017 Glyph & Cog, LLC (with this small portion of it being copied here under "Fair Use"):
unicodeMap encoding-name map-fileI've used this method to solve occasional problems, such as unusual Unicode hyphens. The technique is to create a xpdfrc file with the corrected mappings and then refer to that file in the pdftotext.exe call with the -cfg parameter.
Specifies the file with mapping from Unicode to encoding-name. These encodings are used for text output (see below). Each line of a unicodeMap file represents a range of one or more Unicode characters which maps linearly to a range in the output encoding:
in-start-hex in-end-hex out-start-hex
Entries for single characters can be abbreviated to:
in-hex out-hex
The in-start-hex and in-end-hex fields (or the single in-hex field) specify the Unicode range. The out-start-hex field (or the out-hex field) specifies the start of the output encoding range. The length of the out-start-hex (or out-hex) string determines the length of the output characters (e.g., UTF-8 uses different numbers of bytes to represent characters in different ranges). Entries must be given in increasing Unicode order. Only one file is allowed per encoding; the last specified file is used. The Latin1, ASCII7, Symbol, ZapfDingbats, UTF-8, and UCS-2 encodings are predefined.
In your case, I suspect the character that's being mapped wrong is U+2022, so I would map that to extended ASCII character 149/x'95' in the Latin1 encoding. Attached is a modified Latin1 file for you. It contains the built-in Latin1 mappings, with my hyphen fix (U+2010 mapped to x'2D', a hyphen) and your bullet fix (U+2022 mapped to x'95', a bullet). It is attached as a .txt file. After downloading it, rename it to:
Latin1.unicodeMap
Then create a text file called customxpdfrc.txt with these two lines in it:
unicodeMap Latin1fixed "c:\folder\Latin1.unicodeM
textEncoding Latin1fixed
Of course, c:\folder\ may be wherever you want it.
Then run pdftotext with the -cfg parameter, such as:
pdftotext.exe -layout -cfg customxpdfrc.txt input.pdf output.txt
I tested it here on a PDF with a bullet and it worked fine, but, as always, YMMV, so please let me know if it does or doesn't fix it for you.
Btw, Xpdf's built-in Latin1 encoding maps U+2022 to x'B7', which the Windows Latin1 extended character set calls Middle Dot (aka Georgian Comma). I changed that to x'95' in the attached Latin1 file, but note that x'95' is not in the ISO-8859-1 (Latin-1) specification — it is in the Windows-1252 spec, i.e., code page 1252 (aka WinLatin1).
To give credit where credit is due, my thanks to Derek Noonburg of Glyph & Cog, who explained this method to me when I first ran into the hyphen issue.
Regards, Joe
Latin1.txt
It works great for regular text
But i have a problem when exporting table inside pdf
especially when some cells in that table are empty (not contain number/text)
But i have a problem when exporting table inside pdf
especially when some cells in that table are empty (not contain number/text)
Active today
Hi Fammi,
Thanks for joining Experts Exchange today and watching my video Micro Tutorial — welcome aboard!
Two thoughts for you. First, my video talks about Version 3.04, which was the latest version at the time. There is now Version 4.00, which has some improvements and fixes in it. If you're on 3.04, I recommend upgrading to 4.00.
Second, have you tried the -table option? This is what it does (copied here from the doc file under "Fair Use"):
That doc refers to the -fixed option, which takes a number as its parameter and is described in the doc as follows ("Fair Use" again):
If those params don't help, please attach a sample PDF with the problem and I'll see what I can do with it (make sure the sample PDF has no private/sensitive information in it). Regards, Joe
Thanks for joining Experts Exchange today and watching my video Micro Tutorial — welcome aboard!
Two thoughts for you. First, my video talks about Version 3.04, which was the latest version at the time. There is now Version 4.00, which has some improvements and fixes in it. If you're on 3.04, I recommend upgrading to 4.00.
Second, have you tried the -table option? This is what it does (copied here from the doc file under "Fair Use"):
Table mode is similar to physical layout mode, but optimized for tabular data, with the goal of keeping rows and columns aligned (at the expense of inserting extra whitespace). If the -fixed option is given, character spacing within each line will be determined by the specified character pitch.
That doc refers to the -fixed option, which takes a number as its parameter and is described in the doc as follows ("Fair Use" again):
Specify the character pitch (character width), in points, for physical layout, table, or line printer mode. This is ignored in all other modes.
If those params don't help, please attach a sample PDF with the problem and I'll see what I can do with it (make sure the sample PDF has no private/sensitive information in it). Regards, Joe

i need to export text out of some pdf files written in Arabic. extracted text is a wrong encoding. what options should i use. I found a ready made configuration file for Arabic language, would you advise how may i use and customize it?
N.B. the pdf files were created using InDesign
N.B. the pdf files were created using InDesign
Active today
Hi Rami,
Thanks for joining Experts Exchange this week and watching my video. I normally respond to questions about my articles and videos on the same day or the next day, but it has been an extremely busy week for me, and I apologize for taking more than three days to get back to you.
I am not an expert in using the Xpdf utilities in any language other than English. So, my idea for you is based on general knowledge of the tools and their options, not on my personal experience with non-English languages.
PDFtoText has an option for encoding called -enc. The doc file for PDFtoText has this description for it (copied here under "Fair Use"):
The issue for you is almost surely that the default encoding is Latin1. For Arabic, you should use UTF-8 rather than Latin1. This is true for any language that has characters that aren't part of the Latin1 character set (e.g., Chinese, Cyrillic, Eastern European, etc.). Regards, Joe
Thanks for joining Experts Exchange this week and watching my video. I normally respond to questions about my articles and videos on the same day or the next day, but it has been an extremely busy week for me, and I apologize for taking more than three days to get back to you.
I am not an expert in using the Xpdf utilities in any language other than English. So, my idea for you is based on general knowledge of the tools and their options, not on my personal experience with non-English languages.
PDFtoText has an option for encoding called -enc. The doc file for PDFtoText has this description for it (copied here under "Fair Use"):
-enc encoding-nameNote the reference to xpdfrc, which is the configuration file for all of the Xpdf tools. I suggest reading the doc file on that, which, as shown in my numerous Xpdf video Micro Tutorials here at EE, is in the downloaded doc subfolder. In particular, look at the textEncoding parameter.
Sets the encoding to use for text output. The encoding-name must be defined with the unicodeMap command (see xpdfrc(5)). The encoding name is case-sensitive. This defaults to "Latin1" (which is a built-in encoding). [config file: textEncoding]
The issue for you is almost surely that the default encoding is Latin1. For Arabic, you should use UTF-8 rather than Latin1. This is true for any language that has characters that aren't part of the Latin1 character set (e.g., Chinese, Cyrillic, Eastern European, etc.). Regards, Joe

Active today
Hi Andrew,
I'm glad to hear that my Xpdf series will be useful for you. This particular one, PDFtoText, is the one that I use the most in my custom programs. Cheers, Joe
P.S. Thanks for the endorsement!
I'm glad to hear that my Xpdf series will be useful for you. This particular one, PDFtoText, is the one that I use the most in my custom programs. Cheers, Joe
P.S. Thanks for the endorsement!

Active today
Hi Joseph,
The PDFtoText utility must have as input a PDF with text already in it. If you have an image-only PDF, you must run OCR on it first before feeding it to PDFtoText. I have published some articles and five-minute video Micro Tutorials here at Experts Exchange showing how to perform OCR with various programs:
Articles
Batch Conversion of PDF, TIFF, and Other Image Formats via Command Line Interface to PDF, PDF Searchable, and TIFF with Power PDF Advanced
PaperPort - How To Create Searchable PDF Files
Videos
How to OCR pages in a PDF with free software - PDF-XChange Editor
Convert Scanned Image-Only PDF Files to PDF Searchable Image Files via OCR with Power PDF Advanced
There are, of course, many other programs that can perform OCR. Regards, Joe
Is there a way to get the output in HOCR format.No.
The PDFtoText utility must have as input a PDF with text already in it. If you have an image-only PDF, you must run OCR on it first before feeding it to PDFtoText. I have published some articles and five-minute video Micro Tutorials here at Experts Exchange showing how to perform OCR with various programs:
Articles
Batch Conversion of PDF, TIFF, and Other Image Formats via Command Line Interface to PDF, PDF Searchable, and TIFF with Power PDF Advanced
PaperPort - How To Create Searchable PDF Files
Videos
How to OCR pages in a PDF with free software - PDF-XChange Editor
Convert Scanned Image-Only PDF Files to PDF Searchable Image Files via OCR with Power PDF Advanced
There are, of course, many other programs that can perform OCR. Regards, Joe
Suggested Videos

A short article describing how you can quickly merge video clips which have the same encoding and resolution using freely available, open-source tools.

On January 16, 2024, Kofax changed its name to Tungsten Automation. On October 11, 2024, Tungsten released its first version of PaperPort — 14.8.0 — with Tungsten branding. This article explains how to upgrade from Kofax PaperPort Professional 14.x …
- Document Management
- Document Imaging
- Printers and Scanners
- Software
- Images and Photos
- PDF, Photos / Graphics Software, Windows OS, OCR, *PaperPort
Xpdf - Command Line Utility
Total Time: 14:57
Suggested Courses



Next Video:I Created a Reverse Shell in Excel